|
1
|
|
|
2
|
- Develop a national digital collection and preservation strategy
- Work with industry, concerned federal agencies, libraries, research
institutions and not-for-profit entities
- Help identify and preserve at-risk digital content
- Support development of improved tools, models, and methods for digital
preservation
|
|
3
|
- Network of preservation partners
- Preservation architecture
- Digital preservation research
|
|
4
|
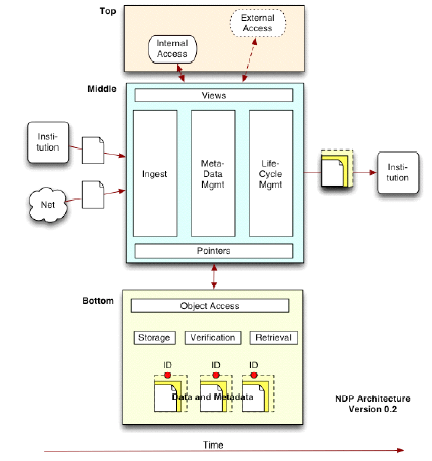
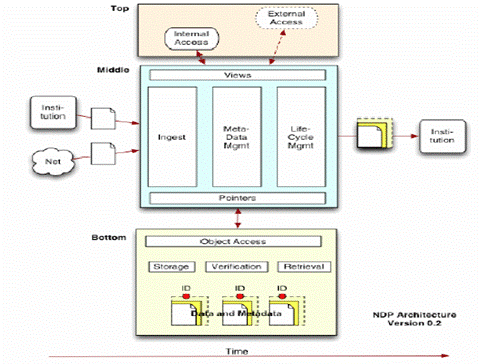
- A conceptual framework for supporting the technical functions and
developing tools required for cooperative, distributed preservation of
digital content
- It must
- support relationships between institutions.
- allow questions of preservation to be handled separately from questions
of public access.
- be built modularly, using existing technology and efforts wherever
possible.
- be able to be assembled over time.
- be specified using broadly adoptable protocols.
|
|
5
|
- AIHT is a first test of proposed preservation architecture.
- The test is conducted with a common data set.
- George Mason University 9/11 Archive
- Phase I tests ingest and data handling in local systems.
- Phase II tests export and import between institutions.
|
|
6
|
|
|
7
|
- Harvard University Library
- The Johns Hopkins University, Sheridan Libraries
- Old Dominion University, Department of Computer Science
- Stanford University Libraries & Academic Information Resources
- The Library of Congress, Office of Strategic Initiatives
|
|
8
|
- Background
- Current policy limits deposit
- approved workflows
- small set of formats
- accompanied by preservation metadata.
- Evolution towards that of an institutional repository
- arbitrary content
- unknown provenance
|
|
9
|
- Approach
- Use JHOVE to provide enriched technical metadata
- Build tools to generate SIP packages automatically
- Enhance metadata model to record PREMIS-like provenance information
- Add export functionality to repository API
- Investigate TIFF-to-JPEG 2000 transformations
|
|
10
|
- Team
- Dale Flecker – Principal investigator
- Stephen Abrams – Project manager
- Stephen Chapman – Reformatting analyst
- Sue Kriegsman – Project administration and reporting
- Gary McGath – Developer
- Germain Seac – Operations
- Robin Wendler – Metadata analyst
- Technologies
- Digital Repository Service (DRS) – Oracle (metadata), Java API, RAID
(content), Solaris, XML-based SIP package
- JHOVE for extraction of encapsulated technical properties
- Automated SIP creation tools
|
|
11
|
- Observations
- JHOVE can process 97% of the 57,000 files
- ASCII/UTF-8, HTML, JPEG, WAV, TIF, PDF, GIF, AIFF, XML
- The PREMIS event model is very flexible, but it is difficult to
determine the best way to capture provenance metadata
- Data manipulation issues:
- You can FTP 13GB as one file in 3 hours; to FTP it as 57,000 files
takes 35+ hours
- Some FTP clients do not like 0 length files
- Some ZIP tools have a file size limitation
- Some network appliance file servers have a file size limitation
- The data does not include any infected files!
|
|
12
|
- Background
- Johns Hopkins University Sheridan Libraries has been investigating
multiple repositories. AIHT provides a digital preservation use case.
- Project Approach
- Large-scale ingestion with a repository-agnostic design
|
|
13
|
- Team
- Mark Patton (developer)
- Sayeed Choudhury (PI)
- Tim DiLauro (tech lead)
- Jacque Gourley (project manager)
- Ying Gu (student)
- David Reynolds (metadata)
- Jason Riesa (student)
- Technologies
- Dspace, Fedora, METS, Java, OS X
|
|
14
|
- Observations:
- Bulk ingestion of a complex archive is a good way to stress test
repository interfaces
- Coordinate between provider and recipient as much as possible
- Design metadata from established standards, instead of attempting to
shoehorn
- No seamless way to ingest to multiple repositories
- Needs repository agnostic layer
|
|
15
|
- Background
- Experiment with alternate archive architectures
- Create self-preserving digital objects
- Project Approach
- Build ingestion tool to test individual file validity
- JHOVE, “file”, Fred, etc. to generate technical metadata
- Create an MPEG-21 DIDL that contains:
- preservation analysis, technical metadata, original tar file, current
tar file, “deltas” (cf. diff/patch semantics) for intermediate
versions
- Store DIDLs in self-contained, mobile archivelets (“buckets”)
- Compare archived version with versions available on open Internet
- original site, Google, Yahoo, IA, etc.
|
|
16
|
- Project Team
- Professors
- Michael L. Nelson, Johan Bollen
- Graduate students
- Giridhar Manepalli, Rabia Haq
- Technologies
- Bucket 3.0 Digital Objects
- MPEG-21 DIDL
- JHOVE, file, Fred
- locally developed ingestion / conversion scripts
|
|
17
|
- Observations
- Significant learning curve for MPEG-21 DIDL
- Hoping to incorporate MPEG-21 Rights Expression Language (REL) in the
AIHT testbed
- Conversion utilities (e.g. ImageMagick) are assumed to:
- Exist outside of the archive
- Be transient services
- Significant discrepancies between archived and live site:
|
|
18
|
- Background
- Stanford Digital Repository originally focused on highly normative
bibliographic digital objects.
- The AIHT provides an opportunity to develop capabilities for real-world,
non-normative collections.
|
|
19
|
- Approach
- Develop or integrate tools
- Stanford Empirical Walker™
- JHOVE
- Automate digital collection assessment
- technical metadata harvesting
- structural description
- preservation risk assessment
|
|
20
|
- Team:
- Richard Anderson – Programming
- Keith Johnson – Project Management
- Hannah Frost – Preservation Methodologies
- Nancy Hoebelheinrich – Metadata
- Jerry Persons – Information Architecture
- Cathy Aster – Reporting and Financial Management
- Technologies:
- METS, Harvard METS Toolkit, JHOVE, PREMIS, Java, Solaris, Windows
|
|
21
|
- Observations
- User-supplied metadata can be messy and difficult to transform to a
standard format
- Expected preservability status:
- 70% HIGH
- 27.5% ACCEPTABLE
- 2.5% MINIMAL
- Large file collection generates large METS file
- Requires lots of memory and processing power
- Parallel metadata hierarchy vs. single XML file
- PREMIS data elements/model looks very promising for storing
preservation status and methodologies
|
|
22
|
- Great minds don't think alike
- Metadata is worldview
- Simple operations are harder than you think
- Support for forensics is essential
- 1% times a big number is a big number
- It's all triage
|
|
23
|
- Next revision of Transfer Metadata format
- Work on inspection tools
- Explore format registry
- Work on whole-archive export/ingest
- Work on format conversion
- JPEG->TIFF
- Web sites as complex objects
|
|
24
|
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}