

4.3 Pathways to E-Learning in Science and BeyondThis section describes the National Science Digital Library (NSDL) and four related scientific digital libraries, alongside a complementary community of practice in e-learning, MERLOT (Multimedia Educational Resource for Learning and Online Teaching). These services are increasingly anchored and sustained by discipline-based entities as they move from a collection-driven approach to an emphasis on pathways to resources and community participation. Taken together, they serve the full spectrum of "K to gray" learners and educators. Over the past six years, NSDL has distributed an estimated $125 million dollars in funding to more than 200 projects. While the discussion below concentrates primarily on NSDL's function as an aggregator, harvesting digital resources for discovery via a unified search and retrieval interface, it is important to acknowledge from the outset NSDL's leading role in facilitating research collaboration and engaging stakeholders across public, private, university, K-12, and government sectors in strategic planning for the effective delivery of digital services. NSDL serves a crucial function at the national-level by re-thinking digital library architectures (Lagoze et al. 2005), developing and promoting best practices (http://oai-best.comm.nsdl.org/), creating generic tools and service applications (http://nsdl.org/resources_for/library_builders/tools.php), conducting research into user needs (California Digital Library 2004, Hanson and Carlson 2005), and advancing techniques in large-project management and participant involvement (Giersch et al. 2004). The SMETE Open Federation, launched with NSF NSDL Collection and Core Integration funding, includes among its membership more than forty organizations and digital libraries that share the common purpose of advancing digital libraries in science education. The other services discussed in this section are all members of SMETE. NEEDS, BEN, and DLESE are leaders in their respective communities-engineering, biological sciences, and earth science-in building effective digital library services. Although MERLOT's user community is multi-disciplinary, it is included in this section because of its prominent role in science education. It differs from most of the other services under review in this report in two important ways: (1) it is membership-based organization with a formal dues structure that dictates levels of participation and (2) it does not make its metadata freely available for OAI harvesting. MERLOT is particularly known for its peer-review practices and community-developing strategies. 4.3.1 NSDL: National Science Digital Library
Since its inception in 2000, the National Science Foundation's Directorate for Education and Human Resources (EHR) has made nearly 220 awards totaling more than $125 million dollars to develop the National Science Digital Library (NSDL). [[115]] The four major funding streams are defined as follows:
Source: NSDL 2005 annual report; Zia 2001-2005 in D-Lib Magazine & email correspondence, March 29-30, 2006. [[116]] NSDL's initial emphasis on Collections has shifted over the past two years to configuring and integrating digital resources into sustainable services by anchoring them in established communities of practice thereby "enabling learners to 'connect' or otherwise find pathways to resources appropriate to their needs" (Zia 2006). Collections' funding peaked in 2002 when there were 35 projects, accounting for 68 percent of the total NSDL budget. By 2005, NSDL funding was about equally distributed between Core Integration and the three project tracks, with Services receiving an estimated 28 percent and Pathways, 18 percent of new project funds. To date, Pathways are under development in the biological sciences, physics and astronomy, computational science, middle school teacher resources, materials science, mathematical sciences, engineering, multimedia resources for the classroom and professional development, and resources and services for community and technical colleges. [[117]] In FY06 proposals will be accepted for the Pathways track only or "for supplemental funding from existing projects to extend or enhance their services, collections, or targeted research activity so as to enlarge the user audience for NSDL or improve capability for the user." [[118]] Two projects under review in this report, BEN (BiosciEdNet) and SMETE/NEEDS are exemplars of NSDL Pathways. In addition, DLESE, funded by NSF's Directorate for the Geosciences, serves as an NSDL Earth Science node. NSDL's 2005 annual report [[119]] identifies five areas where it is concentrating its efforts to improve education, eaer audience for NSDL or improve capability for the user." [[118]] Two projects under review in this report, BEN (BiosciEdNet) and SMETE/NEEDS are exemplars of NSDL Pathways. In addition, DLESE, funded by NSF's Directorate for the Geosciences, serves as an NSDL Earth Science node. NSDL's 2005 annual report [[119]] identifies five areas where it is concentrating its efforts to improve education, each with representative project case studies:
Collections in NSDL According to NSDL's online collection policy, "NSDL is a collection of other digital library collections." Collections may consist of a single resource or thousands of resources. All NSDL resources are associated with at least one other external collection in order to associate them with a "responsible organization or project." Collections and resources are selected by NSDL Program-funded Pathways and Collections Projects and by the NSDL Director of Collection Development. In addition, collections and resources are recommended by a team of volunteer recommenders (mostly science librarians), NSDL community members, and also the general public. These recommendations are checked against the selection criteria and approved by the Director of Collection Development for inclusion in the NSDL. There are two broad selection criteria that are intended to be inclusive in order to allow a spectrum of quality and review:
NSDL collections contain freely available and restricted-use resources. When access is limited, the collection should have open access metadata describing the resources. As of May 2006, there are 660 collections accepted into NSDL of which 121 have item-level records. [[121]] Twenty NSDL collections account for 92 percent of the estimated 1.2 million item records. (Lagoze et al. 2006a report about their experience in harvesting from 114 NSDL collections via OAI; 37 collections come from only eight providers.) The top twenty data providers range in size from arXiv.org with nearly 340,000 items to DLESE with 7,200 items. The four largest collections also figure among the top twenty in OAIster: arXiv.org, the Office of Scientific and Technical Information (OSTI) OAI Repository, CITIDEL (the Computing & Information Technology Interactive Digital Educational Library), and Wolfram Functions. [[122]] Of the 88 collection projects funded via NSDL (representing 64 unique collections) from FY00 to FY03 an estimated 75 percent of them have item-level metadata in NSDL. On balance, NSDL-funded collections represent a very small portion of the NSDL content: CITIDEL with more than 100,000 records, followed in size by DLESE with 7,200 items-the remaining circa 46 NSDL-funded collections have 3,000 or fewer records. Publisher Partnerships in the NSDL [[123]] In its work over the past two years, the Core Integration (CI) team has proceeded from the premise that in order for the NSDL to become a resource of choice, used frequently by a broad range of teachers and students on a national scale, it is necessary to engage the interest and participation of the scientific textbook and software publishing community. This community includes both non-profit and for-profit organizations that control a substantial percentage of the high-quality educational science materials currently being produced for teachers and their students. In this effort, the CI team took steps to engage this community in a collaborative and productive manner, so as to ensure that the NSDL becomes a strong and valued partner rather than a competitor to the traditional science publishing community. Science publishers possess assets that will become critical to the future success of the NSDL, including an efficient and stable mechanism for acquiring and peer-reviewing high quality content from scientists and science teachers; an effective system for editorial development, design, and production of this content; excellent market research and evaluation mechanisms; established models for contracts, licenses, copyright, and intellectual property management; and a reliable system for marketing and sustainability. In addition, many of these publishers work with vendors who provide technical infrastructure and support for schools. Through its access management and publisher relations efforts, the CI team has established a formal means to engage the science publishing community, including a means to enable controlled access to their content. These activities will ensure that the NSDL reaches its full potential as a functional, valued, and highly used resource, and serves as a model for partnerships with other collaborators in the future. As of May 2006, NSDL CI has established relationships with 18 science publishers. Many of these have begun to supply metadata for their materials which then appears in the NSDL central portal interface. The publishers include:
Since the 2003, NSDL has developed access point to its content by audience: K12 Teachers, Librarians, NSDL Community, University Faculty, and First Time Users. Table 19 summarizes the widely varying results retrieved in a search for resources relevant to University Faculty about Astronomy. Browsing by topic identifies 68 collections relevant to Astronomy. A keyword search retrieves more than 11,000 resources. The University Faculty portal contains one "top pick" relevant to Astronomy. A search of the Virtual Reference Desk, AskNSDL question-and-answer archives and resources (requires registration and log-in) compiled by an NSDL reference desk librarian, locates 12 collections relevant to Astronomy (but the list does not include the Physics and Astronomy Pathway found through the University Faculty portal). In addition to blogs, Web sites and other types of resources, AskNSDL has 68 archived questions from users related to Astronomy.
Source: http://www.nsdl.org/ (February 2006) Given the diversity of these sample results, users should be encouraged to experiment with different search, browse and navigational functions to see which best suit their needs. Search Features In 2003, NSDL offered both simple and advanced search features. Simple search relied on keywords with the ability to limit by Type of Resource (Collections, Items, News, Exhibits, Collections with reviews, Items with reviews) or by Resource Format (Text, Image, Audio, Video, Interactive Resource, Data), whereas advanced searches allowed Boolean commands limited to keyword anywhere, keyword in content, title, author/creator/contributor, subject and format/genre. In response to user feedback, NSDL simplified its approach and now offers a single search box for keywords with the option to limit the search by Resource Format (same as above) or Grade Level (Graduate, College, High school, Intermediate elementary, Middle school, Primary elementary). In spring 2006 NSDL added an option to Search resources (i.e. educational resources) or Search NSDL.org (i.e. NSDL community sites or the NSDL.org site). As of this writing, these labels are under review and additional information describing the options will be added once approved.
Search Tips explain that searches are not case sensitive and that quotation marks should be used around phrases. Boolean commands are no longer available, nor is there any explanation whether or not there is automatic ANDing of search terms (a common feature of most general search engines) or truncation (or other wildcard functions). Results are returned ten per page with brief annotations and links to "View all related information" (provides item and collection-level metadata, as available) and "Include/Exclude results like this" (enables filtering by collection). Users can navigate to previous or next pages but cannot sort results or jump to different page results. When the revised Web site went live in late October 2005, a standard feature was added so all NSDL.org pages can be emailed via the "Email this page" link in the footer. However, there are no post-processing features to save or export results by other means. When a search does not produce any results, users are advised to consult the search tips, browse the collections, or check back as NSDL collections continue to grow. In March 2006, NSDL implemented "Did you mean" spelling suggestions. A search for "crystalography," suggests the corrected spelling, "Did you mean," crystallography. Search Results When conducted in late January 2006, a sample search for the keyword <crystallography> produced curious results (Table 20). Without deploying any search delimiters, the basic term query returned 633 results. Filtering the results to exclude the collection of the first retrieved item, reduced the result set to 616 resources. When the link "search within this collection" (e.g., DLESE) is used, the results increased dramatically to 7,175. Beginning anew with the search term, <crystallography,> but limiting by grade level, produced a wide range of results, with 20,373 hits at the high school level. [[124]] Given the proviso that not all resources contain format metadata and, therefore, relevant results may be excluded, it was alarming to retrieve much higher and wildly different returns when the format delimiter was invoked-e.g., over 700,000 texts and 34,000 images pertaining to crystallography, when the keyword search retrieves 633 resources. Based on Brogan's query of early February 2006, it became apparent that NSDL was combining all keyword appearances (i.e. through OR operators) rather requiring the presence of both words (i.e. through AND operators). NSDL modified its newly implemented search interface and corrected these errors on the production site in mid-February 2006. The results of the identical search conducted after the modification are dramatically different.
However, as NSDL officials explain, determining how "boosting and filtering" occurs is not entirely straightforward; in the many cases where the data provider or collection does not provide resource-type information in their metadata, relevant results may be lost from the search and the results are narrow. Even so there are still other problems apparent in this new sample search. The 12 results for Graduate-level resources contain three apparent duplicate references to Reciprocal Net. Users have to link to another screen to find out if all three are from the same source or not. Two seem identical (despite different NSDL OAI identifiers); the third is an article discussing Reciprocal Net that appeared in a NSDL Whiteboard report. Moreover, Reciprocal Net is tagged for three grade levels "graduate, undergraduate, grades 10-12" yet only shows up in the "Graduate" search. In early April 2006, NSDL reinstated the collection icons in search results pages allowing users to see the collection in which the resource resides, which helps to address some of these issues. NSDL's New Resource-Centric Fedora Architecture [[125]] NSDL's conversion to a Fedora repository marks a major transition from a metadata-centric to a resource-centric data model and search service. According to NSDL developers: Digital libraries need to distinguish themselves from web search engines in the manner that they add value to web resources. This added value consists of establishing context around those resources, enriching them with new information and relationships that express the usage patterns and knowledge of the library community. The digital library then becomes a context for information collaboration and accumulation - much more than just a place to find information and access it. (Lagoze et al. 2005)Finding the metadata-based model inadequate, the developers describe "an information network overlay within Fedora, which includes the full functionality of the existing metadata repository, but models relationships, services, and multiple information types within a web-service based application" (Lagoze et al. 2005). More recently, NSDL principals analyzed the many difficulties they have encountered over several years in relying on metadata to build the NSDL. They provide persuasive evidence for the new "resource-centric architecture that integrates less structured forms of information, which collectively add value and context to digital resources." As they explain: Traditional structured metadata plays a role in such information contextualization. However, it exists as a component of a resource-centric model, rather than being the focus of the information model itself. (Lagoze et al 2006a, 3)Their discussion goes beyond metadata quality to investigate other issues that add complexity and cost to operating a large-scale metadata aggregation site like the NSDL. For example, they reveal dismal harvesting statistics, citing an overall success rate of 64 percent and a monthly failure rate of 25 to 50 percent. They attribute harvest failures equally to three broad areas:
The new architecture is intended to model resources rather than metadata and permit the provision of richer information, including context and less-structured metadata. The infrastructure is also making possible a number of new NSDL applications described by Lagoze and his colleagues:
Sustaining NSDL Collections and Services Faced with the prospect of diminishing NSF funds, NSDL is increasingly turning its attention to strategies that will sustain its efforts and integrate them into established library services. NSDL's Sustainability Standing Committee Chair, Paul Arthur Berkman outlines four components of NSDL, each requiring its own strategies, if the NSDL is going to survive as a collaborative, coordinated effort where the sum is greater than its parts.
In 2004 NSDL began to publish "sustainability vignettes" in the Whiteboard Report for specified projects. The seven vignettes issued to date represent a range of multi-faceted approaches to continuation. [[127]] The Math Digital Library, for example, is creating new value-added services in close consultation with members of the Mathematical Association of America (MAA). According to MathDL's vision, new components-for example, MAA Reviews, Classroom Capsules, online MathDL books and meeting and workshop software-would be free to members but non-members would be required to subscribe or pay a usage fee. Similarly, MathDL's Journal of Online Mathematics and its Applications (JOMA) may transition to a member-only benefit, requiring others to pay for access. In brief, MathDL's sustainability plan hinges on a combination of support from MAA and from direct income streams. Another NSDL project, Teacher's Domain, sponsored by WBGH, is seeking "collaborative partnerships and strategic alliances," along with the expectation that its courses will become self-funded through licenses to educational institutions and organizations. The NSDL Sustainability Standing Committee is developing a decision-tree exercise, designed to help principal investigators determine if and how to sustain their NSDL projects. Alternative decision paths branch out from responses to questions about the project's sustainability objectives, its relevance, institutional support, and market opportunities-resulting in recommendations to discontinue the project as unsustainable or to consider open-source community, not-for-profit or for-profit corporation resolutions. Several other initiatives, addressing user-community and technical sustainability, merit discussion. Effective October 1, 2003, the California Digital Library (CDL) received a two-year NSF grant to develop and enrich the NSDL by determining how to best integrate it into academic library services. In an effort to support the development of NSDL's long-term business plan, the grant provided for a market assessment to determine user needs and expectations of high-quality science online resources. Through focus groups, interviews, and a comparative review of user-specified high-quality science resources (e.g., HighWire, Scirus, PubMed, CiteSeer), CDL market research revealed:
CDL's recommendations are annotated below with checkmarks to indicate areas of subsequent progress ("o" indicates not implemented as of mid-May 2006):
Other major services, for example Science.gov, are starting to integrate NSDL resources into their search capability.
Finally, the OCKHAM Initiative (described in section 3.2), led by Emory University and Oregon State University, aims to establish "an extensible framework for networked peer-to-peer interoperation among the NSDL and traditional libraries." To this end, it is developing a suite of tools (middleware) to help integrate NSDL collections and services into traditional library service environments while also creating a current awareness alerting service and a registry to facilitate machine-to-machine and end-user discovery of digital library services. This is vital to the future effective interoperation among existing NSDL collections. In addition, NSDL and DLF are working together to establish and promulgate Best Practices in Shareable Metadata as discussed earlier in this report. Leveraging Individual Project Activities and External Relationships This description of NSDL concentrates in large part on its Core Integration activities as an aggregator of STEM collections and services. NSDL, however, makes many other valuable contributions to advancing STEM teaching and learning by leveraging partnerships between individual projects and national partners. This is particularly evident in NSDL's involvement in the promoting educational achievement standards and professional development workshops. To cite one prominent example, the NSDL Achievement Standards Network (ASN), developed with NSDL funding by Jes & Co. (http://www.jesandco.org/), will provide hands-on learning standards systems for every state. The NSDL resource records are part of the State Educational Technology Directors Association (SETDA) 2006 Tool Kit (http://www.setda.org/content.cfm?SectionID=265), developed in conjunction with the U.S. Department of Education. The initiative includes tools, technologies and best practices that enable states to manage electronic versions of their academic standards, align resources and assessments consistently using open and interoperable methods, and embed standards seamlessly in all manner of learning and assessment systems and systems of accountability. 4.3.2 SMETE: Science, Mathematics, Engineering and Technology Education Digital Library
The SMETE Open Federation continues as a membership organization launched with NSF NSDL Collection and Core Integration funding whose "primary mission is to establish universal access to academic excellence in SMET education." The Federation has more than forty partners including the American Association for the Advancement of Science (AAAS), the Coalition of Networked Information (CNI), and OCLC as well as other digital libraries dedicated to science education (including all of the services under review in this section) and a dozen universities and corporations. SMETE helps to develop leading-edge technologies to share among its members while also maintaining a collection of premier learning materials. SMETE collaborated with the Exploratorium, in San Francisco, California, to create the Exploratorium Digital Library, a collection of high-quality teaching resources and activities (http://www.exploratorium.edu/educate/dl.html) that is also integrated into NSDL. SMETE has also provided technology services to other digital libraries including BioSciEdNet (BEN, http://www.biosciednet.org/portal/), MathDL (http://mathdl.maa.org/), and the Digital Chemistry (http://socrates.berkeley.edu/~kubinec/). SMETE resources are cataloged to meet the requirements of the IEEE Learning Object Metadata Standard and SMETE has developed tools to transform local application profiles (e.g., from LON-CAPA, http://www.lon-capa.org/ and the Michigan Teacher Network, http://mtn.merit.edu/) to normalized application profiles. SMETE collaborates with MERLOT on peer reviews. [[132]] In addition to supporting search queries by keyword, author/creator, title, and publication date range, the user interface offers various options to limit searches by more than 20 different types of learning resource (e.g., case study, dataset, lesson plan); grade level (primary education to post-graduate and vocational training to professional development); and eight specific collections (e.g., ACM Women in Computing, Math Forum, Michigan Teachers Network, NEEDS). Searches can be restricted to peer-reviewed materials. Search results are returned with briefly annotated entries including a search score. Each result is clearly branded according to its platform (e.g., PC, MAC, Web); cost (e.g., free or $); availability of reviews; and native collection. Registered users can create a profile and save resources in a workspace. User information can be shared to identify other community members with similar interests. The results' screen provides users with related terms to extend the search as well as the ability to conduct a federated keyword search in partner collections. The partner collections include NSDL, MERLOT, and NEEDS. A technical report available at SMETE explains its strategy for adopting a SOAP-based SMETE Search API to implement federated searches across heterogeneous collections. [[133]] 4.3.2.1 NEEDS: National Engineering Education Delivery SystemThe American Society for Engineering Education in partnership with seven leading engineering schools (e.g., UC-Berkeley, Worcester Polytechnic Institute, Colorado School of Mines) is creating a unified K-gray engineering pathway, under the auspices of NSDL. NEEDS, a digital library for engineering education, will merge with TeachEngineering (Resources for K-12) to establish a single comprehensive portal for engineering. Both NEEDS and TeachEngineering (TE) are highly regarded by their respective communities. Through its annual "Premier Award" courseware competition, NEEDS is a national leader in stimulating and evaluating high-quality engineering courseware targeted for undergraduate teaching. It has translated the award selection criteria into best practices in courseware design, helping to promulgate high standards of excellence. Through the combined expertise of NEEDS and TE, they expect to:
4.3.3 BioSciEdNet (BEN) Collaborative
In fall 2005 the BEN Collaborative, led by the American Association for the Advancement of Science (AAAS) with a dozen founding-partner professional societies, received NSF NSDL funding to expand into a Biological Sciences Pathway for educators at the high school and undergraduate levels. [[135]] Over a four year period, the Pathway funding will enable BEN to increase the number of: collaborators from which it aggregates resources from 13 to 22; digital libraries it helps professional society members to develop from 6 to 13; and cataloged resources in the BEN metadata repository from 4,000 to 27,000 items. With more than 100 professional organizations in the life sciences, BEN's core content aims to jump-start teaching introductory biology courses by unifying resources that are otherwise highly fragmented and widely dispersed. The Pathway builds on BEN's successful track record as a portal manager providing database development, resource cataloging, metadata validation software tools, and Web trend reporting for professional societies. BEN's Learning Object Management (LOM) cataloging system has seven components:
In addition to developing digital libraries with common technical standards that contribute resources to the BEN portal, BEN partners promote best practices for pedagogy, authentic assessment and the development of multidisciplinary biological sciences resources. A shared online workspace facilitates communication among collaborators. BEN relies on NSDL's technical architecture for integration of its resources into the NSDL Data Repository as well as access to NSDL's new applications (e.g., Expert Voices, Content Alignment Tool).
[[136]] To ensure quality control of learning object resources, BEN partner societies are expected to establish a peer review framework that specifies the review timeline, criteria, ranking, and types of reviewers involved in evaluating each type of resource. Examples of the peer-review processes created by its constituent professional societies are available from BEN's Web site. [[137]] While the number of BEN resources is relatively low at present, it is one of the few NSDL projects with a coherent cohort of peer-reviewed individually tagged lesson plans and classroom activities. As January 2006, BEN's inventory of 4,111 resources included:
In four years time, BEN expects to have established 45 college and university faculty representatives around the country who are trained to provide assistance to prospective BEN contributors and users. BEN operates under the aegis of a Coordinating Council that includes representatives from the AAAS and four professional societies as well as a national Advisory Board comprised of college and university educators. 4.3.4 DLESE: Digital Library for Earth System Education
Funded by NSF's Directorate for Geosciences, the DLESE Program Center (DPC) operates under the aegis of the University Corporation for Atmospheric Research (UCAR) in Boulder, Colorado. DLESE plays a leadership role in bridging the education and research components of geoscience cyberinfrastructure (Marlino et al 2004). The goals of the DLESE Program Center are to:
What are they seeking?
DLESE maintains two primary collections. Resources in the "DLESE Community Collection" (~7,100 items) meet basic guidelines in terms of subject relevance and functionality. [[143]] The more selective "DLESE Reviewed Collection" [[144]] is composed of resources (~670 items) that have been evaluated against seven criteria:
Users can browse DLESE's collections by subject, resource type, and grade level.
As illustrated in the figure above, each collection has a bar graph, charting the number of resources as well as a collection annotation and link to the collection's scope and policy statement. Text searches can be filtered by grade level, resource type, collection, and educational standard. At present, DLESE has the ability to search by National Science Education Standards (NSES) and by National Geography Standards (NGS). The National Geography Standards organize learning concepts under six broad topical categories: Environment and society, Human systems, Physical systems, Places and regions, the Uses of geography, and the World in spatial terms, for a total of 18 individual standards. The NSES are hierarchical and permit users to choose grade level, broad topic, and learning goal. For example:
DLESE makes innovative use of its "Community Review System" to create customized reports for teachers that assess the effectiveness of digital learning resources in their classrooms (Kastens and Holzman 2006). The Introductory Geoscience Virtual Textbook was created as a test bed for the CRS individualized teacher report system, utilizing DLESE resources to teach students about basic concepts in Earth science. [[147]] Both students and the instructor write reviews of the digital resources based on the seven criteria noted above for "reviewed resources" and then the DLESE CRS creates a report aggregating and comparing the data from the instructor's and student's perspective. Examples of various types of reports generated by the CRS are available at DLESE's Web site. [[148]]
Since the 2003 DLF report was issued, DLESE's information technology infrastructure has evolved into a service-oriented architecture (SOA), with improved interoperability capabilities that extend its reach through Web service and JavaScript APIs (Weatherley 2005) (see http://www.dlese.org/dds/services/). The Center for Ocean Science Education Excellence (COSEE, http://www.cosee.net/), for example, has embedded a custom DLESE search in their Web portal that is implemented using the DLESE Search Web Service and the My NASA Data portal utilizes a custom search page implemented with the JavaScript API (http://mynasadata.larc.nasa.gov/DLESE_search.html). In addition to these, DLESE services and APIs are being used to deliver DLESE resources interactively to users of GLOBE, NASA S'COOL, the GEON portal and several other institutional Web sites and portals. The California Digital Library is harvesting DLESE's OAI records and integrating them into a geosciences portal tailored to the users of the UC campus libraries. DLESE is also a Principal Investigator (PI) Institution in GEON, a network building cyberinfrastructure capacity in geoinformatics for research (GEON) and educational (DLESE) purposes. GEON is based on a service-oriented architecture (SOA) with support for "intelligent" search, semantic data integration, visualization of 4D scientific datasets, and access to high performance computing platforms for data analysis and model execution -- via the GEON Portal. http://www.geongrid.org/GEON and DLESE interoperate in a number of important ways (Wright 2004). GEON uses the ADN Metadata Framework, (jointly developed by the Alexandria Digital Library, the NASA Science Mission Directorate and DLESE) [[149]] and the two services share collection records. GEON Web services and content are available in DLESE (http://geon01.dlese.org/) and the GEON Portal provides access to DLESE. GEON, DLESE, and the University of Colorado are collaborating to create an "Educational Knowledge Organization System" (EKOS) that supports conceptual browsing (concept strand maps) to align learning outcomes and educational standards with DLESE's resources (Wright 2004, Sumner et al. 2004). [[150]]
Custard and Sumner (2005) report on their research to "Using Machine Learning to Support Quality Judgments" about digital resources and collections. NSDL and DLESE were used as a test case for their research to determine if a set of "indicators could be used to accurately classify resources into different quality bands and to determine which indicators positively or negatively influenced resource classification." According to the authors, "The results suggest that resources can be automatically classified into quality bands, and that focusing on a subset of the identified indicators can increase classification accuracy." In the future, collection curators may rely on these "next generation cognitive tools" to support their qualitative decisions about which digital resources to acquire. Publications and presentations by members of the DLESE community are listed in the bibliography maintained at the DLESE Web site. [[151]] 4.3.5 MERLOT: Multimedia Educational Resource for Learning and Online Teaching
Those new to MERLOT have several options to familiarize themselves with its services and features. From MERLOT's Web site, users can access a brief video introduction (replete with faculty testimonials), listen to a presentation about MERLOT co-sponsored by the TLT Group, watch an interview with MERLOT's Executive Director, Gerry Hanley, or listen to his longer video presentation, "Sharing Learning Objects: Serving MERLOT to Higher Education." [[153]] In summarizing what makes MERLOT work effectively, Hanley emphasizes these characteristics:
Since 2003, MERLOT has expanded its international outreach and content through strategic alliances in Canada, Europe and Australia. CLOE, the Co-operative Learning Object Exchange led by the University of Waterloo (Ontario, Canada) is now a major sustaining partner alongside the California State University. The ARIADNE Foundation for the European Knowledge Pool, a distributed network of learning repositories, has become a MERLOT partner. In addition, MERLOT, ADRIADNE and EdNA, the Education Network Australia of learning repositories, each offer federated searches across their collections individually or collectively. [[156]] They are also all members of the consortium, GLOBE (Global Learning Objects Brokered Exchange), along with eduSourceCanada and the National Institute of Multimedia Education (NIME) in Japan. [[157]] MERLOT has also strengthened its corporate partnerships, which include O'Reilly Media and Sun Microsystems, three learning management systems (ANGEL Learning, Blackboard/WebCT, Desire2Learn) and two library systems (Ex Libris Ltd. and Sentient Learning). [[158]] These partnerships result in mutually beneficial services such as the seamless integration of MERLOT resources via Blackboard and ANGEL. [[159]] A similar service with WebCT will be available in July, 2006. As a matter of principle, MERLOT only signs non-exclusive agreements with vendors. It has assigned different values to its functions as follows:
In July 2005, MERLOT inaugurated JOLT: Journal of Online Learning and Teaching as a peer-review, open access vehicle to promote the scholarship of technology-enabled teaching and learning in higher education. JOLT serves as another forum in which the MERLOT community can express and examine issues of common concern. MERLOT offers various avenues for users to keep abreast of recent developments besides its "What's new" page, quarterly email newsletter the Grapevine, and press releases. It supports syndication (RSS), and from the home page, users can quickly link to the most recently added resources (225 items), new member profiles (845), and peer-reviewed resources (26) contributed in the last thirty days. MERLOT's basic user interface is the same as reported in 2003, but there a number of new or previously unrecorded features. The Advanced search functions permit users to limit their queries by a number of unique qualifiers going well beyond subject, material type, technical format, language, audience and cost. These include: learning management system compatibility (Blackboard/WebCT, Desire2Learn), iPod items, Section 508 compliant items (conform to minimal disability access standards), copyright restrictions, and availability of source code. In addition searches can be restricted to peer-reviewed resources (further refined by minimum rankings), member comments (further refined by user rankings), availability of assignments, and author snapshots. Author snapshots utilize the KEEP Toolkit developed by the Carnegie Foundation for the Advancement of Teaching to produce an illustrated synopsis (e-portfolio) of the educator's rationale, motivation, and impact on teaching and learning in developing the resource. It is worth noting that some of these filters restrict the results to a very limited sub-set. For example, whereas 85 to 90 percent of the resources have been reviewed by faculty, only about 15 percent actually have published "peer reviews" in MERLOT (<2,000 items). [[160]] According to MERLOT representatives the comparatively low proportion of peer-reviewed resources is attributable to a combination of factors including the amount of time required by faculty, the author's consent, and the quality of the material. Consequently, resources deemed of lesser interest do not receive MERLOT Peer Review. Results can be sorted by five different variables (title, author, date entered, rating, item type). It is possible to conduct sub-searches within the result set.
In addition to federated searches across ARIADNE and EdNA's learning object repositories, MERLOT offers two subject-based federated searches: physics (covering MERLOT Physics and ComPADRE-Digital Resource Collections for Physics and Astronomy Education developed as a NSDL Pathway) and teaching and technology (covering MERLOT resources and the University of Carolina's Professional Development Portal). Currently in test is a federated search from the MERLOT Information Technology portal into IEEE Computer Society's extensive digital library (http://www.computer.org/). A new version of the MERLOT Web site is currently under development and planned for release at the MERLOT International Conference in August, 2006. 4.3.6 Current Issues and Future DirectionsEach in their own way, these services face organizational challenges to increase content and usage. NSDL is developing "pathways"-exemplified by NEEDS and BEN-to focus resources for particular audiences and coalesce services across sectors. NEEDS is merging with TeachEngineering to serve the full spectrum of K-12 to lifelong learners. BEN has excelled at developing models for transforming smaller organizations to become contributors to digital libraries. DLESE is developing tools to support distributed cataloging of multiple collections and different metadata frameworks. MERLOT is bringing in new international and corporate partners. This cohort has developed a number of effective marketing and outreach vehicles to secure and extend their user base:
An essential ingredient to their success is offering quality assurance of content, one aspect of which is peer review. The user interfaces of SMETE/NEEDS, DLESE and MERLOT support filters to peer-reviewed items. However the actual proportion of such items is relatively low. A search limited to peer-review resources returns only 25 results in SMETE or NEEDS. Less than 15 percent of MERLOT's are peer-reviewed, whereas only 700 of DLESE's 12,000 resources are part of its reviewed collection. Although BEN has made considerable gains (310 percent increase since 2003), peer-reviewed resources constitute less than 15 percent of its database as well. This suggests that peer-review in the digital realm is still at an early stage of acceptance and is not well-integrated into faculty traditions and reward systems. According to an NSDL study underway by Alan Wolf, "The science faculty that he studies claim to trust neither peer review nor community vetting; instead, they simply rely on their own personal judgment in every case of using an OER [online educational resource], or they consult with a trusted colleague" (Harley et al. 2006, 166) [[161]]. These services also face the challenge of meeting the diverse needs of an expanded user base, particularly those that attempt to span the K to grey clientele. Research studies sponsored by NSDL among others reveal considerable differences by education sector in terms of what teachers need to integrate digital resources into their pedagogy California Digital Library 2004, Hanson and Carlson 2005, Harley et al. 2006). NSDL's pathways are intended to target resources and services to particular audiences, but it remains to be seen if these services can effectively serve diverse and sizeable constituents which have widely varying needs and operate in different conditions. NSDL, in particular, notes the "great diversity in evaluation methods and tools across 190+ NSDL digital library projects." This is corroborated by the CSHE study which reports that six NSDL collections included in their review "used almost completely different metrics to describe themselves and their use" (Harley et al. 2006, 157). While these services are making strides to integrate their resources into other services (e.g., NSDL's incorporation into academic library portals and science.gov; MERLOT's federated search system and partnerships with WebCT/Blackboard; DLESE's partnership with GEONgrid), it remains to be seen how they will join up with other national and international communities of practice formed around e-learning technology platforms and e-learning frameworks. How do their efforts mesh, for example, with international efforts to make content object repositories interoperable such as CORDRA (Content Object Repository Discovery and Registration/Resolution Architecture, http://cordra.net/) or the IMS Global Learning Consortium (http://www.imsglobal.org/) (Kraan and Mason 2005)? Finally, financial sustainability is a major challenge, cited particularly by NSDL and MERLOT, but also evident in responses from the other services. Through the efforts of its Sustainability Standing Committee, NSDL is tackling this issue by formulating a decision-tree and providing its constituent projects with information about establishing marketing and business plans; however, NSDL as a whole-like other services in this report-attest to the need for more public and private funding options. The California Digital Library's market assessment of NSDL suggests that "academic libraries see limited value in another Web science portal, but would be willing to consider paying for deep integration with their existing search tools" (California Digital Library 2004, 3). Even MERLOT, which has a fee-based membership structure, identifies the challenge of "high demand, but limited resources." Nor can MERLOT count on maintaining its current membership base. The CSHE study of "Use and Users of Digital Resources" notes that while MERLOT (alongside a handful of other services) "could function on an existing base of support, budgetary volatility encouraged them to continuously watch for new funding opportunities" (Harley et al. 2006, 147). 4.4 Joining Forces: Cultural Heritage and Humanities ScholarshipAt present, we have the opportunity to reintegrate the cultural record, connecting its disparate parts and making the resulting whole available to one and all, over the network. . . . Like most grand challenges, this one can be simply stated: make it possible for people to explore the totality of our accumulated global cultural heritage, now scattered throughout libraries, archives, or museums. ACLS, Cyberinfrastructure in the Humanities & Social Sciences, 2005 The eleven services under review in this section serve as exemplars of ways in which librarians, archivists, educators, and scholars are collaborating to build digital collections and tools in support of cultural heritage and humanities scholarship. The discussion begins with two services that bridge the cultural divide by presenting collections and content from libraries, museums, and archives in a unified way. Cornucopia, sponsored by the Museums, Archives & Libraries Council (UK), serves as a single point of access for resource discovery, based on 6,000 collection-level descriptions from 2,000 institutions in the UK. Since the 2003 DLF report appeared, Cornucopia began to make its collection metadata available via OAI and SOAP. Further, it served as a model for a new project in the US led by the University of Illinois, namely the IMLS Collections and Content gateway to digital projects funded by the IMLS National Leadership Grant Program. The Institute of Museum and Library Services (IMLS) is an independent grant-making agency of the federal government whose mission is "to lead the effort to create and sustain a 'nation of learners'" (http://www.imls.gov/). Both projects use the RSLP (Research Support Libraries Programme) Collection Level Description (CLD) Metadata Schema which enables consistently formatted descriptions to be created and linked through parent-child relations and association relationships (as depicted in Figure 32), building on entity relation models for collection descriptions (Healey 2000, 2005) [[162]]. In addition, these projects are informed by NISO's (National Information Standards Organization) "A Framework of Guidance for Building Good Digital Collections" (2nd edition, 2004) and the NISO Metadata Initiative, described in the next section of this report. [[163]] The DLF's Digital Collections Registry, which is maintained also by the University of Illinois, is briefly described before turning to three services included in the 2003 DLF survey: the Library of Congress's American Memory, the Sheet Music Consortium, and the Collaborative Digitization Program's (formerly Colorado Digitization Program) Heritage West (formerly Heritage Colorado). These represent various models of fostering cooperative digital collections and aggregating at the international, national, and regional level. Two pilot projects-The American West and DLF Aquifer-sponsored by the California Digital Library and the Digital Library Federation respectively, are starting to put into practice many of the lessons learned from previous collaborative projects. They are pooling digital content and building tools and services targeted to particular audiences. Meanwhile, Emory University's capstone initiative, SouthComb, leverages its prior digital initiatives including AmericanSouth covered in the 2003 DLF survey, to create a scholarly portal for Southern Studies. Two scholar-driven projects round out this section. Since 2003, the Perseus Digital Library (PDL) has rebuilt its text system, released a new Web site, and launched a named entity browser. It plans to migrate its core data to the Tufts Institutional Repository in order to concentrate on research and development activities. Once PDL research applications prove viable, they will move to the IR's production server. Finally, NINES (Networked Interface for Nineteenth-Century Electronic Scholarship) represents a new scholar-driven model of aggregating peer-reviewed work and presenting it for use along with a suite of interpretative digital tools. Led by Jerome McGann, the John Stewart Bryan University Professor at the University of Virginia and editor of the acclaimed Rossetti Archive, NINES has garnered endorsements from five disciplinary societies and a host of other influential humanities computing organizations and projects. 4.4.1 Cornucopia
Developed by the Museums, Libraries and Archives Council (MLA), Cornucopia is a searchable database of some 6,000 collection descriptions emanating from 2,000 cultural heritage institutions in the UK. In spring 2004 Cornucopia migrated to a new software system and realigned almost all of its data structure to conform to the RSLP (Research Support Libraries Programme) Collection Level Description Metadata Schema (Turner 2005). The new system enhanced Cornucopia's functionality. Contributors can now edit and enter their collection data through a Web-based direct entry client; moreover, Cornucopia's data became available for OAI harvesting and Web service access. This enables interoperability among cultural heritage sites in the UK. For example, the People's Network Discover Service (http://www.peoplesnetwork.gov.uk/discover/) is harvesting Cornucopia data and making it searchable as one component of an aggregation harvested from an increasing number of cultural heritage sources. MLA's longer term vision is to provide integrated access to a wide range of data from the cultural sector, in which Cornucopia figures prominently. As Cornucopia expands to incorporate more heterogeneous resources from an expanded institutional (e.g., including many more library collections) and user base, UKOLN undertook a strategic review of indexing options. A series of reports issued in September 2005 and January 2006 present comparative analyses of alternative thesauri, name authority files, and controlled vocabularies; recommend preferred indexing conventions for Cornucopia; and outline action plans for implementation. Among the key recommendations are to use the UK Archival Thesaurus (UKAT) for subject indexing and to abandon Cornucopia's current place indexing and use certain sections of the UNESCO Thesaurus instead. The time browsing page will be overhauled and new audience values and collection strength information added. New "Contributor Guidelines" give examples of how to assign appropriate index terms for subjects, places, time periods, names, audience levels, and collection strength based on UKOLN's findings. [163b] Cornucopia's search and retrieval features have improved since 2003; however, in view of the new indexing recommendations, the description of its current functionality is provisional. Collections can be browsed by seven categories: time, people, place, subject, culture (e.g., Ancient Greece, Jewish, Maya, Viking), and institution. The user interface supports hierarchical, faceted browsing by subject. There are 21 broad subject categories (e.g., Education, Events, Information and Communication). In advanced search mode, users can narrow a collection title search by time period, place, type of institution (library, archive, or museum), or county. Alternative keywords are suggested to expand the search, based on the UK Archival Thesaurus. Results are returned with brief annotations, and link to full records that include (a) a collection summary, (b) location details (directory information about the institution), and (c) additional collection information; in some instances, there are links to the item via the institution's catalog. The "collect me" feature allows users to gather and save search results during a session for printing or emailing. In addition, users can perform a search by postal code to locate collections in a particular location or conduct a search within or across three other Web services, including Cecilia: Find Music Collections in the UK and Ireland; Darwin Country; and Google. At present, no explanations are given to users about the coverage of the other services. However, Cecilia is a database of some 1,800 collection descriptions of music resources held in 600 libraries, archives and museums in the UK and Ireland (http://www.cecilia-uk.org/). Darwin Country, a partnership of several regional museums, focuses on the history of science, technology and culture in the West Midlands during the 18th and 19th centuries; it is affiliated with the UK's "Curriculum Online" initiative. [[164]] Among other features, Darwin Country enables the exploration of artifacts consisting of nearly 12,500 historic images (http://www.darwincountry.org/). Besides Cecilia, various other digital projects in the UK have chosen to use Cornucopia's software and will provide their own user interfaces. They include:
4.4.2 IMLS Digital Collections & Content (DCC)
A collaborative initiative led by the University of Illinois, Urbana-Champaign (UIUC) Library and Graduate School of Library & Information Science, this gateway is intended to bring greater visibility and utility to digital collections funded by the IMLS (Institute of Museum and Library Services). The DCC serves as both a registry of collection-level descriptions of National Leadership Grant (NLG) projects and a metadata repository of item-level records from a subset of these collections. In its next phase of development (funded through 2007), the DCC expects to add a sample of digital collections funded via IMLS to State Library Administrative Agencies in support of the Library Services Technology Act (LSTA). Integral to the development of the DCC, the principal investigators are testing the assumptions of the NISO/IMLS Framework of Guidance for Building Good Digital Collections (2004), namely how the registry and repository might serve as "infrastructure components" with "the potential to facilitate the reuse of digital content in new and different ways - by enabling more effective search and discovery across multiple collections and among and between individual information objects that will allow communities of scholarly interest to view an information landscape as best meets their needs" (Cole and Shreeves 2004, 309). Specifically, the DCC experiments with OAI-PMH interoperability best practices in terms of collection identity, metadata normalization and enrichment for specific audiences, and portal interface and functional design issues (Cole 2006). In creating the collection registry model, the DCC draws on research about how to define and describe collections, ultimately opting to adapt the RSLP Collection Description Schema and the Dublin Core Collection Description Application Profile [[165]] (Cole and Shreeves 2004, 312). Taking into consideration similar projects, in which Cornucopia figured prominently, the DCC arrived at a collection description metadata schema with four classes of entities:
A collection may have been created by multiple NLG projects and have multiple administrators. A collection may only have one hosting institution, but may have multiple contributing institutions. A collection may have multiple sub-collections, complementary collections, or source physical collections. A NLG project may have only one administering institution, but may have multiple participating (or collaborating) institutions.
A second major component of the project involves enabling cross-collection searching of item-level metadata using OAI-PMH to facilitate interoperability. To this end, the DCC deployed several strategies to help participating collections become OAI data providers including implementing an OAI Static Repository for some projects, and working with CONTENTdm, (already in use by other projects), to support "resumption tokens" that help to control the flow of records in manageable chunks to the DCC. As result, more collections are able to contribute item-level records to the DCC. Nevertheless as of this writing, only about half of the collections have associated item-level records. Noting that the absence of item-level metadata is particularly prevalent for exhibit and learning object focused projects, Cole and Shreeves offer other reasons why NLG projects are not yet OAI-compliant:
Over the next two years, the principal investigators expect to integrate collection-level and item-level services as well as customize the interface and metadata design for targeted audiences. At present, the DCC offers two distinct services with separate interfaces: the IMLS DCC Collection Registry and the IMLS Digital Content Gateway. As of January 2006, the registry represents 158 IMLS NLG projects as manifest in 108 primary NLG collection records with 40 additional sub-collection records and 29 associated collections (Cole 2006). Collections are classified according to the Gateway to Educational Materials (GEM) subject schema. As evident from Table 22 below, most collections are assigned more than one subject and contain multiple types of objects. At one extreme, Infomine is assigned to all subjects except Educational Technology and Physical Education. It is also the sole resource classified as Philosophy and all of its sub-categories-Aesthetics, Epistemology, Existentialism, Marxism, and Phenomenology as well as all seven sub-categories of Mathematics.
The GEM's classification scheme seems out-of-balance with the subject coverage of the collections in the current deployment of the registry. Around 80 per cent of the collections are classified under "Social Studies" and within this, 104 (or 65 per cent of all collections) are "United States History." In addition to browsing by subject, users can browse by Object, Place, Title, National Leadership Grant project, and Host Institution. The majority of the collections contain multiple types of images (233) and texts (202). Within these categories, it comes as no surprise that photographs, slides and negatives (105 collections) and books and pamphlets (66 collections) dominate. The registry supports basic and advanced searches. In advanced search mode, users can limit their queries to eight different object types (as noted above). Each entry is linked to the collection's home page, an extensive record about the collection, information about related collections and an annotation about the corresponding NLG project. Users can link to the Collections Gateway via the "Home" button at the bottom of the screen. (There is no straightforward means to toggle back and forth between the registry and the gateway.) The gateway site supports fielded searches-by Title/Subject/Description, Author/Artist/Creator, Type, Date, and Publisher-deploying basic Boolean operators (AND, OR, NOT) and queries can be limited to all or selected collections (available via a drop-down menu). At present there are 32 collections with item-level records including two that have multiple sub-sets-Heritage Colorado (now Heritage West as discussed in this report) with 22 sub-sets and Museums & the Online Archive of California (MOAC) with 31 sub-sets-for a total of 85 collections altogether. Users may choose to have results returned in order of relevance. Users can also specify their preference to display all records in short form on one page (up to a maximum of 500); otherwise twenty results are displayed per page. Each entry is linked to its host identifier; users can view the complete metadata record or add results to a Book Bag and save them (in XML) to a disk. In the left-hand frame of the screen, the search results are summarized according to the collection (and sub-set) to which they are attached. Users can modify or review their search history.
As evident from the table below comparing browsing and searching within and across the registry and gateway, the same query is likely to retrieve different results. In the three examples below, only <human sexuality> retrieves the same collections when using the browse and search features of the registry. However, it returns no hits in the content gateway (HEARTH does not make item-level metadata available). Meanwhile in the case of <dance>, only two collections-the ubiquitous Infomine along with Folkstreams.net-are classified with this GEM subject in the registry, but a search of collections in the registry retrieves a third collection pertaining to the subject, Masterworks Online. Despite its smaller universe of collections, searching the gateway site identifies 85 collections (comprised of 32 collections and 53 sub-sets) with more than 1,000 records relevant to "dance."
These results illustrate the difficulties that lie ahead as the developers strive to integrate the registry and gateway services into a coherent framework. 4.4.3 DLF Digital Collections RegistryThis new registry, maintained by University of Illinois, describes the digital collections hosted or contributed by DLF member institutions and allies that are publicly available and OAI-compliant. As of May 2006, it comprises more than 750 collections from 32 institutions in 19 states plus the British Library (UK). Most of the repository descriptions are based on the collection description schemas that were developed for the IMLS DCC project. In an early stage of development, the site still needs to publicize a collection policy and review its current listings against those criteria. It is accessible from http://gita.grainger.uiuc.edu/dlfcollectionsregistry/browse/. The DLF Registry has the same user interface as the IMLS DCC Web site, with similar browsing and search options. Browsing collections by time and place reveals that most collections treat late 19th-century and early 20th-century resources about North America. However, the registry embraces collections from ancient to modern times and spans from Africa to South Asia. It is also possible to browse by institution and project. So far only one project is listed-American Culture embracing 46 collections.
This registry promises to make more visible the digital collections of prominent institutions. Eventually, it should mesh with the DLF Portal (described in section 4.1.8) to offer seamless collection to item discovery and access. 4.4.4 American Memory and Other OAI Digital Collections at the Library of Congress
Although the pilot public/private partnership aggregating collections into American Memory has ended, the Library of Congress remains at the forefront in facilitating standards-based digital aggregations and interoperability. In November 2005, Librarian of Congress, James Billington announced LC's campaign to create the "World Digital Library" (WDL) with an initial $3 million contribution from Google (Vise 2005). LC's impressive "Global Gateway" to multilingual resources on world cultures already establishes the precedent of building collaborative digital collections in partnership with other national libraries. Since the 2003 DLF report appeared, American Memory has grown considerably in size, adding new digitized collections from LC, implementing XML-approaches to audio projects (e.g., Veterans History Project and the Library of Congress Presents: Music, Theater & Dance), and contributing records to the DLF MODS Portal. Its redesigned front page is a model of clarity and functionality, enabling users to:
In this way, it immediately addresses the varying needs of diverse users ranging from the novice to expert. At the secondary level,
Users can search across all collections or limit their search to specified collections by topic. Results can be displayed in two forms: the default list view (with links to the item and corresponding collection) or gallery view, with clickable thumbnail prints (or when not available, title with link). An early leader in OAI adoption, LC makes item-level metadata available from American Memory, the Global Gateway and the Prints & Photographs Division's Online Catalog. This includes, for example, all records for LC's moving image materials included in the Moving Image Collections (Johnson 2006). Helpful background documents and guidelines for prospective OAI harvesters are available from the About page (see Technical Information). [[168]] Records are harvestable as sets organized by content type; when more than one set exists, there is the option to harvest individual sets or the combined set. As of May 2006, LC lists the following available records:
4.4.5 Sheet Music Consortium (SMC)
Intended to leverage the research potential of digital sheet music collections, the Sheet Music Consortium has added two collections-National Library of Australia and the Maine Music Box-to its aggregation since 2003 and is currently adding two more collections from the University of Colorado, Boulder and from the University of Missouri, Kansas City. The Library of Congress and the National Library of Australia have full digital images associated with the metadata records, whereas Indiana University and Duke have a mix of bibliographic metadata and digitized images. For sheet music published after 1922 (and therefore likely under copyright protection), UCLA provides access to the sheet music cover but not the sheet music itself. The Maine Music Box estimates that 62 percent of its collection is in the public domain. For items still under copyrto the sheet music cover but not the sheet music itself. The Maine Music Box estimates that 62 percent of its collection is in the public domain. For items still under copyright (from 1931 forward), the Maine Music Box does not display images of the score or sound files. Current data providers are listed below along with the number of metadata records [[170]]:
The SMC Web site lists more than 60 institutions that provide some type of public access to digital sheet music collections. Nevertheless, the SMC's aggregation from a mere seven collections contains many more examples of sheet music than other search engines or union catalogs are able to retrieve. SMC could fill a void if it succeeds in attracting more members into the consortium and developing into a full-scale, sophisticated community of practice.
Regrettably, SMC does not provide collection descriptions, current harvesting statistics, or details about the number of records, such as those with bibliographic metadata that also have associated digitized images. It is possible, however, to limit searches to digitized sheet music only. The absence of collection-level descriptions is unfortunate since several contributing entities represent multiple special collections from different libraries. For example, the Maine Music Box is an aggregation of five collections drawn the Bagaduce Music Lending Library and the Bangor Public Library. The Sheet Music Consortium's user interface has not changed since 2003. It supports both basic and advanced searches, including limiting queries to digitized sheet music only. The primary advantage of using the SMC is the ability to search across multiple collections, coupled with the functionally that permits users to select records, add annotations and save (or email) items to a virtual collection that can be shared with others or reserved for personal use. The following table shows options for creators of Virtual Collections. Only owners of collections can delete them. Collections without owners will be deleted annually.
Source: http://digital.library.ucla.edu/sheetmusic/oaihelp.html Future service enhancements-for example, distinguishing between composers and lyricists, providing access to descriptive elements like plate and publisher numbers, or specifying different types of dates-are hampered by limitations of the available metadata (Davison et al. 2003). As a result, the SMC offers sparse services when compared to the native environments of the constituent collections. Although SMC principals speculate about expanding to include other musical formats, they foresee "a danger in generalizing the service into to [sic] areas that may be better served by other means of discovery" (Ibid). Without any plans to enrich the legacy metadata or integrate SMC more fully into e-learning or e-research environments, SMC seems destined to remain an online union catalog of digitized sheet music with the potential of creating personal or shared virtual collections. While this does fill a need as discussed above, SMC might take a lesson from its partners and review features that they have implemented to develop a more ambitious vision of its future. PictureAustralia, for example, an aggregation that includes the NLA digital music collections, does incorporate different media and also permits discovery by theme.
Duke's collection can be browsed by subject content type, illustration type, advertising, and decade (with topical categories). The Maine Music Box offers browsing by subject and sheet music cover art. Moreover, it offers the ability to listen to sound files and has created an instructional module with customized services. Still in its early stage of deployment, its developers believe that "it will take a new generation of music educators to use digital collections as instructional tools." Overall, they "would encourage a vision that provides tools for integrating sheet music collections with other digital libraries," especially promoting their relevance to social and cultural history. [[171]] 4.4.6 Heritage West (formerly Heritage Colorado)
Operating as a not-for-profit with 501c3 status since 2002, the Colorado-based Collaborative Digitization Program (CDP) has expanded its core goals-(1) to achieve high quality digital access to cultural heritage collections and (2) to provide resources and training to create digital surrogates of primary source collections-beyond the borders of Colorado to work with partners across the western United States, including Arizona, Colorado, Kansas, Montana, Nebraska, Nevada, New Mexico, Utah, and Wyoming. CDP members (21 as of April 2006) pay an annual fee ranging from $100 to $2,500 based on their institution's operating and collection budgets. In 2005-06, CDP began to award member institutions with vouchers for free participation in CDP-sponsored workshops or on-site training by CDP staff. CDP carries out its work under the aegis of a Board of Directors, four staff members, and six working groups (Digital Collections, Digital Audio, Digital Imaging, Digital Preservation, Technology, and Metadata).
The re-designed Web site offers a multitude of options to meet the needs of varied users from searching CDP's two major collections (Heritage West and Colorado Historic Newspapers) to reading about upcoming CDP workshops, reviewing "Best Practices," linking to "Lesson Plans," or viewing a "Member Spotlight." The "Digital Toolbox" incorporates best practices in digital imaging, Dublin Core metadata, and digital audio; offers information about workshops; and connects to project management guides. "The Teacher Toolbox" is organized into three areas: Why Primary Sources? (links to other primary source sites geared to teachers such as American Memory's Learning Page), Lesson plans, and Professional development. Heritage West (formerly Heritage Colorado) offers users the ability to conduct unified searches across the digital collections of 77 participating libraries, museums, archives, and historical societies. The new user interface supports basic and advanced searches, as well as searches by topical category. For example, in advanced search mode, users can limit their query to seven collections (comprising the original Heritage Colorado collection, the Denver Public Library and Colorado Historical Society's photographs and images collection, and the five components of the "Western Trails" collection-from Colorado, Kansas, Nebraska, Utah and Wyoming). Search results can be sorted by author, title or date, and saved for emailing. The results are also summarized according to the collection from which they are derived, offering an alternative means of accessing the items. The Colorado Historic Newspaper Collection (CHNC), CDP's other major database, currently covers 86 newspapers (291,000 digitized pages) published in English, German, Spanish or Swedish in 46 cities and 34 counties throughout the state of Colorado from 1859 to 1928. New material is added on a monthly basis. After extensive user testing, CHNC launched a new search interface in November 2005. It enables users to search newspapers by region within the state and allows them to create a customized group of newspapers for searching. In December 2005, CHNC received a Library Services and Technology Act (LSTA) Continuation Grant from the Colorado State Library that will allow them to partner with the Denver News Agency to run six workshops for educators about the use of historic and current newspaper content in teaching. As part of the IMLS-funded IMLS Digital Collections and Content gateway, the University of Illinois helped CDP to become OAI-compliant in 2003. OAIster now harvests more than 32,000 items from CDP. While CDP is a collaboration success story, it faces tough decisions about how best to federate searching across multiple databases and whether or not to maintain its own customized software system (DC Builder) or migrate to a commercial solution (Bailey-Hainer and Urban 2004). Reports about CDP are available at its Web site, including a recent presentation by Koelling and Shelstad (2006) summarizing CDP's experience with "Collaborative Digitization Programs." 4.4.7 The American West
The American West (AmWest) is an experimental project to build a regionally and thematically-focused test bed of OAI-harvested metadata contributed by multiple institutions. Led by the CDL, the AmWest collection has an estimated 250,000 objects contributed by eight partners including the California Digital Library (CDL), the Collaborative Digitization Project, the Library of Congress, Harvard University, and four other university libraries (Indiana, Michigan, Virginia and Washington). Built on the basis of user needs articulated in a series of assessment workshops, AmWest intends to serve a diverse audience ranging from University of California and community college faculty to academic librarians, K-12 teachers, and public librarians. [[172]] In particular, it aims to develop tools to configure and integrate virtual collections with local personalized content as well as develop the capacity to deliver learning objects via various platforms such as WebCT. [[173]] The project's user assessment reports offer a wealth of insights into the behaviors, needs and expectations of different user groups, while also identifying common ground. Key findings from user interviews resulted in the following recommendations:
Source: Adapted from Appendix I, Poe 2005, 11 http://www.cdlib.org/inside/assess/evaluation_activities/docs/2005/survey_May2005_report.pdf The principal investigators have also carried out preliminary work on metadata enhancement to support topical clustering and faceted browsing. Given the extensive amount of pre-processing and human intervention involved in enriching the metadata, they propose that further experimentation-perhaps by the DLF Aquifer Project-is required to determine the optimal balance between collaborative and local responsibilities to facilitate automated classification upon ingest of harvested records and reduce the labor-intensive process of clustering to arrive at targeted topical terms (Landis 2006). 4.4.8 DLF Aquifer
Leveraging the quality digital content developed by the Digital Library Federation (DLF) Libraries in American culture and life, the DLF Aquifer is a collaborative project, open to all DLF members, with fourteen current participating institutions, to build an open distributed library. DLF Aquifer will create a test bed of middleware tools and services to support the needs of digital library developers and scholarly end-users alike. To this end, Aquifer has four working groups (Collections, Metadata, Technical Architecture, and Services) along with a coordinating implementation group that sets policy. To date, Aquifer has completed a:
N.B. Link may be unstable due to experimental nature of this site. (Adapted from Kott et al. 2005) The key findings of the institutional survey along with corresponding Aquifer service responses are outlined below:
Source: Adapted from DLF-Aquifer Services Institutional Survey Report 2006, Executive Summary: 3-4. Integral to this report is an annotated list of other user assessment instruments developed by DLF institutions, such as the American West surveys discussed above. These assessment activities are grouped into the following broad categories: Metadata Harvesting and Searching Portals, Collection Aggregation and Display, Navigating and Using Digital Object Collections, and Collecting and Analyzing Usage Data. Together they provide a strong foundation to inform future research about user services in the context of collaborative digital library development. Three phases are envisioned to roll-out Aquifer service development priorities:
Developed from OAIster, the Aquifer portal features user interface improvements, including thumbnails; additional fields to search (e.g., language and institution); an additional resource type (e.g., dataset) and SRU functionality. Next steps include date normalization and subject clustering. Aquifer is also experimenting with another innovation-"asset action package"-designed "to support a consistent user experience and deeper level of interoperability across collections and repositories" (Kott et al. 2006). This allows multiple views of resources in an OAI context. In practice it enables users to deploy locally-available tools (e.g., for image manipulation, annotation, and saving) with disparately-held content from other repositories that use "asset actions." [[174]] 4.4.9 SouthComb
Leveraging an impressive series of digital initiatives to advance scholarly communication carried out under the umbrella of "MetaScholar," Emory University received funding in March 2006 from The Andrew W. Mellon Foundation to develop a "capstone" project that would encompass and build on previous metadata harvesting efforts. Tentatively named SouthComb, the project aims to create a sustainable interdisciplinary search portal targeted to Southern Studies research. SouthComb will implement all of the experimental techniques that Emory has developed for harvesting, automatically classifying, and metasearching information from OAI repositories, Web pages, and other scholarly resources. It will establish an advisory panel of Southern Studies scholars at various universities to review and select resources, thus allowing it to develop sub-portals tailored to meet the needs of particular academic programs. It also aims to widen the cadre of scholars contributing to Southern Spaces-an innovative, peer-reviewed Internet journal and scholarly forum created by Emory University. [[175]] SouthComb intends to advance regional collaboration by advising partner institutions in the use of OAI-PMH tools, such as the Metadata Migrator developed at Emory [[176]], and by extending participation in the MetaArchive preservation network. [[177]] To sustain its efforts over the long-term, SouthComb expects to adopt a hybrid business model, consisting of a freely available basic Web resource and a more sophisticated version with advanced features, available on a cost-recovery basis via institutional subscriptions. According the principal investigators lessons learned and tools developed during previous MetaScholar Initiative projects have contributed significantly to the ability to construct SouthComb. [[178]] They note the following building blocks:
User studies conducted for the AmericanSouth project revealed a common desire to search across multiple resources-a finding echoed in other studies of the demands of interdisciplinary research. A hindrance to providing such a tool, however, was the lack of controlled or consistent subject vocabularies for many of these resources. The MetaCombine project, through its focus on semantic clustering techniques, sought to remedy the obstacles to subject browsing of such heterogeneous materials. In the process the project discovered that focused crawling of Web sites (selectively crawling only Web sites that are relevant to the subject domain under consideration) greatly improved the quality of the results. The harvested results could then be classified according to semantic similarities and organized into taxonomies for easier browsing. These searching techniques, combined with newly developed systems for assigning metadata and visually displaying conceptual connections among records, form the core of the new SouthComb search system. [[180]] Other features of the SouthComb search system, developed during the MetaScholar Initiative's Study of User Quality Metrics project, will allow researchers greater precision in identifying resources that are most useful to their work. Using focus-group data on how scholars in the sciences, social sciences, and humanities actually search for and identify quality digital resources for their work, the Quality Metrics project built a new prototype search system that permits scholars to discover resources using both explicit attributes (such as title, author, and other data that currently appear in library records) and implicit attributes (such as citations in journals, usage information from logs, and number of times included in electronic reserves-latent indicators of the scholarly value of a resource). Which resource attributes are highlighted for Southern Studies researchers depends considerably on communications among scholars and the librarians and archivists who provide access to those resources and on focused conversations with scholars about ways they use resources. The synergistic opportunities continue through the SouthComb portal itself, particularly in its connection with Southern Spaces. As a foray into peer-reviewed digital scholarship, the Internet-only journal Southern Spaces has re-imagined the possibilities for digital publishing. Through gateways, events and conferences, interviews and performances, and essays that capture the Internet's multimedia potential, the journal's content models the types of scholarly products possible through digital collections and fuels innovations in digital scholarship.
SouthComb hopes to achieve long-term sustainability by providing scholars with the resources they most need and desire. To that end, Emory's digital library has already constructed a Southern Digital Archives Conspectus (SDAC) that describes and provides access to the library- and museum-produced open access digital collections currently available on the topics of history, literature, and culture in the U.S. South from the Colonial Period to the present. [[181]]
Source: http://southconspectus.library.emory.edu/SPT--BrowseResources.php (May 2006) This survey identifies unique collections that would be of great interest to Southern Studies scholars as well as gaps in the digital landscape that could inform future digitization and harvesting efforts. Building SouthComb is conceived as an on-going exercise in community identification and collaboration, leading to greater community investment in digital access to resources, digital scholarship, and digital preservation. 4.4.10 Perseus Digital Library
In May 2005, the Perseus Digital Library (PDL) released version 4.0 of its system software, facilitating interoperability and closer alignment with Web standards, including support for distributed catalog services based on MODS/MADS/SRU/OAI. The new technology offers capabilities such as:
In recent months, PDL has also released significant new content related to 19th-century American documents, taking advantage of new technologies and services (Crane 2006). The user interface permits navigation through texts by "chunking" documents by chapters, parts, pages or tables of contents, and automatically extracts salient places, people and dates for immediate viewing. At the time of this writing, PDL's content appears to be betwixt and between the original Web site and the new release. [[185]] It is difficult to correlate the collection overlap (5 at the original site, 4 at the new site) because they are identified by different names.
As evident from the screenshot below, when a particular text is selected, relevant Places, People and Dates are automatically extracted and linked (right-hand frame). The text can also be navigated by chapters and table of contents from the left-hand frame.
Developers interested in the evolving technology piloted at PDL should refer to Crane (2006) and related publications at the Web site. In addition to the eventual release of a named entity browser, the principal investigators are researching the implementation of a distributed editing environment whereby users may correct errors, comment on topics, create custom commentaries, user guides, discuss issues with other users, and personalize the Perseus experience. 4.4.11 NINES: Networked Interface for Nineteenth-Century Electronic Scholarship
Established in 2004, NINES is a scholarly collective to promulgate peer-reviewed digital scholarship in 19th-century cultural and literary studies, British and American. Headquartered at the University of Virginia under the leadership of Jerome McGann, (John Stewart Bryan University Professor and editor of the acclaimed hypertext project, The Rossetti Archive), NINES is sponsored by five scholarly societies:
Guided by a Steering Committee and three domain-specific Editorial Boards, NINES aims to (1) create a shared information management system to coordinate the process of submitting, peer-reviewing and certifying the integration of digital work into NINES and (2) develop a set of customized tools to facilitate knowledge discovery and interpretation (McGann and Nowviskie 2005, 12). In December 2005, NINES launched a pilot implementation, comprising 24,975 peer‑reviewed digital objects, aggregated from six digital projects:
The NINES technology plan has evolved from a centralized, hierarchical approach requiring compliance with a monolithic set of governing standards for text markup, metadata, interface, and archiving to a more flexible, collaborative and non-hierarchical design, relying on RDF (Resource Description Framework) syntax to facilitate description and semantic integration of NINES resources. NINES uses a customized open-source indexing system and the Lucene search engine, customized to integrate faceted browsing. COLLEX, a tool developed by NINES, serves as the backbone of the system that "brings this indexing and search design framework into a collaborative research environment" (Ibid, 15). COLLEX "leverages current developments in folksonomy and semantic-web technology to perform data mining operations and enhance knowledge discovery," . . . leading scholars and students "to see connections among digital objects, based on the contexts into which those objects have been placed (implicitly or explicitly) by past scholarly activity in the system" (Ibid, 15-16). Users of COLLEX can:
In addition, NINES has developed two other interpretative applications that can be used in tandem with COLLEX or independently. Juxta is a collation and text comparison tool with analytical visualization capability (released for testing in February 2006). IVANHOE is a collaborative interpretative play space, especially designed for pedagogical use [[187]] (McGann 2005). NINES aims to increase participation in digital scholarship by awarding competitive fellowships during the summer to train scholars who are developing digital projects and by working with journal editors to facilitate the migration of paper-based journals to digital or hybrid formats. As of this writing, NINES is seeking grants to extend its development for another two years and also hopes to gain endorsement from the Modern Language Association of America. 4.4.12 Current Issues and Future DirectionsSynergies among these services are apparent in terms of sharing collections (Heritage West/American West; DLF Aquifer/American West/Southcomb), metadata schema (Cornucopia/IMLS DCC), user interface and search systems (IMLS DCC /DLF Digital Collections Registry), and tools development (American West/DLF Aquifer/SouthComb). In these and other ways, this cohort collaborates and builds on each other's work, directly or indirectly. They represent, however, different models of achieving organizational sustainability. The more complex services, such as DLF Aquifer, SouthComb, and NINES must engage at least three different communities of practice: scholarly and disciplinary circles; digital library technical domains; and e-learning and/or e-research service communities. For these aggregation services to flourish over the long-term, they have to be cognizant of the needs and trends across all three sectors. NINES, for example, garnered support from a host of relevant scholarly societies, humanities digital computing centers and other digital libraries in addition to establishing editorial boards charged with peer-review oversight for content. While it is scholar-led, the service itself is embedded in a library setting at the University of Virginia. DLF Aquifer, on the other hand, operates in a decentralized manner where participants agree to terms spelled out in a business plan, collection development policy and other technical specifications. It is driven by the DL community and loosely informed by scholars, with the intention of building prototype tools and services that can be applied at different institutions to meet their particular needs. SouthComb has a multi-faceted organizational structure, with scholars taking the lead for some components, such as the journal Southern Spaces, while the library develops the tools and finding system. The library and scholars work in tandem to identify new content and bring it into the aggregation. A challenge facing all three of these collaborations is how to achieve a reputation of sufficient stature that other scholars and libraries are willing to contribute their time (for example, peer review or tool development), content, scholarship, and financial resources outside their local institutional setting. In short, are the benefits of collaboration, fruits of cooperative labor, and reward system adequate to carry the day? It is important to acknowledge that virtually all of the services under review in this section play a major role in empowering other data providers to achieve interoperability through OAI implementation and promulgation of best practices. Projects like Cornucopia, IMLS DCC, and Heritage West provide constituent services with the tools they need to maintain control over their own information environments while also fostering their ability to contribute to aggregations. In this way, they have helped to increase the quantity and quality of data providers. Representatives from many of these services (e.g., IMLS DCC, American Memory, American West, SouthComb, DLF Aquifer) are directly involved not only in developing the "Best Practices for OAI Data Provider Implementations and Shareable Metadata," (a joint DLF and NSDL initiative), but also in creating the means to achieve consistent and adequate metadata. Nevertheless, many of them note the unmet challenge of having sufficient automated and semi-automated tools at their disposal to enhance and remediate metadata for scholarly use. A particular challenge and focus of activity among these services is devising methods to achieve subject classifications, thematic groupings or topical clustering across large, heterogeneous collections. In July 2006, the Digital Library Federation and The Andrew W. Mellon Foundation are sponsoring "The Metadata Enhancement and OAI Workshop" at Emory University where DL specialists will examine automated and semi-automated strategies for metadata enhancement and remediation scenarios involving the OAI protocol. Some of the scenarios being considered include normalization of date and format fields and taxonomy generation/assignment. The workshop will result in an agenda for specific experiments to assess various scenarios collaboratively, especially as part of the DLF Aquifer project. Other common challenges revolve around standardization of terminology, multilingual metadata and search support, and aligning collections with their associated items in meaningful contexts. Future generation plans include new user interfaces that enable side-by-side comparison of documents, more interactive features and interpretative tools, the capacity to move complex digital objects from domain to domain, and the ability to migrate core data to production sites where preservation services are also available. Finally, funding strategies (aside from grand and foundation funding) to ensure long-term viability is common concern for these services. Heritage West has a membership fee structure. DLF Aquifer's business plan includes a provision to consider fee-for-service components after its initial development and SouthComb will make some of its services available through institutional subscriptions. Ultimately, the longevity of this cohort rests on how well it meshes with pedagogical practices, e-scholarship, and lifelong learning pursuits. 4.5 User Alchemy: Discover, Deliver, DivineFirst Choice for Information-by College Students across all Regions "Which source/place would be your first choice?
Source: OCLC 2006, A-20. The services under review in this section are all attempting to distinguish themselves from generic but hugely popular search engines by customizing their approach to meet the needs of the academic community. From niche search engines to customized and "accessorized" portals, they are components of evolving finding systems that move beyond discovery to the delivery and re-use of digital content. They represent a progressive spectrum of solutions to integrating search results from federated searching to metasearch systems, differentiated by "just-in-case processing" versus "just-in-time processing" (Sadeh 2006). The review starts with Scirus, a federated search service which has increased its coverage significantly since 2003, by extending Web crawling and indexing to a much broader array of subjects. It moves on to Infomine, a collaboratively developed index and catalog of expert-selected and robot-retrieved Internet resources. Next, a service from the UK, "Intute," along with the transition to this new name, hopes to become a trusted, first-choice, Internet "mentor" and filter for quality information. More than a search engine, Intute is embedding its resources and services into a variety of teaching and research environments. Finally, the California Digital Library's Metasearch Initiative represents a coordinated and multi-faceted digital infrastructure that integrates all resources-irrespective of origin, host location or protocol-into user-controlled service environments. The later two projects, not yet fully deployed, show the promise of how various standards and best practices come together in service to the academic community. 4.5.1 Scirus
Scirus [[188]]. Elsevier's award-winning search engine [[189]], continues to grow in content, types of information, and functionality. "How Scirus Works" (updated in August 2004) describes its process of gathering and classifying data into its index; it also explains search functionality, ranking and search refinement. [[190]] Scirus uses a combination of focused Web crawling, based on a "seed list" of URLs manually checked for scientific content, and database loads from its partners (e.g., ScienceDirect, MEDLINE, LexisNexis) and OAI harvesting (e.g., from arXiv.org, RePEc, NDLTD). As of early March 2006, it boasted more than 250 million Web pages with the majority derived from educational institutions; the slowest growth in representation is from commercial sites.
Source: Scirus "about" page. Since 2003, Scirus has augmented considerably its journal and "preferred Web sources" content from a combination of subscription-based (e.g., Crystallography Journals Online, Institute of Physics, Scitation) and freely available OAI sources (e.g., PubMed Central, DiVA, MIT OpenCourseWare, NDLTD, RePEc). (It has also dropped several sources including Beilstein Abstracts and its own-Elsevier-Chemistry, Mathematics and Computer Science Preprint Archives. These are available on a subscription basis via Chemweb, Elsevier's Chemistry portal and other Elsevier portals.) While its coverage is strongest in the sciences (especially its journal sources), Scirus's subject scope now expands across all disciplines due to the inclusion of multidisciplinary content from ETDs, academic OAI repositories, and broader Web crawls. The category below, "Digital Archive" currently consists of records from Organic eprints and the UMDL. Elsevier expects this category to expand significantly in the course of the year. Scirus now also indexes news sources and offers news results in a dedicated section at the bottom of the results page. The feature includes news items form the last 30 days and ranks results by relevance and date. Up-to-date news from the New Scientist is also available directly from as a link off the home page.
Source: Sources are from search categories available from the Advanced Search page. Record counts are from the "about" page. Figures in brackets and additional information about patent sources are from email correspondence with Sharon Mombru on March 17, 2006. Users can perform a search within or across three broad categories: all journal sources, preferred Web sources, or other Web sources. (Scirus indexes Web pages and their relationships, classifying the content by subject and information type through utilization of a collection of dictionaries with more the 1.6 million scientific terms, pattern recognition tools, and linguistic analysis. This enables users to limit searches by eight different information types and twenty subject areas as well as six file format types.
Source: Scirus Advanced Search page Searches can be narrowed to particular authors, journals or titles and restricted to specified date ranges. A sample query for journal articles published in the "Institute of Physics" with the keyword "laemmli," returns results with the search term highlighted (in this case, it appears among the article's references) and clearly indicates the source of the published article.
Predicting the function of eukaryotic scaffold/matrix attachment regions via DNA mechanics view all 3 results from Institute of Physics Publishing similar results Scirus automatically performs "intelligent query rewrites," suggests "did you mean?" queries, and lists alternative keywords to refine or expand searches. Search results are returned according to relevance ranking (determined by an algorithm that takes into account word location and frequency as well as the number of links to a page) or date. Users can refine, customize or save searches and email of export selected search results to their reference management application. An Advanced Search for: EXACT PHRASE <avian influenza> AND ALL THE WORDS <pandemic> Is automatically rewritten as a Basic Search for: <"avian influenza" AND (pandemic)> It retrieves 14,769 total results including 595 journal results, 29 preferred Web results, and 14,145 other Web results. Terms to refine the search are located in the right-hand margin. Several sponsored links follow from commercial suppliers of products for avian flu protection.
According to Elsevier representatives, "Scirus indexes sources of STM-relevance in the broad sense of the world-scientific, technical, medical, social sciences, etc." [[192]] With its more expansive subject scope, Scirus may need to revise its qualifier from "for scientific information only" to "for scholarly information only." The Scirus toolbar and customizable search query boxes (for general searches or limited by subject and other fields) can be added to external Web sites. The Scandinavian aggregator of academic repositories, DiVA, (which is harvested by Scirus) for example, offers users three search options at its Web site, including the ability to use the Scirus search engine (restricting the query to DiVA content, preferred Web sources, or all of the scientific Web). [[193]] 4.5.2 INFOMINE
As reported in 2003, INFOMINE is a national collaborative project led by the University of California-Riverside (UCR) to create a virtual library of scholarly Internet resources, utilizing the open source iVia software platform. INFOMINE provides access to more than 200,000 freely available and commercial resources organized into nine subject areas and covering a wide spectrum of media formats. The INFOMINE database represents a hybrid approach to collection building, relying on a combination of contributions from library subject specialists and focused Web crawling. As a result, searches can be limited to "expert-selected" or "robot-selected" items. Expert-selected content constitutes less than 20 percent of the total content. [[194]] The flexible, modular system is designed to facilitate cooperative collection-building of the centralized database while also providing institutions with the tools they need to develop customized Internet resource discovery systems with local branding and incorporation of proprietary materials. MyInfomine (also known as MyI) supports building sub-collections of INFOMINE and enables contributors to create MyInfomine Categories, add records to these categories, and perform searches on them. [[195]] For example, librarians at the University of California-Riverside have created MyI categories to create course-specific Internet resource guides as well as to track medical indexes and databases. iVia (http://ivia.ucr.edu) is an open source system for automatically and semi-automatically building library-related metadata and rich text collections of Internet available resources. Web-based virtual libraries like INFOMINE, subject portals and catalogs benefit. The codebase (250k lines of C++) has been designed by and for librarians and computer scientists at the University of California, Riverside, the NSDL< Library of Congress, Cornell University Library and others. The goal of the software is to amplify expert effort in collection building and foster collaboration. iVia supports automated metadata generation to assign Library of Congress Subject Headings and LC Classifications to resources (Mitchell et al. 2004, Paynter 2005). Building on iVia, Data Fountains, currently under development, identifies itself as "a national, cooperative information utility for shared Internet resource discovery, metadata application and rich, full-text harvest of value to Internet portals, and library catalogs with portal-like capabilities." It uses expert-guided and focused crawlers supported in semi-automated (requires expert refinement) and fully automated modes (Mitchell 2006). The expert (or manually) guided crawler drills down from a given URL, whereas the focused crawler uses techniques of co-citation and similarity analysis to identify intensely interlinked and high value resources in a subject. The "Nalanda iVia Focused Crawler" features an "apprentice learner" program that enables it to follow the most promising links; crawling is also improved by utilizing a combined HITS and PageRank algorithm (Ibid). In January 2004, iVia received a two-year sub-contract from NSDL to integrate iVia software into NSDL's Core Integration efforts. This has enabled NSDL to harvest item-level metadata from iVia's server for selected NSDL collections that did not include detailed metadata. By October 2004, NSDL reported that they successfully submitted a URL to iVia's Expert Guided Crawl Service and reviewed the results to delete inactive or irrelevant sites, then harvested the metadata using OAI. [[196]] Phipps, Hillmann and Paynter (2004) discuss NSDL's service interaction with INFOMINE, enabling "loosely-coupled third party services to provide metadata enhancements to a central repository." INFOMINE's advanced user interface supports searches that can be restricted by fields (author, title, subject, keyword, description, full text, and MyInfomine) or by broad subject area as well as restricted by source (expert-created or expert- and robot-created), access (all, free, or fee-based), and type (e.g., article databases, datasets, patents, preprints and working papers, etc.). Users can select the length, number, and order of the results' display. In addition they can browse within several indexes-including LC subject headings and classifications-by keyword, author, title, or what's new (entries added in the last 20 days). Although users can submit comments about resources, there are no other post-processing functions such as saving, downloading, or emailing search results. INFOMINE's search tips are exemplary and include a succinct, yet extensive review of how to combine Boolean and proximity operators.
Source: Infomine Search Tips (April 2006) Three sample queries to find resources relevant to "OAI-PMH," "metadata," and "access within four words of knowledge," show the wide variation in results retrieved from INFOMINE and other general metasearch and cross-archive search engines. Overall, INFOMINE's results are the narrowest (or most refined) but in some instances, such as the query to find resources relevant to OAI-PMH, they appear too limited. INFOMINE's coverage of metadata is stronger and it is the only search engine to support proximity operators. However, it shares the unsolved problem of duplicate entries with OAIster (and probably with the other services as well). This primitive exercise demonstrates the need for a more thorough study to better understand the strengths of these service entities (e.g., Scirus's coverage of journal articles). It also underscores the reason why users need a thorough understanding of the universe covered by these search engines (cum databases) and the need for "nutrition and ingredient labeling" as discussed elsewhere in this report and proposed by Péter Jascó in 1993.
4.5.3 Intute (formerly RDN-Resource Discovery Network)
In mid-2006 after re-structuring and re-branding, the former "RDN" débuted as "Intute," a new name combining Internet and Tutorial to connote the amalgamation of guided learning and online resource discovery. [[197]] As was the case with RDN, Intute is a free online service of high-quality Web resources for education and research, selected by a network of subject specialists. The new service consolidates RDN's eight subject gateways into four broad subject areas, bringing them together with a unified interface:
Intute is a core service of JISC hosted by MIMAS (Manchester Information & Associated Services at the University of Manchester). Its operations adhere to policies and standards documented through a formal Service Level Agreement that covers: collection management policy; marketing and communications; strategic plan; technical integration plan; cataloging guidelines; and network services such as format conversion, printing, authentication and e-commerce. [[199]] JISC monitors and audits Intute's performance and produces quarterly service "trend data" consisting of statistical graphs charting the number of catalog searches, Web pages served, and HelpDesk inquiries. As of late April 2006, the data about RDN and its constituent services hubs is current to October 2005. [[200]] In the first of a two-part series in Ariadne, Hiom (2006) provides a "Retrospective on the RDN," along with a timeline of its milestones (http://www.rdn.ac.uk/projects/eprints-uk/). A future article will discuss the strategies underlying its transformation into Intute. [[201]] 4.5.4 California Digital Library (CDL) Metasearch Initiative
The California Digital Library (CDL) Metasearch Infrastructure Project aims to leverage CDL's experience over the past six years since it first deployed "SearchLight," by establishing an infrastructure that will enable UC campus libraries to create customized search portals for specific audiences and purposes. The metasearch infrastructure adheres to the principles and standards set forth in CDL's Common Framework, an open, services-oriented technical architecture that provides an integrating framework for a full-spectrum of library services, ranging from archival (where objects are stored locally, e.g., UC's Digital Preservation Repository), to metadata only (where only metadata is stored locally), to portals (where no data is stored locally). [[202]] In addition to The American West metadata portal, discussed earlier in this report, the CDL has several other prototype portals in various stages of development: [[203]] NSDL: In fulfillment of a NSF grant to build and enhance the NSDL, the Earth Sciences portal is geared to meet the needs of the UC geosciences community, and serve as an exemplar of integrating NSDL content into university library services. A pilot deployment of the Earth Sciences portal is being evaluated as of mid-May 2006.
Convenience of e-commerce (Amazon). Participants' Internet usage has set high expectations for a service-rich environment.
The report also fleshes out the content discovery and integration principles that should inform the design of CDL's metasearch services.
Source: Christenson and Tennant 2005, 4-6. The authors then chart the strengths of five different methods of integration (e.g., ingesting, harvesting, Web crawling, syndicating, and metasearching) against the relevant integration principles, the conditions in which each method is the most appropriate, and the implementation obstacles.
Source: Reprinted with permission of the authors. (Christenson and Tennant 2005, 7) As the authors explain: A suitably developed metasearching infrastructure can be used to provide a common interface to content integrated by any or all of these methods. Thus the standard metasearch application marketed by software vendors is but one piece of a robust metasearching infrastructure. Such an infrastructure must be capable of using each of the integration techniques identified in the above chart while providing a unified user interface to the whole. (Ibid, 7)The schematic bellows depicts how users would access digital resources via different portals. They would also have a suite of tools readily available to manage citations and facilitate the re-use, manipulation, annotation, and integration of resources into teaching and research platforms (e.g., the Scholars Box). [[206]] Current under development "the Scholar's Box is a tool that gives users "gather/create/share" functionality, enabling them to gather resources from multiple digital repositories in order to create personal and themed collections and other reusable materials that can be shared with others for teaching and research. The Scholar's Box can currently perform the following functions:
4.5.5 Current Issues and Future DirectionsThe deployment of these services addresses some of the issues discussed earlier in this report in response to the "Amazoogle Effect," by providing users with the types of services they have come to expect. These efforts are abetted by the work underway at NISO to develop standards and specifications that enable search and retrieval across multiple platforms and vendors, and linking to "appropriate" resources through OpenURL resolution systems. This work is carried out by NISO's OpenURL Framework for Context-Sensitive Services (http://www.niso.org/committees/committee_ax.html) and the NISO Metasearch Initiative. The second initiative brings together three major stakeholder groups organized into three cross-sector task groups dealing with Access Management; Collection and Service Descriptions; and Search and Retrieval specifications (Hodgson, Pace and Walker 2006). The overall goal is "to move toward industry solutions NISO sponsored a Metasearch Initiative to enable:
The first set of deliverables and recommendations was presented at a NISO workshop in September 2005; these documents are available along with the workshop presentations at the NISO Metasearch Initiative Web site. Among the important recent developments, the NISO Z39.92-200x, Information Retrieval Service Description Specification, was released by the Collection and Service Descriptions for trial use through October 2006. "This standard defines a method of describing Information Retrieval oriented electronic services, including but not limited to those services made available via the Z39.50, SRU/SRW, and OAI protocols. The ZeeRex standard addresses the need for machine readable descriptions of services in order to enable automatic discovery of and interaction with previously unknown systems. It specifies an abstract model for service description and a binding to XML for interchange." [[209]] Library service vendors, as active contributors to and beneficiaries of the NISO Metasearch Initiative, are entering the metasearch market and designing new applications based on layered architectures that are intended to consolidate information search results and meet user needs from "discovery to delivery," as exemplified by Ex Libris's new "Primo" metasearch architecture below.
This architecture helps to "create a superb user experience layer, decoupled from back-office functions, separating data creation and maintenance from its discovery." The publishing platform enables libraries to leverage resources irrespective of source, enrich the data, and expose hidden collections. Meanwhile the user is presented with a system that recognizes him (Hello, John Smith) and with results that can be refined, extended, altered, and displayed in various ways, as exemplified by the two prototype screenshots below (Tamar Sadeh, Ex Libris Webinar, May 9, 2006).
The California Digital Library is uniquely positioned to develop its own system wide metasearch infrastructure, relying on a combination of locally developed, open source and proprietary tools and systems. A challenge for all academic libraries is evaluating the appropriate balance of components and services developed internally versus those they purchase externally. With more than 600 people from 29 countries participating in Ex Libris's early preview of PRIMO, it seems that many libraries have already begun to consider their options. Finally, it is worth reiterating that metasearch goal in this context is not about simplified "one-stop-shopping," but about creating a distributed information environment that can deliver subsets of resources, services and tools to users according to their particular needs. [[210]] |
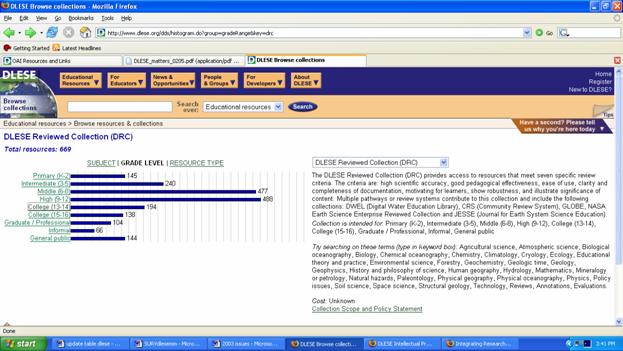
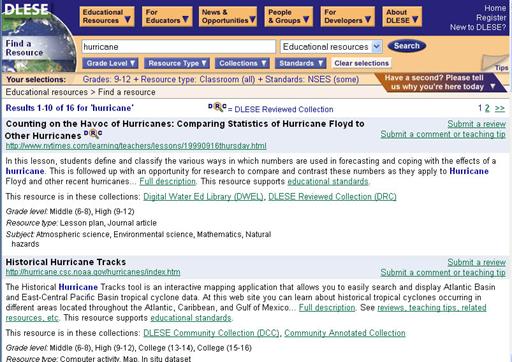
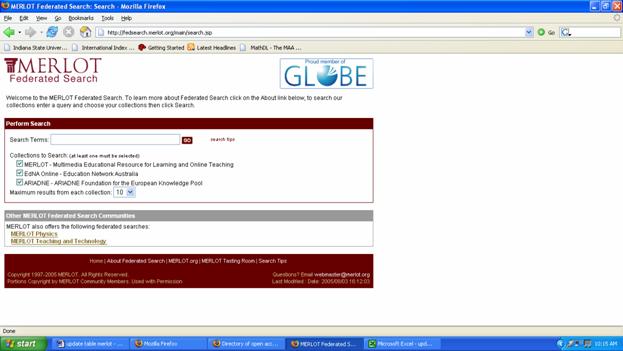
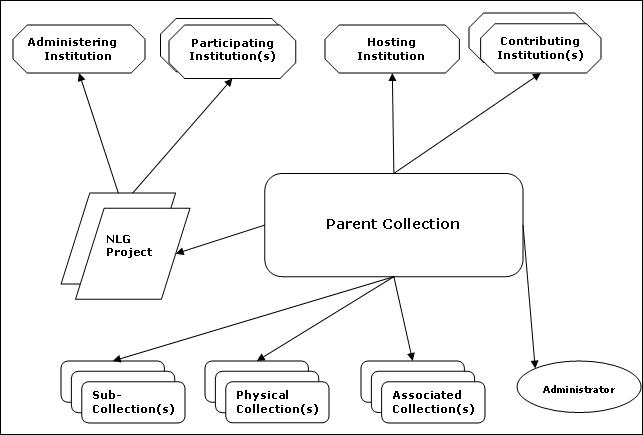
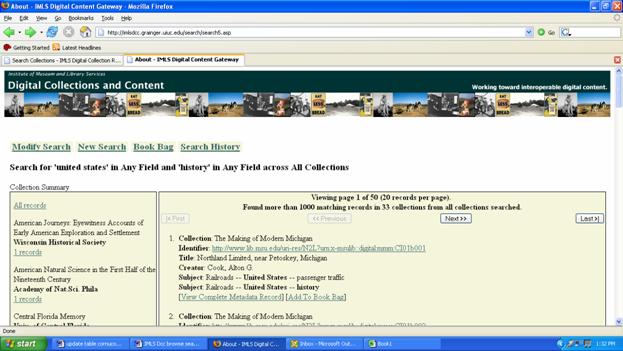
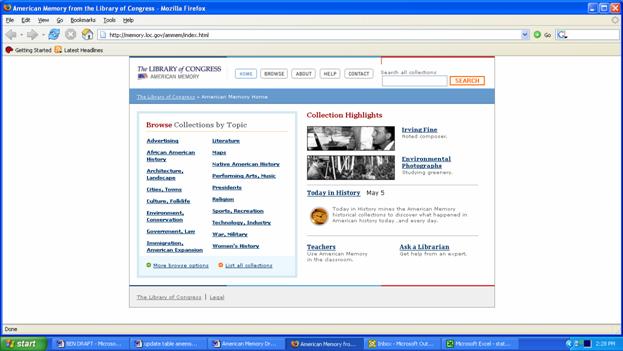
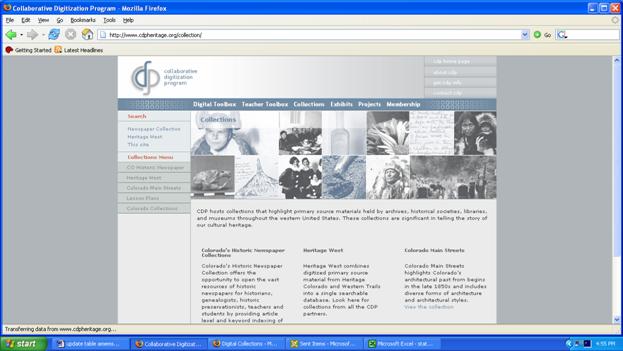
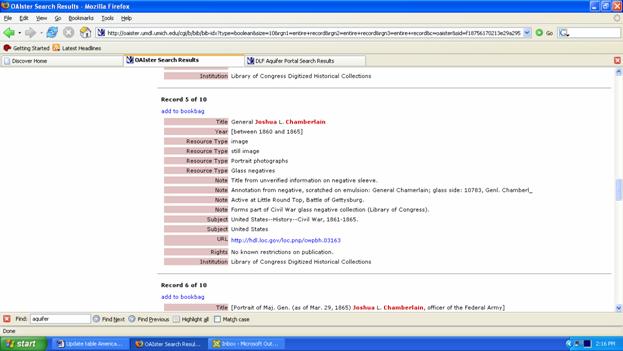
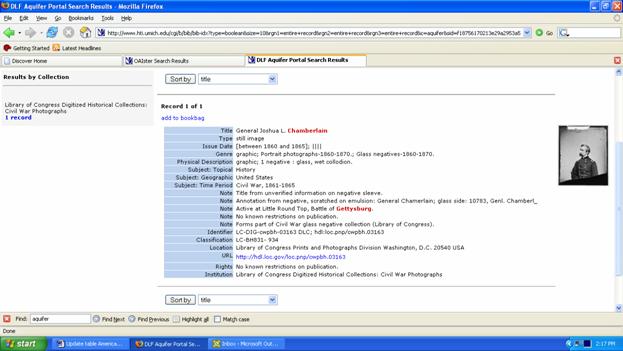
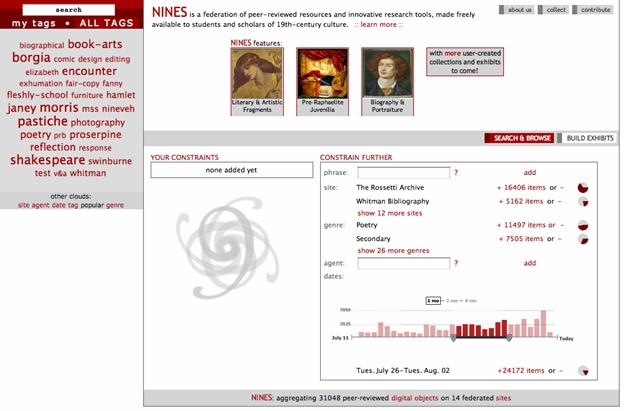
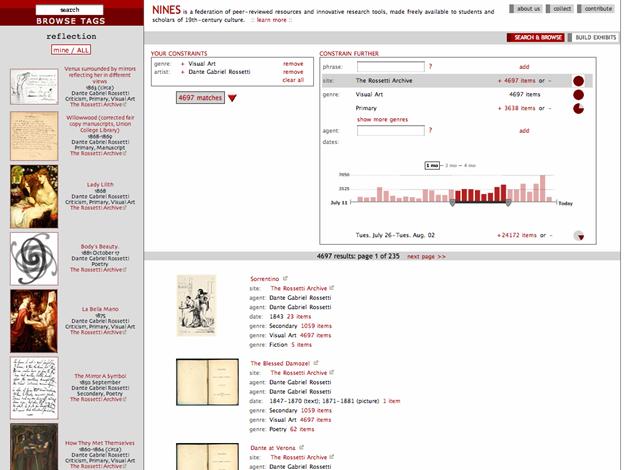

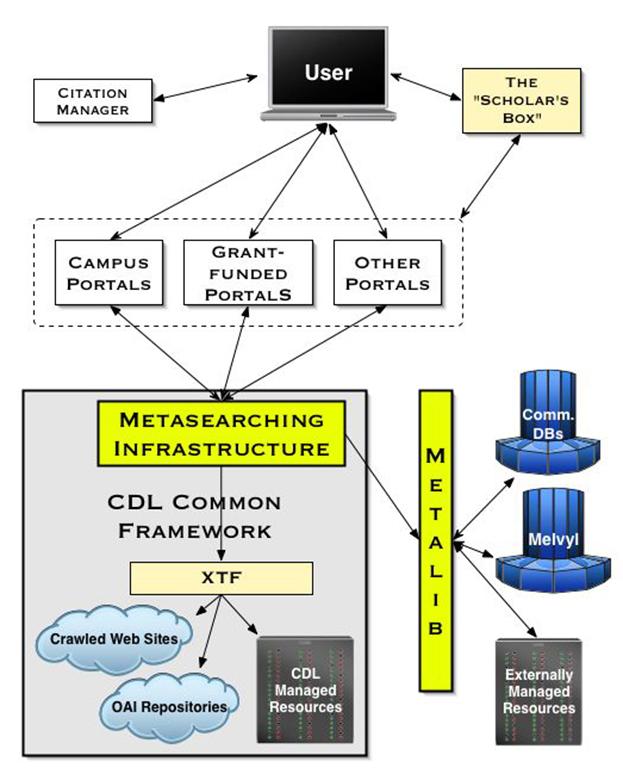
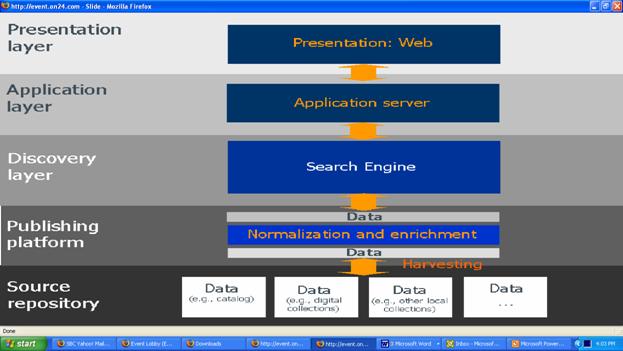
{kind=link}