

The Making of America II Testbed Project: A Digital Library Service Modelby Bernard J. Hurley,John Price-Wilkin, Merrilee Proffitt, Howard Besser December 1999 Copyright 1999 by the Council on Library and Information Resources. No part of this publication may be reproduced or transcribed in any form without permission of the publisher. Requests for reproduction should be submitted to the Director of Communications at the Council on Library and Information Resources. -ii- On May 1, 1995, 16 institutions created the Digital Library Federation (additional partners have since joined the original 16). The DLF partners have committed themselves to "bring together -- from across the nation and beyond -- digitized materials that will be made accessible to students, scholars, and citizens everywhere." If they are to succeed in reaching their goals, all DLF participants realize that they must act quickly to build the infrastructure and the institutional capacity to sustain digital libraries. In support of DLF participants' efforts to these ends, DLF launched this publication series in 1999 to highlight and disseminate critical work. -iii- Bernard J. Hurley is the Berkeley Library's director of library technologies. He formerly served as the director for library systems, beginning in 1981, and has worked in the field of library automation for the last seventeen years. While at Berkeley, he has played a central role in developing the GLADIS System, Berkeley's online catalog, catalog maintenance, authority control, and circulation system, and its access to the Berkeley Campus Information Network. John Price-Wilkin is head of Digital Library Production Services (DLPS) at the University of Michigan, a position he has held since its inception in 1996. A federated organization, DLPS is responsible for mounting and maintaining licensed content for the University of Michigan and several other universities, and for text conversion projects such as the Making of America. Among the units in the DLPS is the University of Michigan's Humanities Text Initiative, an organization responsible for SGML document creation and online systems, which Price-Wilkin founded in 1994. Merrilee Proffitt is director of digital archive development at the Bancroft Library, University of California at Berkeley. She has worked for the Berkeley Library since 1988. Ms. Proffitt has a broad range of experience in digital library projects, especially those relating to special collections. She has expertise in database development, text encoding, and metadata, and has managed a range of digital imaging and text encoding projects. Howard Besser is an associate professor at UCLA's School of Education and Information, where he teaches and does research on multimedia, image databases, digital libraries, Web design, information literacy, distance learning, intellectual property, and the social and cultural impact of new information technologies. Besser has been involved with the Dublin Core metadata standard since its inception, and has recently been promoting the extension of metadata activities beyond the "discovery" orientation of the Dublin Core. He was an organizer of a DLF/NISO meeting to develop metadata standards for digital images, and was member of the metadata committee of the US/European Community Digital Collaboratory, laying out directions for future digital library research. -iv- No work is produced in a vacuum. The authors would like to thank the following individuals who offered guidance and wisdom to this project: Caroline Arms, Rick Beaubien, Robert DeCandido, Dale Flecker, Rebecca Graham, Susan Hamburger, Bonnie Hardwick, John Hassan, Peter Hirtle, Tim Hoyer, Dan Johnston, Sue Kellerman, Heike Kordish, Steven Mandeville-Gamble, Jerome McDonough, Ralph Moon, Sue Rosenblatt, Kathlin Smith, Christie Stephenson, and Ann Swartzell. Many thanks are also due to the institutions that participated in the MoA II project. Without the expert staff working on the project, none of this would have been possible. Finally, we owe a debt of gratitude to the organizations that funded the MoA II project itself. Thanks are due to the Digital Library Federation, for funding the research phase of the MoA II project, and to the National Endowment for the Humanities for funding the testbed phase of the project. -v-
-vii- Metadata is what makes it possible to locate, provide access to, navigate, and manage digital information in diverse forms. Ongoing work on metadata definition has been critical to the development of digital libraries. The extension and refinement of the Dublin Core, efforts to establish a set of technical metadata elements for images, and other initiatives are expanding the application and usefulness of metadata. Echoing earlier published works, this paper emphasizes the importance of metadata in those developments. The work of the Making of America II Testbed Project reported in this paper represents a singular effort in digital library development to find ways to provide access to and navigate a variety of materials. In this endeavor, a digital library service model has been defined that encapsulates the interaction of digital objects (including their metadata), tools, and services based on principles of object-oriented design. In developing the digital library service model, project participants did extensive work to identify and define the structural and administrative (often referred to as technical) metadata elements that are crucial in the development of the digital library services and tools. The Digital Library Federation's support of this work was driven by two of its program priorities: to stimulate the development of a core digital library infrastructure and to organize, provide access to, and preserve knowledge. This publicationDLF's thirdfurthers the interests of the Federation and its members by presenting one possible model of digital library development for review and discussion within the DLF community and the digital library community at large. Rebecca Graham -viii- Drawing on the example of the Making of America II Testbed Project, this report examines an object-oriented approach to digital library construction, the collection of structural and administrative metadata, and the development of tools to assist scholars. It is divided into four main parts. Readers should approach the report part by part, focusing on those areas of particular interest. -1- Executive SummaryThe Making of America Testbed Project, coordinated by the Digital Library Federation (DLF), is a multiphase endeavor. Its purpose is to investigate important issues in the creation of an integrated but distributed digital library of archival materials (that is, digitized surrogates of primary source materials found in archives and special collections). Drafted during the MoA II planning phase, this report identifies a starting point for the testbed that is being created in the production phase of this project, which is funded by the National Endowment for Humanities. The library community has a distinguished history of developing standards to enhance the discovery and sharing of print materials: they include, for example, MARC, Z39.50, and interlibrary loan protocols. This leadership continues today, as libraries create new best practices and standards that address digital collections and content issues. The primary goal of this report is to open a dialogue about digital library standards, specifically, to discuss any new best practices and standards that will be required to enable the digital library to meet traditional collection, preservation, and access objectives. This report asks the question, "How can we create integrated digital library services that operate across multiple, distributed repositories?" Existing standards and best practices clearly play an important role in answering this question. However, this report and the MoA II Testbed Project raise a new area of discussion that goes beyond the discovery of a digital object and address how it is handled. The report and the testbed focus on the need to develop standards for creating and encoding digital representations of archival objects (for example, a digitized photograph or a digital representation of a book or diary). If tools are to be developed that work with digitized archival objects across distributed repositories, these objects will require some form of standardization. This report begins the discussion of digital object definitions by developing and examining metadata standards for digital representations of a variety of archival objects, including text, digitized page images, photographs, and other forms. For the purposes of this report, there are three types of metadata: descriptive, structural, and administrative. Descriptive metadata are used to discover the object. A researcher may use descriptive metadata to limit a search by title and author in an OPAC or other database. Structural metadata define the object's internal organization and are needed for display and navigation of that object. For instance, structural metadata may contain information about the number of pages an object contains and what order they should be viewed in. Administrative metadata contain -2- the management information needed to keep the object over time and to identify artifacts that might have been introduced during its production and management. For example, administrative metadata indicate when the object was digitized, at what resolution, and who can access it.The project testbed proposes to use existing descriptive metadata standards, such as MARC records and the Dublin Core, as well as standards that incorporate both descriptive and structural metadata, such as the Encoded Archival Description (EAD), to help the user locate a particular digital object. This report proposes defining new standards for the structural and administrative metadata needed to view and manage digital objects. At a higher level, the report proposes a Digital Library Service Model in which services are based on tools that work with the digital objects from distributed repositories. This approach borrows from the popular object-oriented design model. It defines a digital object as encapsulating content, metadata, and methods. Methods are program code segments that allow the object to perform services for tools (for example "Get the next page of this digital diary"). Unlike other models, the Digital Library Service Model includes methods as part of the object. The report also identifies several archival digital object classes that are being examined as part of the MoA II project, including photographs, photograph albums, diaries, journals, letterpress books, ledgers, and correspondence. One of the objectives for the testbed is to develop the tools that display and navigate these MoA II objects, some of which have complex internal organization. Therefore, another goal of this report is to identify the structural metadata elements that are needed to support display and navigation and ensure that they are included as part of the digital objects. Finally, this report begins to examine the methods (program code) that could be included with each class of object. After the library and archival communities have reviewed this report, MoA II participants will incorporate reader feedback into the development of digital object definitions for the classes of materials to be examined in the MoA II testbed. These definitions will specify how to encode the content, metadata, and methods as part of the object. An important goal of the project is to use the testbed to investigate the advantages and limitations of these definitions and stimulate discussion of standards for digital library objects and best practices for digitizing archival materials. This discussion must include the project participants, DLF members, and representatives of the wider community. In addition, the project will contribute to the DLF Architecture Committee's ongoing discussion of distributed system architectures for digital libraries. The MoA II testbed will give the library and archival communities a tool they can use to test, evaluate, and refine digital library object definitions and digitization practices. It is expected that these discussions will move the archival and library communities closer to a consensus on standards and best practices in these areas. -3- PART I: PROJECT BACKGROUNDIn 1998, the DLF, working with staff of the University of California (UC) at Berkeley, developed a grant proposal that requested support to create a testbed for its Making of America II project. The objective of the testbed was to move the DLF members and the wider library and archival communities closer to the realization of a national digital library by addressing several issues that are critical to this goal. UC Berkeley submitted the proposal to the National Endowment for the Humanities (NEH), which awarded funding. The proposed project team included individuals associated with UC-Berkeley and four other DLF member institutions: Cornell University, the New York Public Library, Pennsylvania State University, and Stanford University. As described in the proposal, the MoA II testbed is designed to provide a means for the DLF to investigate, refine, and recommend metadata elements and encodings used to discover, display, and navigate digital archival objects. The DLF expects that the MoA II testbed will generate a working system for investigating metadata problems and for discussing, testing, and refining different solutions. The project will give DLF members information that can be used to create the necessary standards or recommendations for best practices for each research area. The project will also be of value to the library and archival communities as a whole because it will advance discussion of the nature of the digital library and move libraries toward a consensus. The project has three phases: planning, research and production, and dissemination. The planning phase was funded by the DLF. During the research and production phase, which is funded by the NEH and is currently under way, theories developed in the planning phase are being tested. In the dissemination phase, the project will share its tested ideas and practices with the broader community. Planning Phase (October 1997-May 1998)Participants in the planning phase decided that the MoA II Testbed Project must engage scholars, archivists, and librarians interested in access to the digital materials represented in the project, as well as metadata and technical experts. The following four activities were recommended:
Research and Production Phase (May 1998-March 2000)The MoA II testbed would be used to investigate, refine, and enhance the working definitions of administrative and structural metadata, and the important behaviors of archival objects. The testbed project has the following goals, defined during the planning phase:
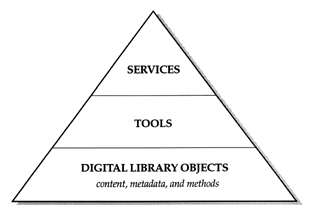
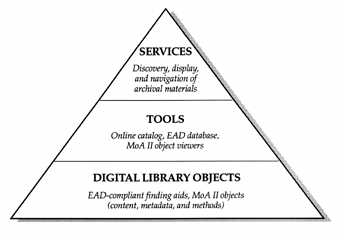
Dissemination Phase (Summer 2000)When the research and production phase has ended, the MoA II Testbed Project will seek funding for an invitational seminar at which project results will be reviewed. Participants will include digital library experts, archivists and special collections librarians, scholars, computer scientists, museum professionals, and others who have participated in developing the EAD protocols, are engaged in similar work, or have appropriate expertise. At the end of this phase, project results will be disseminated, practices established will be refined, as necessary, and an agenda for further community review will be formulated. -5- PART II: THE MOA II DIGITAL LIBRARY SERVICE MODELOverviewThe digital library service model developed for the MoA II Testbed Project has three layers: services, tools, and digital library objects (fig. 1). In this model, services are provided through tools that discover, display, navigate, and manipulate digital objects from distributed repositories. This report also proposes a digital object model that fits within the service model. The object model defines digital objects, which are the foundation of the service model, as an encapsulation of content, metadata, and methods. Each of the layers in the model may be described as follows. Services LayerThis layer describes the services to be provided for a specific group of users. Because the MoA II Testbed Project relates to scholars' use of archival materials, these services could include the discovery, display, navigation, and manipulation of digital surrogates made from these collections. The specific service model used in this project follows the standard archival model; that is, materials can be discovered via USMARC collection-level records in a catalog. The catalog records can link the user to the related finding aid that describes the collection in more detail, and the finding aids can link to individual digitized archival materials. The services layer contains a suite of tools to support the needs of a particular group of users. For example, scholars would be comfortable using sophisticated electronic finding aids to locate and view digital archival materials such as photographs or diaries. However, fifth-graders, with less rigorous information needs, may require simpler tools to discover and view these items.
-6- Tools LayerThis layer contains the tools that serve the user. The MoA II tools consist of the following:
Digital Library Objects LayerThis layer contains the actual digital objects that populate distributed network repositories. Objects of the same class share encoding standards that encapsulate (that is, include) their content, metadata, and methods. Separate classes of digital objects could be defined for books, continuous-tone photographs, diaries, and other objects. A Model for Digital Library ObjectsDigital library objects form the foundation of the digital library service model. It is now possible to create a digital object model for these objects that will fit within the overall service model. Adding Classes and Content to the MoA II Object ModelThe MoA II object model defines classes of digital archival objects (for example, diaries, journals, photographs, and correspondence). Each object in a given class has content that is a digital representation of a particular item. The content can be digitized page images, ASCII text, numeric data sets, and other formats. The following are examples of three classes of archival objects and their content format:
-7- representation of a particular archival item of that class.Adding Metadata to the MoA II Object ModelFor the purposes of this discussion, metadata are considered as separate from content. Metadata are data that in some manner describe the content. The DLF systems architecture committee has identified three types of metadata:
The distinction among the three types of metadata is not absolute. For example, chapters are part of the structure of a book, but chapter headings may be indexed to aid in the discovery of the item, thus filling one of the roles of descriptive metadata. In fact, the text of a book itself could be indexed and used for discovery. Adding Methods to the MoA II Object ModelSeveral concepts used in this paper, including methods, originate from object-oriented design (OOD). Object-Oriented Design as Part of the Object ModelThe popularity of OOD is evident in the widespread use of related programming languages such as C++ and Java. Some of the reasons for this popularity also make OOD an attractive addition to the digital library service model. In particular, OOD actually models users' behaviors, making it easier to more accurately translate their needs -8- into system applications. This advantage will be discussed in more detail later.Object-oriented design has another important advantage. In OOD, a digital object conceptually encapsulates both content and methods. Methods are program code segments that allow an object to perform services for tools. These methods are part of the object and can be used by developers to interact with the content. For example, a developer can ask a digital book object named Book1 for page 25 by executing that object's get_page() method and specifying page 25. This method call may look something like Book1.get_page(25). The most important advantage of making methods part of the object may be that these basic program segments do not then have to be reinvented by every developer. [2] Instead, the developer can have the tool ask the object's existing method to perform the needed work. This makes the development of new tools faster and easier. Since tools directly support the end user in this model, their development should be encouraged. Defining the Difference between Behaviors and MethodsOne great advantage of the object-oriented design approach is that it models users' behavior with methods. There is a clear distinction between user-level behaviors and methods. The word behaviors relates to how users describe what tools can do for them. For example, "Zoom in on this area of a photograph," "Show me this diary," "Display the next page of this book," or "Translate this page into French." The word methods refers to how system designers describe what tools can do for a user. One important reason for distinguishing between behaviors and methods is to establish a process that will enable libraries to engage their users in a dialogue about what services and tools they require, down to the behaviors they need in each tool. Software engineers can then map the user behaviors into sets of methods that are required to perform the necessary functions. The line between behaviors and methods represents the transition from user requirements to system design. The following examples of user-level behaviors might be relevant an to item in the digital library class "diary":
-9- A short example may help illustrate the mapping that occurs between behaviors and methods. Imagine a user-level behavior that is described as "Show me this diary." The tool executing this request could use object methods to (1) fetch the table of contents and (2) fetch the first page of the diary. The tool would then use its own methods to display the table in one browser frame and the first page in another frame. Methods as Part of the MoA II Digital Object ModelMethods now become part of the object model. At this point, it is important to note the close relationship between methods and metadata. In most cases, the methods require that appropriate metadata be present. [3] The MoA II object model includes methods that are conceptually encapsulated, along with content and metadata, within an object of any given class, where the methods are used by tools to retrieve, store, or manipulate that object's content. Methods often need the object's metadata to perform their functions. Building MoA II Archival ObjectsThe final step in building a digital library object is to encapsulate the methods, metadata, and content (data) into a digital library object. [4] The metadata and content must be encoded in a standard manner for objects in a given class. This encoding is required so that the methods defined for each class can work across all objects in that class. -10- SummaryThis report proposes a digital library service model for the MoA II Testbed Project in which services are based on tools that work with the digital objects from distributed repositories. This model recommends that libraries begin by defining the services they need to provide for each audience they support. Next, they must define the tools needed to implement these services. This process should include the identification of user-level behaviors for the tools, that is, what the tools do as required by the users. This report also proposes a digital object model that fits within the overall service model. The object model describes digital objectsthe foundation of the service modelas an encapsulation of content, metadata, and methods. Different classes of objects exist (for example, diary or photograph), and the content of each object may be text, digitized page images, photographs, or another format. The object also contains metadata of three types: (1) descriptive metadata used to discover the object; (2) structural metadata that define the object's internal organization and are needed for display and navigation of that object; and (3) administrative metadata that contain management information (such as the date the object was digitized, at what resolution, and who can access it). The digital object definition borrows from the popular OOD model and includes methods as part of the object. Methods are program code segments that allow the object to perform services for tools. Footnotes1. Structural metadata exist in various levels of complexity. The diary example above represents a rich structure that may be created for an important work and would include a transcription of the digitized handwritten pages. The structure of the diary could be encoded in this transcription, and the structural metadata could be extracted from it. At the other extreme, a diary could exist with only enough structural metadata to turn the pages. 2. This digital object model is only conceptual. Complete objects made up of metadata, data, and methods do not sit in a repository waiting for use. Instead, they are created as needed. That is, the parts of the objects (methods, metadata, and content) are assembled from different areas of persistent store located anywhere on the network. Using the object-oriented model does not require a repository to use specific object technologies such as object-oriented databases. Relational databases, for example, could be used for the persistent storage. 3. The methods that are part of an object tend to be those that are most used across sets of tools. Tools themselves will have methods and therefore will need access to the metadata and content of the objects. Project staff expect that every object will have a base set of methods that can provide the tools with any metadata or content that is required. 4. While the content and metadata must be encoded in a standard manner, they do not necessarily have to be stored together nor do the three different types of metadata need to reside together because objects only come into existence as needed. Therefore, the object can be assembled virtually from persistent storage when required. -11- PART III: IMPLEMENTING THE MOA II SERVICE MODELSelecting Digital Archival ClassesProject staff selected a group of object types and classes from the materials suggested by institutions participating in the MoA II project. These archival object types are the core of those examined in this project. The number of items selected was limited to facilitate completion of the testbed within the project time frame. The object types and classes selected were as follows:
-12- because they offer the project important challenges in terms of the behaviors needed to view, navigate, or manipulate them. The complex structure of photograph albums, for example, requires that users be able to see individual photographs, a photograph with its caption, photographs and captions in the context of pages, and pages in the context of an entire album. With diaries and journals, users may want to see individual entries or to jump from one entry to another or from an index to an entry. Diaries and journals also raise the issue of individual page scans that do not correspond with the logical structure of the document. For example, entries frequently end in the middle of a page and a new entry begins on that same page. In addition, when different levels of metadata are available, these materials allow for display and navigation experiments. For example, a minimal digital diary might consist of a series of page images with only a base set of behaviors that can be implemented (for example, "turn to the next page"). A richer digital diary may have encoded text transcribed that allows for a variety of tool behaviors for each page image. For example, the tools could display a table of contents for the diary, jump to a particular page or entry, or search for text strings. The structure of letterpress books and ledgers offers the potential for interaction between indexes in a document and its individual entries or parts. The project is also exploring how the structure of these items differs from those of diaries and journals. While ledgers, letterpress books, journals, and diaries are different classes from an archivist's point of view, they may be quite similar from a structural metadata perspective.The MoA II testbed will give participants and the broader archival and library communities a chance to evaluate different practices for encoding the relationships among objects. In particular, it will help the community understand the advantages and drawbacks of using these practices based on how tools implement different behaviors for each practice. For example, a series of correspondence could be scanned and:
-13- through linking to other objects or embedding other objects inside itself.While the concepts of compound, linked, and embedded objects are not new, the MoA II testbed will give archivists and librarians a tool with which to better evaluate options for digital archival objects, particularly in the context of distributed repositories. The MoA II testbed will give the DLF and the wider community an opportunity to create objects using all the practices listed above. It will also allow for the evaluation of each practice to identify how tools can best use each practice to meet audience needs. MoA II Testbed Services and ToolsThe digital library service model described in Part II of this report is a three-tier model consisting of services, tools, and digital objects. The MoA II testbed is implementing the standard archival model within the digital library service model. That is, USMARC collection-level records in a catalog will link to their related finding aids, which will link to the digital archival objects in that collection. The top tier in the model (see fig. 1) is a services layer composed of suites of tools that focus on supporting particular groups of users (such as scholars, undergraduates, or K-12 students). An archivist, for example, would require different tools for the discovery, display, navigation, and manipulation of digital archival objects than would a fourth-grade student. Initially, the MoA II Testbed Project is focusing on general services for scholars who are using the classes of digital objects selected for the project. Future research projects could include developing service models for novice users or customized services for specialized scholars (such as what is envisioned for the Digital Scriptorium Project). The suite of tools to be developed in the MoA II testbed will initially include the following:
The MoA II testbed implementation of the digital library service model is shown in figure 2. -14-
Behaviors and Methods"What Tools Do"Part II of this paper introduced the concepts of behaviors and methods in the context of object-oriented design. This section outlines those concepts in detail. DefinitionsThe digital library service model defines behaviors as the ways in which users describe what tools do for them. Engaging users in a dialogue about behaviors can help identify user needs in terms of the functions performed by tools. System designers can then map these user-level behaviors into methodsdefined as discrete segments of program code that execute operations for tools. The translation from behaviors to methods represents the transition from defining user needs to system design. In many cases, high-level methods in a tool have the same name as a user-level behavior. The ability to create methods that model a user's desired behaviors is one of the strengths of object-oriented design. This definition of methods will be applied to specify the range of activities that should be supported through the metadata described elsewhere in this paper. In an object-oriented model, the methods are embedded in the digital objects; digital objects reveal methods to tools interacting with them. Many repositories in the MoA II environment will not deploy object-oriented models; in this case, the methods will be made available to tools that interact with repositories, rather than with the digital objects themselves. Nevertheless, this model is likely to be helpful both in conceptualizing the nature of the tasks supported and in preparing for a type of digital library that may scale more effectively than current architectures. The digital library should support methods that both common and exceptional operations users expect to perform with the digital -15- objects. For an image collection, a method might be facilitating a pan or zoom on a portion of an image or providing an enlargement of an image. For an encoded diary, the method might involve providing the tool information about levels and types of organization (such as "One volume, including 128 dated entries, an itinerary, and a list of contacts with addresses"). The encoded diary's methods might also yield both simple (next entry, previous entry) and complex navigation (for example, "Locate the first dated entry in November 1884;" "Find entries where dates are separated by more than 10 days"). Although no object or repository would be required to support the full range of methods, the model proposed here will facilitate the development of increasingly sophisticated tools that can be scaled for use on a growing body of complex archival objects.Contexts and ConstraintsThe methods of the digital library reside in tools that may be client-based or server-based, depending on the state of technology. The location of that method (that is, with the client or server) may shift with changes in technology. For example, widespread adoption of an image client that supports progressive transmission of image data might shift image processing from server to client, thereby expediting the processing and reducing the load on the server. However, an interim measure might rely on a server-based compression-decompression process in which the server can generate pan or zoom views at the user's request in real time. This relieves the client of processing responsibility and shifts the work to the server. Just as the methods may move from client to server and back again, they will also separate into specialized functions or merge into high-level, multifaceted functions. For example, print and display might be different methods, with one object optimized for screen display and another optimized for printing. In Adobe Acrobat, for instance, display and print are merged in the same tool. If it is argued that Acrobat handles display poorly, a clearer separation of these two methods might be advisable. By separating the methods conceptually, it is possible to assess the applicability of the tool in the service of the method. High-level methods frequently consist of a series of calls to lower-level methods. For example, because print is a behavior that most users require in a tool, most tools will have a high-level method expressed something like "print(a1,a2aN)." The information inside the parentheses represents arguments that tell the method what object to print, which printer to use, and so on. The print method would execute a series of lower-level methods. It may, for example, ask an object to deliver its content in a format suitable for printing by executing the proper method. Next, it may execute an operating system-specific method that sends (spools) the formatted content to that particular printer. Some methods are applicable to all or most objects, while others may need to be finely tailored to the type of objectso finely tailored, -16- in fact, that they rely on entirely different functions or primatives. An obvious example is the difference between navigation of pages and navigation of portions of an image. A system that navigates a bound book might use operations such as "Display next page" or "Show page list." A system that navigates a continuous-tone image might use operations such as "Display 200 by 200 pixels centered on coordinates X by Y."The following sections define methods that are central to creating the digital library. When possible, the descriptions are sufficiently generic to apply to a variety of objects; in some cases, the methods described are specific to some data types. [5] NavigationGeneral NavigationNavigation consists of a request, a receive, and a display action. Each action interacts with a reference to objects or metadata for objects rather than to the objects themselves. A significant portion of the user's activity is navigation. For example, the user who finds a digital scrapbook in a repository may request a table of contents. Depending on the extent to which the book was processed, that table of contents may consist only of a stream of page references or of a nested list of chapter and section headings. In navigating the scrapbook, the user's navigation tool will
The user expects a series of references, not actual delivery of the objects, which will not be sent until requested. Navigation also depends on an understanding of relationship primitivesparent, child, and siblingthat are the generic references a tool uses to facilitate navigation. The navigation method is affected by the tool requesting, receiving, and displaying the parents, children, or siblings of an object that the user has located. For example, to navigate a fully encoded and logically organized scrapbook, a navigation tool might request references to the first-level children in the scrapbook. A user would be presented with a list that looked like the following:
-17- Each major heading may be presented as a link for further expansion, perhaps offering second-level headings to the user (for example, annual groupings of entries in the dated entries section). A threshold setting in the navigation tool may instruct the repository to send no more than N references at a time. The repository would make a determination that, for example, all first-level and second-level headings fit within the threshold (providing the annual groupings within the dated entries section at the same time it provides the four major headings listed above). At some point, the children of a given parent will be links to the objects themselves. In the scrapbook example cited earlier, the user could be presented with a navigation list of dated entries, any of which could be selected for display. Types of object references vary, depending on the type of resources, the amount of funding available to process the materials, and the programmatic or other purposes of an initiative. Examples include conceptual and structural references (as in the scrapbook example), simple page lists (such as Project Open Book and the University of Michigan Making of America sites), and pages of thumbnail representations of larger format images.Image NavigationIn contrast to the generic form of navigation just discussed, image navigation uses image-specific information. Systems that display image information need information analogous to that used in geographic references; for example, X and Y coordinates, along with dimensions of the portion of the image to be displayed. Increasingly, tools for image management and manipulation use segmentation to optimize the relatively confined space of a video display as well as other resources in short supply (such as network capacity, memory, and CPU capacity). Some of these technologies are primarily server based, while others shift responsibility to the client. Wavelet compression, for example, allows a repository to store an extremely high-resolution image and generate lower-resolution versions and subsets in real time, at the request of the user or an intermediary. Another approach, implicit in tools or formats such as JPEG Tiled Image Pyramid (JTIP), segments the image into overlapping tiles in a pyramidal structure and allows the user to pan and zoom on a full-resolution image by requesting the next tile or a corresponding tile at a higher resolution. The image-navigation tool receives information about resolutions, resolution ratios, and window sizes to make the navigation possible; the image display tool uses that information to pan, zoom, crop, or otherwise use images. Display and PrintThe display method uses a reference to a known object to deliver an item to a screen-oriented tool, such as a graphical Web browser. In contrast to navigation, where the user tool requests object references, the display tool works from an object identifier it has received from an intermediary or can infer from a query where only one object exists. -18- From this relatively simple operation emerge more complex issues, one of which is the variety of known item references that an intermediary must handle. At its simplest, a display tool will encounter references to page images in a format clearly identified by structural metadata. Similarly, the tool may receive a reference to an encoded text section such as a chapter, again in a format identified by structural metadata. Examples of references that are slightly more complex include requests to display the next or previous sibling of the digital object (next page or previous chapter) or the parent of the digital object (the chapter that includes this page). For images, an intermediary may request the display of a known item at a specific resolution. More challenging will be the standard articulation of a reference to display a portion (for example, "250 by 250 pixels, centered on pixel X.Y") of an image at a specific resolution. Panning, zooming, and cropping of an image are variations on this type of request.Printing is a method similar to the display method; it differs only in its use of printers, plotters, disks, and other output devices. The option to print may use the same format as the option to display, as is the case with systems relying primarily on encapsulating images in portable document format (PDF) for delivery. The display and print methods are closely intertwined and differ according to the formats available from the repository and user preferences. For example, imagine that a repository of bitonal, 600 dpi page images offers graphics interchange format (GIF) images with interpolated grayscale, Postscript, and PDF. A user without Adobe Acrobat may choose to display the GIF images but print using the Postscript files containing encapsulated images. A user with Acrobat may choose to rely entirely on the PDF image files to print and display from the same source. Combination or ComparisonAs the body of materials in the digital library grows, the ability to create combinations of data or perform comparisons becomes increasingly important. Combining and comparing methodsmost common with art and architectural images (consider the common use of two slide projectors in art historical instruction)are applicable to both images and text. Support for the comparison of two passages of text or the display of a text alongside an image is also needed. Common applications might include the following:
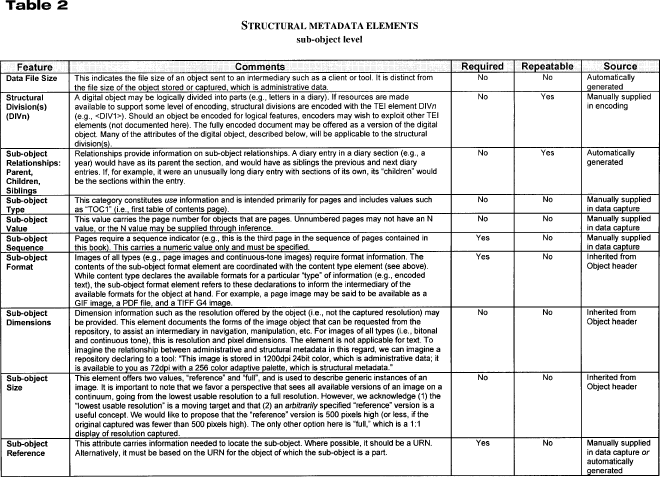
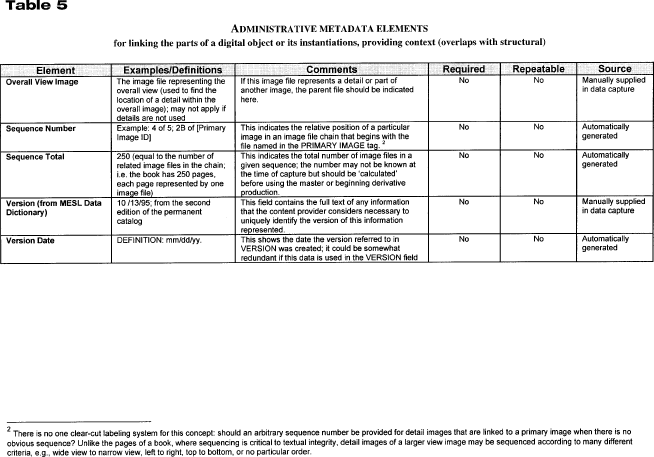
-19- Somewhat more complex is the requirement to combine objects. The need to apply layers to, or remove them from, an object is especially important. This problem is considerably easier when a single repository has provided these layers with the base image; however, a more generic method is needed to allow the combination of layers from diverse sources. For example, the allegorical drawings found in nineteenth-century journals such as Harper's Weekly often contain contemporary public persons portrayed as historical figures. A server at one DLF institution might provide the images of the pages, while a second DLF institution might overlay commentary identifying each person. A tool supporting the display method might offer that image in any number of different resolutions; it might even display portions of the image cropped and enlarged. The ability to coordinate the annotations of the second institution with the page image from the first institution will require carefully controlled metadata about coordinates that stay constant with the cropped portion. While these types of administrative and structural metadata may be too challenging for early portions of the testbed project, the model must be flexible enough to accommodate this information in later iterations. Repository SearchRepository search methods, more than most other methods, tend to be exhibited by server-side programs rather than by client-side tools. [6] At least portions of these methods could eventually migrate to the user's desktop, but considerable standardization must first take place. In a repository search, an intermediary collects information about the user's query and the characteristics of the available collections and begins to process results (for example, in a sorted list by object or by collection). This intermediary has distinct discovery and retrieval functions. To support discovery within and among repositories, each collection must participate in a conversation with the client or intermediary. This conversation constitutes the method associated with discovery. The repository's discovery method must include the ability to understand the search parameters of the repository, including gathering information on searchable fields, on the sorts of operators that can be applied, and other constraints. These mechanisms have been specified in protocols such as Z39.50, but it is important to explore -20- more flexible mechanisms such as the search interface language (SIL) specified in Nigel Kerr's Personal Collections and Cross-Collection Technical White Paper (1997).To support the retrieval of results within and among repositories, the conversation must include a well-specified retrieval method. Results must come from the repository or repositories in a well-articulated and easily parsed syntax. The tool will use this syntax, for example, to build result lists, to bring together results from multiple repositories, and to compile results from multiple repositories. An example of a proposed specification for such a retrieval method can be found in Nigel Kerr's white paper. Color AnalysisAn admittedly challenging set of methods will come with richer and more reliable color metadata. The availability of a Color Look-up Table (CLUT), which provides color, shape, and texture distribution that can be processed through automatic means, will aid in a variety of tasks. For example, a color-matching behavior might take CLUT information from manuscript fragments, locating fragments that are more likely to be from the same paper stock because of color or texture. CLUT information can also be used to measure subtle variations such as shape and patterns; this would enable the user to detect, for example, hidden features such as characters obscured by palimpsest erasures. Methods using the CLUT could support these types of analyses. Bookmarks, Annotations, and LinksAs the digital library grows in maturity and capability, the array of interactions with objects will become more complex. Users want intraobject bookmarks, annotations, and more sophisticated linking methods, none of which is outside the capabilities of readily available desktop technology. Nevertheless, the ability to support these methods is hampered by unreliable or incomplete metadata, the absence of generalized notions of user authentication and authorization, and a lack of support from repositories. Most important, libraries and archives lack the tools to exploit methods in these areas. Many of these methods are explored in detail in the research applications developed by Robert Wilensky and his team as they pursue notions of "multivalent documents" (Phelps and Wilensky 1996). Moreover, emerging standards such as the extensible markup language (XML) and extensible linking language (XLL) will help articulate complex links (such as a span of information or "the third paragraph in the fourth section") within a remote document. These methods will be best supported through the articulation and adoption of architectures within which effective tools can be built and through metadata that document a full range of digital object features. -21- MoA II MetadataMetadata can be in a header, a MARC record, a database or an SGML file, or they can be distributed among a variety of locations. An object or repository needs only to be able to reconstitute the metadata and present them to a user or application when requested (the discovery, navigation, and administrative functions). Descriptive MetadataThe library community has a long history of developing standards and best practices for descriptive metadata (for example, MARC and the Dublin Core). Given existing standards and ongoing work to investigate descriptive metadata issues, the MoA II proposal did not focus on this area. Instead, the MoA II testbed used a union catalog with MARC records contributed by the participants. The participants also contributed finding aids encoded to the EAD community standard. In the discovery process, users will search the MoA II union catalog of MARC collection-level records that will be linked to their corresponding finding aids, and the finding aids will then be linked to the appropriate archival digital library object. Of course, it will also be possible to search the finding aids directly to discover archival library objects. Structural MetadataThe terminology of the digital library is evolving rapidly. Consequently, there is considerable variation in how the library community uses certain terms, one of which is structural metadata. (For more information on the definition of structural metadata, readers are referred to Structural Metadata Notes in the Appendix.) For the purposes of this paper, the term structural metadata is defined as those metadata that are relevant to the presentation of a digital object to the user. Structural metadata describe the object in terms of navigation and use. The user navigates an object to explore the relationship of a subobject to other subobjects. Use refers to the format or formats of the objects available for use rather than formats stored. Current thinking divides digital library metadata into three categories (descriptive, administrative, and structural) or two categories (descriptive and structural, with structural metadata subsuming administrative metadata). This report separates administrative and structural metadata. More important than this separation, however, are the categories proposed for inclusion in the MoA II architecture. Although the categories defined here are presented in SGML, the data in a repository will not necessarily be stored in an encoded form or in a table. This document does not advocate a particular method for storing data; various approaches will be necessary in different institutions, and several approaches may even exist within the same institution. For example, descriptive metadata may be stored in USMARC, portions of structural and administrative data in relational tables, and other portions in SGML. These examples are intended to -22- illustrate the type of data presented in interactions between repositories and intermediaries. The authors assume that these metadata will be extracted from metadata management systems in interactions with intermediaries such as tools. Further, default and inherited values will be expressed explicitly at the level of the subobject, even if implicitly associated with the subobject through the metadata management system.Structural Metadata Elements and Features TablesTables 1 and 2 recommend the full set of possible structural metadata elements that an individual collection may find useful. Some repositories will use only the minimum set of required elements. Others will also use other elements that can be derived in an automated fashion. Still others will use elements that are easy to capture or derive. The tables include both minimal and maximal values, identify required and repeatable fields, and identify whether field values may be inherited or supplied manually. Some elements can fulfill both administrative and structural functions. Some elements are relevant to raw data (such as page scans) which do not require extensive examination of the data structure. Other elements are relevant to "seared" data (such as chapter divisions and headings), which require only minimal examination of data structure to generate appropriate metadata. Still other elements are primarily relevant to "cooked" data (such as SGML marked-up text), which require serious examination of structure. [7] Table 1 describes structural metadata defining the object, and table 2 describes structural metadata defining the digital subobjects (for example, the individual digital pages). Thus, the structural information for a digital object is divided into information referring to the constituent objects that cohere into a whole (such as a description of the extent of a digital book) and information specific to the individual parts (such as page or image references). [8] The distinction between object and subobject metadata is in some ways artificial. For example, a tool might assemble information related to the constituent parts of a photograph album by querying each of the constituent subobjects rather than by querying a specially designed digital object. However, certain economies, such as stating ownership only once in the object rather than with each subobject, prevail when storing information. This model strives to balance the specification of elements accordingly. -23- Administrative MetadataAdministrative metadata consist of the information that allows the repository to manage its digital collection. This information includes the following:
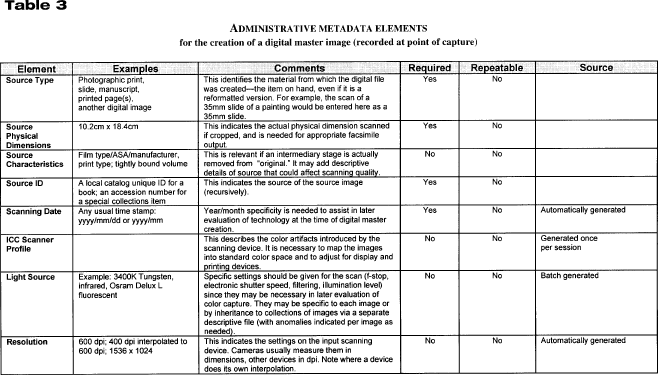
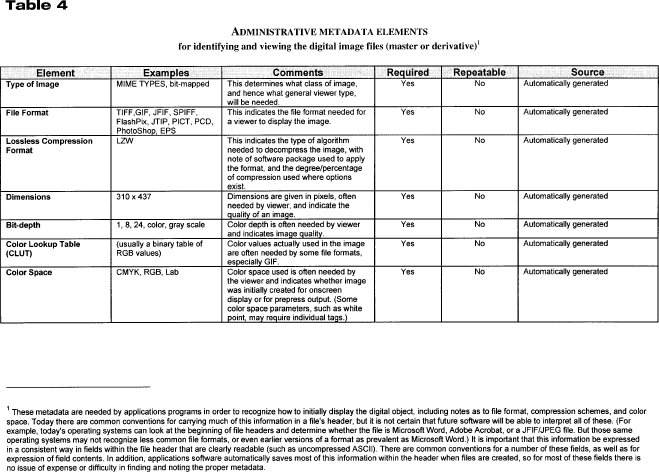
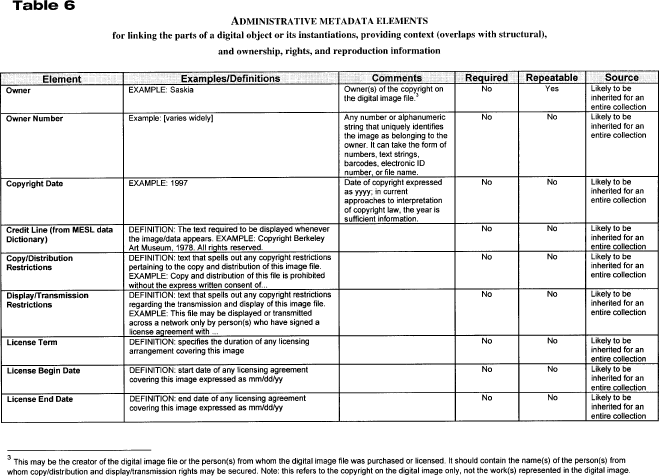
Administrative metadata are critical for long-term file management. Without well-designed administrative metadata, image file contents may be as unrecognizable and unreadable a decade from now as Wordstar or VisiCalc files are today. Administrative metadata should help future administrators determine the file type, creation date, source of original, methods or personnel that might have introduced artifacts into the image, and location where different parts of this digital object (or related objects) reside. Eventually, administrative metadata may help support the long-term management of objects; for example, the metadata contained within the objects will allow for automation of migration from an older file format to a newer one, for refreshment, and for regular backup. In the past, certain administrative metadata (such as file formats) resided in file headers, while others resided in accompanying databases. In the future, all administrative metadata may reside within the file header. Such a system would be ineffective, however, until there are community standards that specify where they would go within the header, how to express them, and so forth. Work is already under way to develop those standards. In April 1999, NISO, DLF, and RLG convened a meeting to discuss technical metadata elements for images. The results of the meeting are available on the Web (Bearman 1999). For the purposes of this paper, the necessary administrative metadata fields are defined without regard to a particular syntax of where they will actually reside. For the purposes of the MoA II project, administrative metadata will be delivered external to the image file header. This section primarily concerns administrative metadata for master files. In the future, however, repositories are likely to see master files that are themselves derivatives of previous files. To make the administrative metadata that the authors identify as compatible as possible with future developments, some information dealing with -24- derivative files (or other instantiations of a work) is included. In this way, the project will lay the groundwork for future research projects to identify and trace the provenance of a particular digital work.Administrative Metadata Elements and Features TablesTables 3-6 recommend the full set of administrative metadata elements that an individual collection may find useful. Some repositories will use only the minimum set of required elements; others will also use elements that can be derived in an automated fashion. Still others will choose to use elements that are easy to capture or derive. The tables include both minimal and maximal values and specify which are allowed to repeat. Some elements can fulfill both administrative and structural functions. Although the number of metadata fields seems daunting, a high proportion may be the same for all the images scanned during a particular session. For example, metadata about the scanning device, light source, or date are likely to be the same for an entire session. Some metadata about the different parts of a single object (such as the scan of each page of a book) will be the same for that entire object. This kind of repeating metadata will not require keyboarding each field for each digital image; instead, they can be handled either through inheritance or by batch-loading various metadata fields. This report attempts to identify best practices for metadata development. Individual repositories will follow these practices to the extent that they can afford. Tables 3-6 describe elements needed for the creation of a digital master image; identification of the digital image and tools for viewing or using it; linking the parts of a digital object or its instantiations; providing context; and ownership, rights, and reproduction information. Tables 3 and 4 show the type of data that uniquely identify a particular representation of a work. For future derivative images, these could be iteratively nested to represent the provenance of a work. Encoding: Best PracticesEncoding Archival Object Content and Finding AidsMany MoA II materials require text encoding. This may be the case whether the documents are carefully transcribed and edited versions of the original documents, whether they simply organize (conceptually) a mass of automatically generated text via optical character recognition (OCR), or whether only the framework of a document is encoded, with pointers to images. Moreover, finding aids for many resources will be encoded to support fine-grained access to a collection. There has been substantial work and community effort in both areas, and efforts are under way to organize discussions around the use of the available guidelines. Project participants should use the EAD for the encoding of finding aids. [9] While the EAD guidelines allow considerable latitude for the application of markup to finding aids, work with the EAD must -25- grow out of local assessment of the needs for finding aid support and the way that these finding aids will be used. Discussions are under way in the DLF about interinstitutional searching of EAD-encoded collections and the resulting scrutiny of local practice. Using locally defined needs to drive the application of EAD will help clarify the range of needs for interinstitutional applications.Text encoding efforts in MoA II will be well supported by the SGML articulated in the Text Encoding Initiative Guidelines (TEI). [10] The TEI support a range of document types and methods, including the transcription of primary sources and damaged documents. More important, the TEI Guidelines and the associated DTDs (document-type descriptors) offer support for encoding the range of possible structures in MoA II documents, whether or not transcriptions are included. The TEI, like the EAD, offers considerable flexibility in the ways documents can be encoded. A further note on the relevance of XML to these two central encoding schemas may be useful. XML promises to bring richly encoded documents to the user's desktop through widely available browsers. Moreover, a growing array of XML-capable tools should be available through mainstream software development. XML-compliant versions of both the TEI and the EAD DTDs are likely to be available soon. One editor of the TEI guidelines has been centrally involved in writing the XML specifications, and the TEI editors have declared their intention to create XML-compliant versions of the widely used TEI DTDs. Encoding to Encapsulate Metadata and Content Inside the Archival ObjectAfter this report has been circulated and discussed, the project team will have gathered enough information to define an encoding scheme for the archival objects that will populate the MoA II testbed. A draft of the MoA II XML DTD has been completed and readers are referred to view both the DTD and documentation available at http://sunsite.Berkeley.EDU/MOA2/ (see the section on MoA II Tools). This XML DTD will define the transfer syntax used for MoA II objects. Selecting an XML to encode the object does not mean that any repository must use that encoding for internal object storage. However, it does give the DLF and the larger community an opportunity to discuss and evaluate XML as transfer syntax. Footnotes5. Generic and specific are difficult to define in this context. The discussions that take place in the MoA II process are anticipated to help define and agree on generic methods. 6. The MoA II project will rely primarily on a union catalog to effect discovery. A union catalog obviates problems associated with inter-repository searcheshow one characterizes the search to the various systems and brings together results from those different collections. Nevertheless, the ability to perform a search across a number of distributed repositories becomes increasingly important as we distribute responsibility, while maintaining important elements of institu-tional autonomy. Repository search, and especially the means to support inter-repository search, is discussed here not because it must be explored in MoA II but because it is an important method to keep in mind when conceptualizing the digital library. 7. The University of Michigan (UM) uses the terms raw, seared, and cooked to describe levels of processing for the Making of America I materials (www.umdl.umich.edu/moa/). For a discussion of MoA I processing at UM, see www.dlib.org/dlib/july97/america/07shaw.html and various sections in http://www.umdl.umich.edu/moa/about.html. 8. For its organization and for many of the elements, this model owes a great deal to the Structural Metadata Dictionary for LC Repository Digital Objects. Located at http://lcweb.loc.gov:8081/ndlint/repository/structmeta.html. 9. Information about the EAD, including guidelines for the application of the EAD and DTDs, is available at http://lcweb.loc.gov/ead/. 10. Information about the TEI can be found at the TEI Consortium home page http://www-tei-c.org/. A searchable version of the TEI Guidelines can be found at the TEI Consortium home page, and via the Humanities Text Initiative pages at http://www.hti.umich.edu/docs/TEI/. -26-
-27-
-28-
-29-
-30-
-31-
-32- APPENDIX: STRUCTURAL METADATA NOTES
-34- REFERENCESOrganization of Information for Digital Objects
Metadata
Scanning And Image Capture
-36- |

Copyright © 2006 Digital Library Federation. All rights reserved.
Last updated: