

PART II: CONTEXTS2.0 Scholarly Information Environment 2006Viewed from any angle, the topography of scholarly digital activity has changed markedly since the DLF released its original survey less than three years ago. At first glimpse, there are many reassuring landmarks-most of the core services discussed in the original report continue to tower over the landscape; however, on closer examination, the scene is anything but static. To highlight some of the changes:
When attempting to understand the scale and pace of change, three phenomena stand out:
2.1 Cyberinfrastructure (CI) ArticulationWhen the DLF issued the previous survey in 2003, digital repositories were only starting to formulate their contributions to cyberinfrastructure (CI) in the sciences and engineering; the corresponding reports on CI in the humanities and social sciences had yet to appear. In October 2004, a symposium jointly sponsored by the Association of Research Libraries and the Coalition of Networked Information launched an important dialogue across stakeholder groups about the function and contributions of libraries to e-research and cyberinfrastructure (Goldenberg-Hart 2004). Referring to transformative changes in scholarly practice, CNI's Executive Director Clifford Lynch advised libraries that "a failure to put into place effective new support structures in response to these changes would pose tremendous risk to the enterprise of research and scholarship. The role of libraries, he argued, will shift from primarily acquiring published scholarship to a broader role of managing scholarship in collaboration with the researchers that develop and draw upon it" (Ibid). [[3]] With the creation of the Cyberinfrastructure Council and establishment of the Office of Cyberinfrastructure in 2005, the National Science Foundation (NSF) has put into place a management structure to oversee its growing investment in effective CI development and deployment. The CI-Team represents a "cross-cutting," NSF-wide activity in which all Directorates participate, including the Directorate for Undergraduate Education in the Division of Education and Human Resources (EHR) that oversees funding for the National Science Digital Library (NSDL), and the Directorate for Geosciences, that funds the Digital Library for Earth System Education (DLESE). NSDL and DLESE (both described later in this report) serve as bridges between the e-learning and e-research communities in cyberinfrastructure development. Especially noteworthy is DLESE's partnership with GEONgrid, a network building cyberinfrastructure for the geosciences, relying heavily on geoinformatics. The cyberinfrastructure phenomenon has galvanized scientific communities into action, fueling the transformation of disciplines and ushering in new research methodologies. [[4]] The CI-Team's Web site (http://www.nsf.gov/crssprgm/ci-team/) provides links to relevant reports and projects, including discipline-specific endeavors such as GEONgrid. [[5]] It also identifies major CI reports and projects relevant to the humanities and social sciences. Several new projects described in this report reflect efforts to build cyberinfrastructure support in the humanities. Cornucopia and the IMLS (Institute of Museum and Library Services) Digital Collections & Content exemplify the contributions of libraries, archives and museums while DLF Aquifer, NINES (A Networked Interface for 19th-Century Electronic Scholarship), and SouthComb reflect efforts to support digital scholarship in the humanities. Released in January 2005, NSF's Cyberinfrastructure Vision For 21st Century Discovery, version 5.0, calls for the development of strategic plans for four key CI components:
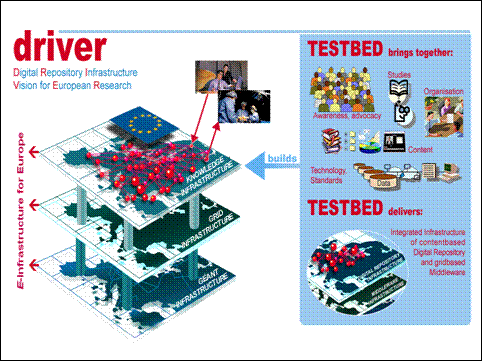
It comes as no surprise to find that capturing the research output from digital repositories such as arXiv, NTRS, and PubMed Central as well as in institutional repositories like the CERN Document Server (CDS) aggregation, is a key element in the design of complex, collaborative digital library infrastructures. NSDL aggregates metadata from these and other innovative services such as Reciprocal Net (http://www.reciprocalnet.org/) which harvests crystallographic data from 18 partner institutions and creates a searchable database. The JISC-funded eBank project, which is part of the UK's Semantic Grid Programme, demonstrates how to link "research data with other derived information" by harvesting from both e-print and e-data archives. Utilizing the GNU Eprints software, the project will link crystallographic data from the Combechem project with Intute's (formerly RDN) PSIgate Physical Sciences Information Gateway (http://www.ukoln.ac.uk/projects/ebank-uk/). [[6]] Another pan-European initiative serves as an excellent example of transnational collaboration in building a digital research infrastructure. DRIVER: Digital Repository Infrastructure Vision for European Research is a consortium of nine European universities and research agencies that is developing a "test-bed for integrating existing national, regional and/or thematic repositories in order to create a production-quality European infrastructure" (Lossau 2006). DRIVER has four major activities: (1) content and organization provision through the aggregation of an initial set of 50 repositories; (2) implementation of an open, distributed, service-oriented repository infrastructure middleware; (3) focused studies; and (4) raising awareness. DRIVER expects to start in July 2006, release in June 2007, and become a production service in April 2008. The figure below illustrates the initial conceptualization of DRIVER's infrastructure.
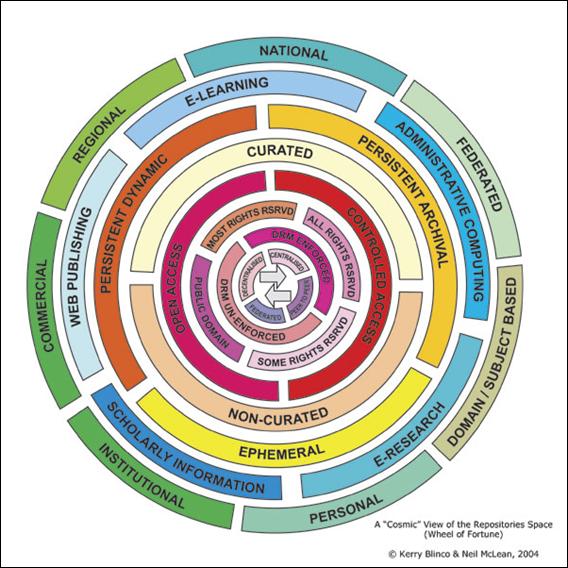
2.1.1 Convergence Across Higher Education Service DomainsBlinco and McLean's "cosmic view" is perhaps the best depiction of key variables that influence the digital repository workspace. Their conceptualization identifies five major service domains in higher education: E-Research, Scholarly Information, E-Learning, Web Publishing, and Administrative Computing. Designed as a "Wheel of Fortune" set in motion, the concentric circles rotate, illustrating the multiple ways that services may realign. It aptly illustrates the multiple contexts in which digital repositories operate, highlighting the need to develop flexible and coherent frameworks that manage these permutations.
The e-Framework for Education and Research (http://www.e-framework.org/), an initiative led by the UK's Joint Information Systems Committee (JISC) and Australia's Department of Education, Science and Technology (DEST), aptly illustrates this new information environment. It aims "to produce an evolving and sustainable, open standards based, service-oriented technical framework to support the education and research communities." The partnership's guiding principles espouse many of the values identified in the 2003 and 2006 DLF surveys, while situating them into a coherent structure:
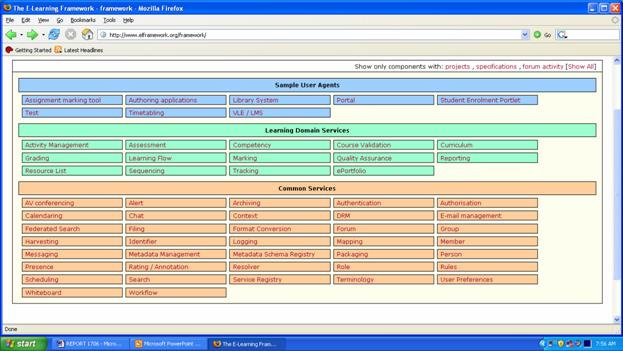
Taken together, these principles are international, collaborative, standards-based, platform independent, promote excellence through agreement on best practices, avoid high-level service duplication, encourage innovation, engage user communities, support both open source and proprietary implementations, and, are mindful of business practices. The initiative draws on the Australian e-Learning Framework (http://www.elframework.org/) and JISC's Information Environment (JISC IE) architecture to facilitate interoperability across education and research domains. McLean (2004) charts out the "evolving e-learning framework" and identifies a layer of common services, which he then places into a broader context by mapping them across different domains. This practical exercise demonstrates how a service-oriented approach to frameworks and architectures helps to identify common services, and could lead to shared technical development across multiple domains. Clicking on components in the framework links to relevant projects, specifications, and discussion forum comments. The JISC IE technical architecture "specifies a set of standards and protocols that support the development and delivery of an integrated set of networked services that allow the end-user to discover, access, use and publish digital and physical resources as part of their learning and research activities."
(http://www.ukoln.ac.uk/distributed-systems/jisc-ie/arch/).
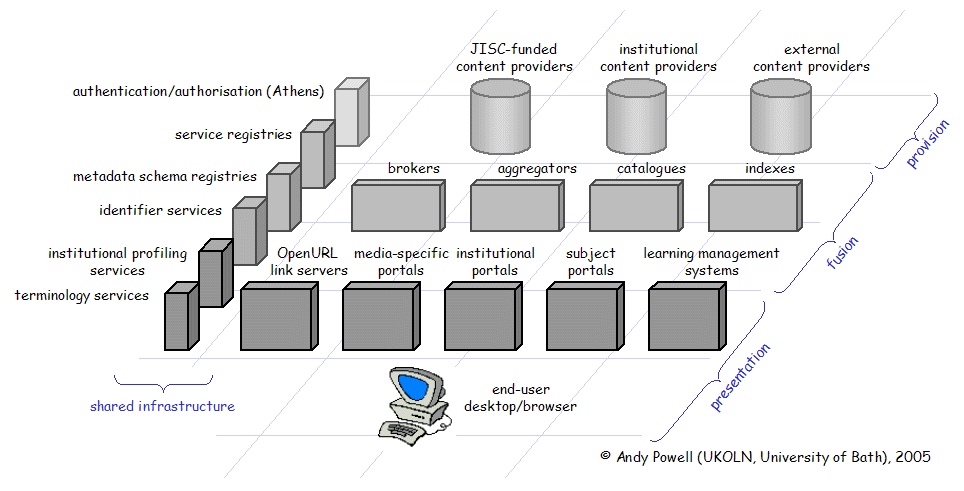
The user environment features a shared infrastructure of common services running across the presentation, fusion, and provision layers. JISC's IE service framework supports such activities as: [[7]]
2.1.2 Discipline-based Landscape Analysis[[8]]If the "Wheel of Fortune" scopes out a high-level e-framework and corresponding service-oriented architecture (SOA), then PerX, a pilot UK project in engineering, offers a model for producing a discipline-specific landscape analysis and corresponding specialized cross-archive search system. The PerX project compiled an inventory of existing and potential engineering repository sources, using Heery and Anderson's (2005) basic typology that first, distinguishes repositories with content from metadata-only repositories and secondly, classifies them by content type, coverage, primary functionality and target user group (http://www.icbl.hw.ac.uk/perx/sourceslisting.htm#broadlandscape).
Source: http://www.icbl.hw.ac.uk/perx/sourceslisting.htm#broadlandscape PerX then used the source listing as the basis for analyzing the position of repositories by content type (http://www.icbl.hw.ac.uk/perx/analysis.htm). The Table below gives a synopsis of the status of sources that support engineering preprints/postprints and technical reports.
Source: http://www.icbl.hw.ac.uk/perx/analysis.htm Engineering Digital Repositories Landscape Analysis, and Implications for PerX, Version 1.0 (MacLeod and Moffat 2005). The landscape analysis further identifies the information and communication needs of engineers and describes the complexity of the published engineering information landscape. Next, a pilot subject-based cross-archive search system was created, featuring the different repositories identified through the landscape analysis (http://www.engineering.ac.uk/). Other project deliverables include development of "advocacy materials," such as the excellent Web accessible document-"Marketing with Metadata: How Metadata Can Increase Exposure and Visibility of Online Content," and embedding PerX into virtual learning environments (http://www.icbl.hw.ac.uk/perx/deliverables.htm) . PerX has developed a model for analyzing needs and mapping them against resources that is readily adaptable to other disciplines. 2.2 Open Access Ascendant: Growth of OAI-compliant RepositoriesThe open access movement:
In the short span of time since "A Survey of Digital Library Aggregation Services" appeared, the open access movement has gained international momentum and engendered a multitude of commitments from major funding agencies, intergovernmental organizations, private and public foundations, university and library consortia, and publishers. Glancing back to September 2003, it is instructive to recall how much the situation has changed: [[10]]
The Berlin Declaration on Open Access to Knowledge in the Sciences and Humanities of October 2003, the third major public statement in support of open access, clinched the transition of open access (OA) principles from periphery to mainstream in the world of policymakers and digital library developers alike. While the three foundational declarations, (Budapest, Bethesda, Berlin), vary in nuance and domain, they share two complementary strategies for promulgating OA, namely, self-archiving (depositing scholarly articles in open electronic archives) and open access journals (either through the transition of existing, or creation of new journals). With 164 organizational national and international signatories as of May 2006, the Berlin Declaration continues to evolve through annual conferences and by following the "Roadmap" devised in 2004 to implement Open Access. This influential 10-step plan provides guidelines for raising awareness, developing organizational policies, creating a sustainable infrastructure and legal framework, supporting OA journals, and securing long-term organizational commitments. ROARMAP, the Registry of Open Access Repository Material Archiving Policies, (described more fully in section 4.1.4), maintained by EPrints.org at the University of Southampton, tracks policies and mandates worldwide, as recommended by the Berlin Declaration (http://www.eprints.org/openaccess/policysignup/). The case for institutional repositories (IR) as a "critical component in reforming the system of scholarly communication" (Crow 2002) and as "essential infrastructure for scholarship in the Digital Age" (Lynch 2003) is closely aligned, if not frequently indistinguishable from the OA movement. Arguments for institutional repositories as a vehicle for opening up access to research are available in:
As evident from the analysis of "OAI demographics" below, OA archives are operational in at least 46 countries. The "top 20" implementations, in terms of size, come from 11 different countries. In addition to OAI deployments in the U.S., U.K., Australia, and five European countries, Brazil, Japan, and Mexico have significant OAI deployments-and there is little doubt that India (Sreekumar 2006, Ghosh 2006) and China (Tansley 2006) will soon join this list. Many developing and transitioning countries view OA repositories as a launch pad capable of bringing indigenous research output into the international arena, increasing its visibility and impact, while also "building research capacity" (Chan et al. 2005). Concurrently, a growing number of high-profile international projects and networks are emerging, designed to cross the "digital divide" and deliver high-quality scientific literature equitably:
Two surveys carried out in conjunction with conferences held in 2005 and 2006 provide a wealth of information about IR and ETD (electronic theses and dissertations) deployments in Europe and the United States. In May 2005, representatives from 13 countries came together to discuss IRs under the co-sponsorship of the Coalition for Networked Information (CNI), the SURF Foundation of the Netherlands, and UK JISC. Two ensuing D-Lib Magazine articles discuss "Institutional Repository Deployments in the United States as of Early 2005" (Lynch and Lippincott 2005) and "Academic Institutional Repositories: Deployment Status in 13 Nations as of Mid 2005" (van Westrienen and Lynch 2005). While these articles provide useful overviews and preliminary data, the corresponding questionnaires also contain a wealth of information about country-specific deployments (van Westrienen 2005). Similarly, the JISC-SURF-CURL (Consortium of Research Libraries in the British Isles) sponsored "International Workshop on E-Theses" (Jacobs 2006a) has a corresponding compilation of country-specific responses about the status of ETD programs in 11 European countries. The DLF report draws on a handful of these country-specific examples, especially in the section pertaining to "Links in the Scholarly Communication Value Chain." 2.2.1 Enabling OA Technology PlatformsInstitutional repositories constitute one service model by which to achieve the Open Access agenda, and enabling applications such as DSpace and EPrints.org, are the open-source software technology platforms to realize this goal. [[11]] MacKenzie Smith notes that DSpace distinguishes itself from typical open source software projects in several ways:
DSpace (MIT), EPrints.org (University of Southampton), CDSware (CERN, Switzerland), Achimède (University of Laval), OPUS (University of Stuttgart), and Fedora (Cornell and University of Virginia), are international communities of practice, spawning innovation to meet the service needs of their user communities. [[12]] In effect, these systems are simultaneously service models-opening access to research information through self-archiving-and technology platforms-capturing, diffusing and archiving intellectual output; the two functions inextricably bound together. EPrints.org, for example, offers its users a menu of services including advising on policy matters; training; assisting with advocacy and IR promotion; importing legacy archives; customizing; hosting and maintaining the repository; and providing ongoing technical support. [[13]] A JISC-funded project, IRRA (Institutional Repositories and Research Assessment) is creating mechanisms to mesh DSpace and EPrints.org workflows with the UK's Research Assessment Exercise (RAE), which will move to a metrics-based methodology after 2008 (UK. HM Treasury 2006). RAE is a national assessment of the quality of research that informs the distribution of public research funds in the UK (http://www.rae.ac.uk/). Among other efforts, the DSpace and EPrints.org communities are mapping input options (item types) to match RAE output types (e.g., edited book, journal article, conference contribution). [[14]] Open source software developed by the Public Knowledge Project (PKP), led by the University of British Columbia and Simon Fraser University, facilitates the uptake of OA journals (via OJS, the Open Journal Systems) and conferences proceedings (via OCS, the Open Conference Systems). OJS is a "journal management and publishing system" that "assists with every stage of the refereed publishing process, from submissions through to online publication and indexing" (http://pkp.sfu.ca/). With a worldwide user community representing more than 550 journals, OJS supports the African Journals Online project (more than 200 titles) and the Brazilian Institute of Science and Technology Information (more than 80 titles). In addition to open source projects, a growing number of semi-proprietary and commercial vendors are offering IR services. [[15]] Thesedeveloped by the Public Knowledge Project (PKP), led by the University of British Columbia and Simon Fraser University, facilitates the uptake of OA journals (via OJS, the Open Journal Systems) and conferences proceedings (via OCS, the Open Conference Systems). OJS is a "journal management and publishing system" that "assists with every stage of the refereed publishing process, from submissions through to online publication and indexing" (http://pkp.sfu.ca/). With a worldwide user community representing more than 550 journals, OJS supports the African Journals Online project (more than 200 titles) and the Brazilian Institute of Science and Technology Information (more than 80 titles). In addition to open source projects, a growing number of semi-proprietary and commercial vendors are offering IR services. [[15]] These technology platforms also typically have OAI interfaces, facilitating the exposure and harvesting of metadata. Bepress (Berkeley Electronic Press) licenses its repository software technology to ProQuest Information and Learning. Known as Digital Commons, ProQuest registers its client repositories (as of May 2006, 50 institutional and consortial customers) with OAIster and also manages data transfer to other third-party services and indexes such as Google and Yahoo!Search. The New England Law Library Repository (http://lsr.nellco.org/) uses Digital Commons/bepress software to aggregate research papers from the 25 member institutions in the NELLCO consortium. Similarly, COBRA: the Collection of Biostatistics Research Archive, is a bepress subject repository of prepublication biostatistical materials contributed by 13 institutions (http://www.biostatsresearch.com/). Bepress's award-winning "quasi-open access" aggregation of journals, IR contents and subject-based archives, ResearchNow (http://researchnow.bepress.com/), is discussed in section 4.2.11. 2.2.2 OAI Demographics 2006It is possible to formulate a composite picture of OA deployments by examining data from several OAI and OA registries and databases. As of May 2006, the University of Illinois OAI-PMH Data Provider Registry lists nearly 1,050 active OAI-compliant repositories (data providers)-or five times the estimated number of deployments two and a half years ago. As explained more fully in section 4.1.1, the UIUC registry strives to be comprehensive and deploys a systematic multi-faceted approach (that goes beyond self-registration) to achieve the goal of completeness. Meanwhile data from two other sources, ROAR (Registry of Open Access Repositories) and OAIster, (both described in section 4.1), affords an in-depth comparison of the geographic distribution and size of OA/OAI repositories. As of mid-March 2006, ROAR listed 640 repositories and OAIster, 597, representing 46 countries altogether.
ROAR
OAIster
Additional OAIster data about Repositories in the United States OAIster harvests from repositories located in 38 different states. Twelve states have no records, unless they are represented among the ten repositories with multi-state services (accounting for some 240,000 records). States without any representation in OAIster include: Arkansas, Delaware, Idaho, Maine, Missouri, Montana, New Hampshire, North Dakota, South Dakota, Vermont, West Virginia, and Wyoming. In terms of the number of items in the 223 US repositories represented in OAIster:
Top 20 Repositories in ROAR and OAIster While quality and quantity are not synonymous, critical mass is important and the sheer number of records in a repository indicates an area of concentrated activity. Again, a comparison of the top 20 archives in terms of record count in ROAR and OAIster reveals both commonalities and differences. When comparing ROAR and OAIster data, it is important to bear in mind key differences in their harvesting parameters and purpose. ROAR relies on self-registration and focuses on e-print archives, especially those that use GNU EPrints software. Meanwhile, OAIster harvests from OAI-compliant collections of all media types (including images and datasets) and includes some repositories that restrict use to licensed users (e.g., Institute of Physics journal articles). Secondly, ROAR harvests metadata records without requiring them to point to full-content digital objects (i.e. metadata only), whereas OAIster only harvests those records with full-content representation. Third, ROAR only has OAI record counts for the subset of its 640 archives harvested by Celestial (480 repositories). In contrast, OAIster has item counts for all 597 of its repositories. Fourth, there are differences in whether they harvest some or all of the available records from any given service. For example, OAIster recently began to harvest OSTI's technical reports directly rather than through the NSDL aggregation, thereby causing NSDL to tumble off OAIster's list of 20 largest repositories, and to propel OSTI onto it. Fifth, the actual harvests take place at different intervals so counts may lag behind at any given time. For example, RePEc (Research Papers in Economics) merged records from the American Economic Association's working paper collection into its aggregation in March 2006, causing it to shoot up in size from around 50,000 to more than 130,000 records. When this Top 20 snapshot comparison was undertaken, it is probable (given its low record count) that ROAR had not yet harvested from the RePEc enlarged collection. Finally, the record counts within either service include an undetermined number of duplicates. The complete top 20 list is available in Appendix 4. The summary of findings follows:
In conclusion, ROAR and OAIster are useful tools for analyzing patterns in OAI adoption and growth. As discussed more fully in section 4.1.4, ROAR tracks the growth of repositories at the individual and composite level. It also makes statistics available by country, archive type and software in use. OAIster sends historical data to the UIUC registry on a monthly basis, making it possible to view growth data by repository; however, it is not accessible in a very user-friendly form. OAIster also provides underlying data upon special request. As the above exercise demonstrates, it would be of great benefit to the research community if the UIUC registry and/or OAIster made their database management information Web accessible in user-friendly (downloadable, malleable) form. The data begs for wider exploitation and analysis to gain a better understanding of OAI implementations throughout the world. 2.3 "The 'Amazoogle' Effect"In 2003, "Amazoogle" was not in our vocabulary (Dempsey 2004) or integral to the scholarly Zeitgeist. Google Scholar (http://scholar.google.com/ ), Google Books (http://books.google.com/), and the Google 5 (http://books.google.com/googlebooks/library.html) had not launched. Amazon's A9 (http://www.a9.com/), Flickr (http://www.flickr.com/about/), del.icio.us (http://del.icio.us/about/), and Connotea (http://www.connotea.org/faq) were fantasies. WorldCat was not "open" (http://www.oclc.org/worldcat/open/default.htm), nor accepting user-contributed content (http://www.oclc.org/productworks/wcwiki.htm). Recognizing the undeniable magnetism of such enterprises, Dempsey (2005) urged the library community to re-consider the nature of library services in the context of these "major web presences which have become the first-and sometimes last-resort of research for many of our users." He evaluated the typical library user's experience against a set of common attributes inherent in popular Web services:
2.3.1 What Recent User Studies RevealOCLC's extensive international survey of information consumers portrays a sobering reality for libraries: only one percent of respondents begin an information search on a library Web site-84 percent use search engines first; moreover, 90 percent of respondents are satisfied with their most recent search for information using a search engine. Rather than speed, the quality and quantity of information returned in the search process is of primary importance. Search engines fit the information consumer's lifestyle better than physical or online libraries. While college students report the highest rate of library use and broadest use of library resources. both physical and electronic, only 10 percent indicated that their library's collection fulfilled their information needs after accessing the library Web site from a search engine. (Excerpted from De Rosa et al. 2005, 6-2, 6-3). A wide-ranging survey of faculty attitudes and behaviors in using digital resources in undergraduate humanities and social sciences education found that "the most cited reasons for not using digital resources was that they simply do not mesh with faculty members pedagogies" (Harley et al. 2006, 180). The authors exhort: We should not expect faculty, who we can assume know more about teaching their subject than non-specialists, to shoehorn their approaches into a technical developer's ideas of what is valuable or the correct pedagogical approach. Tools and resources need to be developed to support what faculty do (Ibid).In terms of integrating resources into learning management systems, the findings mirror those of the 2003 DLF survey of aggregations and DLF's Scholarly Advisory Panels (DLF 2004 and 2005):
When reviewing existing OAI services (such as OAIster) in 2005, DLF's Scholarly Advisory Panel also reiterated many of the shortcomings identified in the 2003 DLF survey. They underscored the importance of understanding the context of retrieved results and the need for authoritative collection and item-level descriptions. If not all records carried full descriptive metadata, they wondered: what proportion of the database is queried when search delimiters such as, subject, date or author, are invoked? In viewing results, scholars frequently could not distinguish items from collections, nor could they easily identify the collection to which an item belonged. They were critical of the search functionality, which gave precedence to institutions-over collections and subjects-when retrieving or sorting results. As a default, they preferred a basic search box, with a layered option for advanced search queries. They also wanted brief record results returned first or the option of letting users specify whether they wanted brief or full-records returned. Turning to more advanced functionality, scholars hoped that OAI services would support:
2.3.2 Creating User-Focused ServicesIn an effort to meet user expectations brought to light in these and similar studies, the University of California Libraries set out to re-examine the way in which it delivered bibliographic services to users. The ensuing report identifies a desirable set of enhanced search and retrieval capabilities to apply throughout the University of California library system. The UC list parallels the types of enhancements aspired to, or implemented by the services under review here:
The California Digital Library's Metasearch Initiative (described in section 4.5.4) illustrates an infrastructure that will bring together the panoply of locally held, centrally harvested, and externally located resources under a common framework and present them to the user in the context of their needs through different portals (see figure 07 and figure 45). At a national level, the NISO Metasearch Initiative brings together the various stakeholders-content providers, software providers and implementing libraries-in an effort to develop standards and best practices that will enable cohesive search and retrieval across disparate resources and platforms (Hodgson, Pace and Walker 2006). Many, one is tempted to say all, of the services under review in this report demonstrate ways in which user-driven services are increasingly integrated into the overall scholarly information environment. Examples abound, ranging from direct access to full content (OAIster) and disciplinary pathways (NSDL) to peer-review of resources (BEN, DLESE, MERLOT, NINES); expert commentary (CiteSeer, NINES, NSDL, Perseus, SouthComb); and recommender systems (CDS, Scirus, Perseus). Moreover, as is the case with CDL, the new architectures deployed or under development at such services as NSDL, NEEDS, NINES, and Intute aim to enable a customizable, context-sensitive user experience. It is too early to know how these (mostly) nascent efforts will fare or to determine if scholars will find the resources sufficiently valuable and the tools easy enough to use to integrate them into their crowded daily routines. Of course, personalization, visualization, and social networking tools are only valuable if the content and digital resources themselves are high quality and compatible with scholars' instructional or research methods. |


{kind=link}