4.0 Review of Resources
4.1 Points of Reference: Open Access and the Open Archives InitiativeWhile OAI and Open Access are not synonymous, the Open Access movement relies heavily on the OAI protocol as the mechanism for communicating the availability of OA resources. Publishing in Open Access journals and self-archiving in OA archives are specified by the Budapest Open Access Initiative (BOAI), and further bolstered by the Berlin Declaration, as the major ways to make manifest OA research output. Moreover, institutional repositories (typically OA and OAI-compliant) are increasingly accepted as an essential component of a university's scholarly infrastructure (Lynch 2003). When the 2003 report was written, it was difficult to identify OA (and OAI-compliant) journals and repositories. The Directory of Open Access Journals (DOAJ), launched in May 2003, marked an initial step towards making OA journals better known, but it was still in an early stage of development. In addition, there was no easy way for authors to identify the copyright polices and self-archiving regulations of publishers. Discovery of OA repositories was even more problematic. Assembling a composite picture was painstaking and idiosyncratic, made possible only by triangulating from data gathered from multiple sources-the official Open Archives Initiative's voluntary registry of OAI data and service providers, the technical OAI Repository Explorer validation system, and via the aggregators, such as Arc and OAIster. Noting numerous difficulties in identifying OAI-compliant repositories and the deleterious impact on data providers, service providers and their users, the 2003 DLF report called for a user-friendly comprehensive registry (Brogan 2003, 75). In the intervening years, the situation has changed markedly. The registries, directories and indexes under consideration here, are the visible manifestation of OA and OAI growth. New to the scene, the University of Illinois OAI-PMH Data Provider Registry now ably serves as a comprehensive interactive OAI identification system. Indeed, from a technical standpoint, the concept of registries has become an essential component of digital library architecture covering a wide spectrum of functions. Two new projects, one in the UK and the other in the US, are working in tandem to develop a framework for DL service registries that will help to automate the discovery of DL content and services (see section 2.1.1 and 3.2). Meanwhile, two OA repository registries, geared towards improving communication between developers, researchers and authors, have been developed in the UK. Concomitantly, the DOAJ has extended its services to include article-level access and two new directories now monitor journal and publisher copyright and self-archiving permissions (one outcome of the UK's RoMEO project cited in 2003). Arc continues to serve as a test bed for improving and extending OAI applications. OAIster, on the other hand, has become the de facto leader as a global OAI service provider, dispensing item-level digital content to end-users. In addition to discussing these major services, this section reviews three new consortial metadata aggregators-the CIC Metadata Portal and the DLF's OAI and MODS portals and then turns to Germany as an exemplar of nationally-based OAI services. Critical issues and future directions round out the review of these services. Interlocking Purposes Collectively, the registries, directories and indexes under review serve the following purposes for an audience ranging from data and service providers to researchers, authors and end-users:
Technical registries serving a range of purposes are rapidly becoming key components of the standards and technology infrastructure supporting digital libraries. Facilitating interoperability through a low-barrier protocol, the official Open Archives Initiative site does not require either data or service providers to register in order to implement the protocol. Registration is optional and many developers simply do not take the time. In other instances they may deliberately choose not to register because the service is not yet in full production; they do not wish to publicize the availability of their resources; or they already have a known clientele. Registration, however, is not merely a matter of publicizing a new repository or service; it also typically entails testing archives for compliance with the OAI protocol. This helps to validate that metadata is appropriately configured to meet at least minimal standards for harvesting. OAIster, for example, requests new data providers to follow a series of steps before contacting them to harvest new content. OAIster's guidelines include official registration with the Open Archives Initiative where new data providers can obtain the OAI foundational documents, access basic OAI tools, and join community services, consisting of email forums and other registries for data and service providers. As a final step prior to contacting OAIster, new data providers are asked to email the administrator of the University of Illinois's Registry (described below) thereby helping to ensure that it has a complete listing of OAI repositories. OAIster's implementation steps help to reinforce the role and function of different OAI registries and validating services, leading to a more cohesive community of practice. 4.1.1 University of Illinois OAI-PMH Data Provider RegistryDeveloped under the auspices of the DLF's IMLS National Leadership Grant described earlier in this report, this registry primarily serves as a tool for OAI harvesters to discover and effectively use content in repositories upon which developers can build services. The UI Registry (announced in October 2003) strives to be comprehensive and deploys a systematic multi-faceted approach (that goes beyond self-registration) to achieve the goal of completeness (Habing et al. 2004; Shreeves et al. 2005). As of mid-May 2006, the Registry, with 1,042 repositories, is the most complete and useful OAI data provider discovery service for developers. It automatically harvests an array of data elements from each repository, making "it possible to search for OAI repositories using various criteria and browse through different views of the registry [e.g., sets, metadata formats, records, identifiers, subjects] without any manual cataloging of the various OAI repositories" (Shreeves et al. 2005, 581). A new enhanced OAI data provider has been developed for the registry to allow not only simple Dublin Core records which describe each repository to be harvested, but also the much richer information that has been created manually along with the repository descriptions imported from OAIster (Cole and Habing 2006). [[24]] The metadata format for these richer descriptions conforms to the schema developed for UIUC's IMLS Digital Collections & Content project (see section 4.4.2). UIUC has also developed an OAI gateway application that provides a single point of harvest for all DLF-member repositories. Beyond the convenience of harvesting from a single base URL, individual repositories are organized as sets within the gateway with their own sets organized as subsets. Because each of these sets and subsets has rich collection-level metadata derived from the registry, it allows harvesters to easily associate collection-level metadata to individually harvested items. The DLF member OAI data providers are cataloged and browsable by GEM (Gateway to Education Materials) and LCSH (Library of Congress Subject Headings). The UI Registry and OAIster collaborate to improve communication between OAI data and service providers, while also enhancing their respective services. Initially OAIster provided UI with additional metadata about all of its OAI repositories (e.g., title, description, home page, and historical record counts) and now it refers new data providers to UI for registration and validation before harvesting their metadata. This helps to ensure fuller coverage via the UI Registry while also resolving some technical validation problems prior to harvesting by OAIster. OAIster also sends its historical data to the Registry on a monthly basis. This makes it possible to access growth graphs for many repositories, although it does not match ROAR's growth charts in terms of user-friendliness and access. The Registry's syndication service (RSS) alerts users to recent changes, listing modifications and new additions over the past 30 days. In addition to OAI-PMH and RSS export functionality, it also supports the SRU protocol (CQL subset). UI is also developing Web-based search and browse interfaces for an OAI service provider registry that will list services developed from harvesting data via the OAI-PMH. Eventually, UI hopes to link the OAI service providers in the database to the OAI data providers from which they harvest. Project news, presentations, and documents, including the cataloging procedures and guidelines used for the DLF collections is available at the Registry's Web site. 4.1.2 DOAJ: Directory of Open Access Journals
Launched in May 2003 with 350 journals, DOAJ included more than 1,900 titles by December 2005 and quickly surpassed the 2,000 mark in early 2006. Article-level searching was introduced in June 2004 and as of mid-March 2006 exceeded 80,000 articles. According to the DOAJ Web site, "The Directory aims to be comprehensive and cover all open access scientific and scholarly journals that use a quality control system to guarantee the content." It defines open access journals as those that "use a funding model that does not charge readers or their institutions for access" and its selection criteria uphold reader's rights as put forward in the BOAI principles to "read, download, copy, distribute, print, search, or link to the full texts of these articles." In early 2006, DOAJ updated its selection criteria based on feedback from users.
The DOAJ subject classification is expandable and offers links from topical categories to the journal titles. The two largest sub-categories are Medicine (General) with 194 titles (in Health Sciences) and Education with 148 titles (in Social Sciences). Users can search for journals via keywords or browse by title or subject. The article database supports basic Boolean operators to connect keyword or phrase searches across all fields or limited to title, journal title, author, ISSN, keyword or abstract. A search for articles using the keyword <tsunami> retrieves 13 documents, all with 2005 and 2006 publication dates. The entries provide basic bibliographic citations with the option to view the record or the full text article. Information about harvesting DOAJ journal and article-level metadata (initiated in July 2004) as well as restrictions on metadata usage (DOAJ is licensed under the Creative Commons Attribution-ShareAlike License) is provided at the Web site's FAQ. DOAJ supports harvesting of broad subject-based sets. DOAJ actively solicits monetary contributions from users to continue to improve its functionality and keep it in continuous operation. 4.1.3 Directories of Journal and Publisher Copyright and Self-Archiving PoliciesWhile DOAJ identifies Open Access journals and publishers it does not disclose their copyright or self-archiving policies. Authors can use the SHERPA/RoMEO List of Publisher Copyright Policies and Self-archiving to "find a summary of permissions that are normally given as part of each publisher's copyright transfer agreement." [[25]] The directory, hosted by the University of Nottingham, is searchable by journal title or publisher. Publishers are assigned a color code that reflects whether permission is granted to self-archive and at what stage in the publication process. According to the site's summary statistics in May 2006, 78 percent of the 154 publishers officially allow some form of self-archiving. An API is being developed to allow repository administrators and others to interface with the database, possibly as a stage in a repository's ingest procedure or similar process. The information is available for downloading by interested parties by special arrangement: for example, the listing hosted by Eprints.org is based on the SHERPA/RoMEO information. Reports and publications emanating from SHERPA affiliated projects and research are available from its Web site, http://www.sherpa.ac.uk/guidance/advocacy.html#reports.
Source: http://www.sherpa.ac.uk/romeo.php?stats=yes (March 18, 2006) EPrints.org has developed a similar directory, based on SHERPA/RoMEO's data of journals that have and have not already given "their green light to author self-archiving." Under rapid development, as of mid-March 2006, it contains 136 publishers and almost 8,900 journals. In contrast to the SHERPA/RoMEO's list, journals are given one of three different color codes:
Comparative Coverage: OA Journal Directories and Databases It seems reasonable to expect that SPARC's OA journal titles would be well-represented in these OA journal directories, but a comparison of sample SPARC journal titles reveals inconsistent and incomplete coverage.
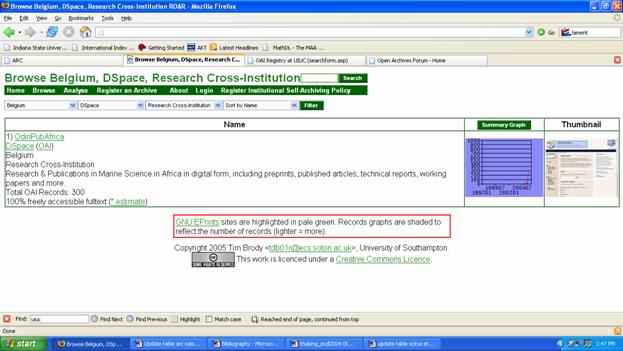
All of the PubMed Central titles indicated as free and open access by SPARC also have article-level access in DOAJ. However, with the exception of the fully-represented BioMed Central titles, coverage of other PMC titles is uneven in the two self-archiving policy directories. Of the six OA Project Euclid journal titles, only two are listed in DOAJ; one title is identified as green in SHERPA and two in EPrints.org. Among the sample OA titles: 5 are not listed in DOAJ; fifteen are either not listed or represented by title only (without any corresponding self-archiving policy information) in SHERPA; and twelve are not covered in EPrints.org. The German database of e-journals, EZB (Elektronische Zeitschriftenbibliothek), is the only source to contain all of SPARC's OA titles; moreover, they are correctly annotated in cases where only specific years are OA. EZB's coverage and coding scheme is described more fully below (see 4.1.9) but it does not include journal or publisher self-archiving policies. 4.1.4 ROAR: Registry of Open Access RepositoriesLaunched in fall 2003, ROAR (formerly known as the Institutional Archives Registry) has two main functions: "(1) to monitor overall growth in the number of e-print archives and (2) to maintain a list of GNU EPrints sites (the software the University of Southampton has designed to facilitate self-archiving)." [[27]] The ROAR FAQ lays out the goals for coverage, emphasizing OA and OAI-compliant research documents, predominantly preprints, postprints of peer-reviewed journal articles, or dissertations. In practice, it has few, editorial exclusions. [[28]] Beyond research papers, ROAR includes other formats; for example, the University of Southampton's Crystal Report Structure Archive (http://ebank.eprints.org/), a repository that utilizes EPrints.org software to archive datasets "generated during the course of a structure determination from a single crystal x-ray diffraction experiment." It also includes records (46,000) from the Biblioteca "Dr. Jorge Villalobos Padilla, S.J." Instituto Tecnológico y de Estudios Superiores de Occidente, (ITESO), Mexico, excluded by OAIster because they report that many items refer to SFX links, hence they are not really OA. As stated elsewhere in this report, there are many "grey" areas in OAI-harvesting that make it difficult to reach uniform decisions about such parameters as "freely available" or "Open Access." ROAR is a useful tool for analyzing the characteristics, size, and growth within and across OA e-print archives around the world. Archives are classified by country, system software, and content type. Searches can be filtered by any combination of these fields (e.g., Research Cross-Institution archives using DSpace in Belgium) and sorted by Name, Datestamp, or Total OAI Records. Results provide an annotated entry about the resource with links to the source site, an estimate of the percent of its content that is freely accessible, full text summary graphs charting its growth over time, and a thumbnail of the service's Web site.
The Browse feature gives composite record counts by three major parameters: country, archive type and software. Record counts are limited to those archives registered and successfully harvested by Celestial; the figures are not restricted to full-text items but reflect all metadata records.
Source: http://archives.eprints.org/index.php?action=browse (February 28, 2006) ROAR's categorization of "archive types" is unique. Given its focus on e-prints, it is not surprising to find that "research institutional or departmental" deployments account for nearly half of ROAR's archives. There is little doubt that this broad category also subsumes some e-journal/publication and e-theses content. These three categories combined account for 70 percent of the archives but only 37 percent of the records, whereas "research cross-institution" accounts for less than 10 percent of the archives but nearly 50 percent of the records. The record count could be quite different if all the archives were fully represented in Celestial or if the archives in the "other" category (94) were assigned to a discrete category. [[29]]
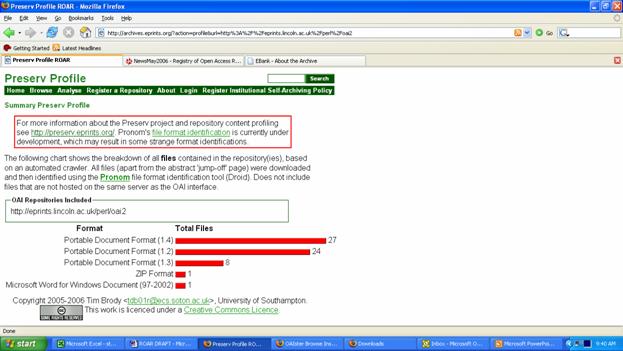
Source: http://archives.eprints.org/index.php?action=browse (February 28, 2006) ROAR offers easy access to information about which archives utilize specified system software. Almost all the archives deploying a handful of major repository software systems are fully represented in ROAR (e.g. GNU EPrints, DSpace, DiVA, ARNO, Digital Commons bepress). Although there are myriad IR systems in use worldwide, it would be helpful if more of the archives falling into the "other software" were reviewed and either placed into an existing or newly-created software category (e.g. Arc; Archimède; digitAlexandria-FreeScience and Archivemaker; DLXS; and the Public Knowledge Project's Open Journals and Open Conference Systems). At present the "other category" represents 29 percent of archives and a whopping 73 percent of ROAR's records. Among the top twenty largest archives in ROAR, thirteen presently fall into the "other software" category (e.g., CiteSeer, PubMed Central, arXiv, Library of Congress's American Memory). As advocates of self-archiving and the Open Access principles set forth in BOAI and the Berlin Declaration, ROAR also operates a registry of institutional self-archiving policies, recently renamed ROARMAP (Registry of Open Access Repository Material Archiving Policies). As of mid-May 2006, 19 institutions in nine countries and one European-wide research institution had registered a policy commitment. Each entry includes a link to the institutional repository, its growth data, and details about its OA policy. Five institutions mandate self-archiving: CERN, University of Southampton, Queensland University of Technology, University of Minho, and University of Zurich. ROARMAP includes model self-archiving policy statements; model policies for national and private research funding agencies are also presented. In May 2006, ROAR announced two new developments. First, in addition to the RSS, plain-text and ListFriends exports, its records (not their content) became OAI-compliant, initially available as Dublin Core. Secondly, as part of the Preserv project (http://preserv.eprints.org) they added support for Content Profiling institutional repositories-available for most GNU EPrints and DSpace repositories. Users can access links from ROAR entries to the Preserv Profile link for those repositories with functioning (and registered) OAI interfaces. This generates a graph showing the breakdown of all file formats contained in the repository. Users can click on a format's red bar to obtain a complete listing of identified records.
4.1.5 OpenDOAR: Directory of Open Access RepositoriesLaunched to the public in late January 2006 by the University of Nottingham and University of Lund (developer of DOAJ), OpenDOAR is sponsored by the Open Society Institute (OSI), the UK's Joint Information Systems Committee (JISC), the Consortium of Research Libraries (CURL, British Isles), and SPARC Europe. Created to support the Open Access movement, OpenDOAR aims to categorize and build a "comprehensive and authoritative list" of OA research archives worldwide. [[31]] Ultimately, the directory will "serve not only as a discovery tool for scholars seeking original research papers or specific digital representations, but also as a developmental tool for repository administrators and service providers who want to build new services tailored to targeted user communities" (Hubbard 2005). OpenDOAR staff verify the data about each repository, "noting new features and directions," in order to enrich and enhance future versions of the directory service. The repositories listed in OpenDOAR have been surveyed by researchers as opposed to automatically identified and listed. This approach is valuable (although initially resource-intensive) when compared to some auto-harvested listings, according to its proponents, because roughly 40 percent of repositories surveyed have been rejected as out-of-scope or non-functional. As of May 2006, the directory lists 380 repositories and offers repository-level keyword searching or browsing with filters by country, content type or subject. Eventually OpenDOAR expects to classify repositories by other parameters and also offer the capacity to search within repositories. Results can be presented in full or short format.
[[32]] Source: http://www.opendoar.org/ (February 28, 2006) Unlike ROAR, categorizations are not mutually exclusive. According to OpenDOAR's data, the vast majority of repositories represent a mix of content types (an average of 3.6 different types of materials per repository) and subjects (an average of six different subjects per repository) and subjects (an average of six different subjects per repository). The utility of the present categories is questionable due to their scope and redundant use. Articles, dissertations, reports and conference papers dominate the content, with very few repositories registering datasets, software or patents. In terms of subject categories, the Social Sciences content surpasses all categories (perhaps reflecting redundancy with the Business and Economics, and Law and Political Science categories); Technology and Engineering is a close second. Most subject categories are quite evenly distributed (falling in the distribution range of 32 to 42 percent). Aligning OpenDOAR's typologies with the repository descriptions is problematic and it is hard to imagine how a system that requires a high level of OpenDOAR staff intermediation will scale up. For example, an institutional repository of a research organization in France (ALADIN) working in the "humanities and social sciences" that "will include articles, technical reports, working papers, images, videos, and more," is coded by two subjects-Earth and Environmental Sciences, and Social Sciences-and by three content types-Articles, Working Papers and Reports. This narrower categorization evidently reflects OpenDOAR's initial focus on research papers and related materials (e.g., theses); expansion of content type listings is desired and intended, given continued funding for this initiative.
Source: http://www.opendoar.org/ (March 2006) The Aristotle University of Thessealoniki Document Server in Greece "contains theses, articles, papers and photos" and is coded as Articles, Dissertations, and Multimedia and with four broad subject codes. This falls far short of characterizing the repository's content or alerting users to its collections (e.g., historical collection of Greek newspapers-1800 to present, photographic archive of traditional 18th-20th century art, or archaeological events in Greek press-1832 to1932). Nor is the repository retrieved when a user searches for Greek newspapers, newspapers Greece, newspapers or archaeology. Since there is only one repository from Greece, it can be retrieved by country. Despite these shortcomings, OpenDOAR is in its early stages of deployment and aims eventually to serve multiple user groups "each with their own expectations, needs and perspectives" making it possible to search, filter, analyze and query the descriptions of each repository in customizable and meaningful ways. Closer collaboration-or an eventual merger-with ROAR seems desirable and would allow combining the best features of each service, as informed by user feedback. 4.1.6 Arc: Cross Archive Search ServiceUpdate Table 02: Arc based on DLF Survey responses, Fall 2005
As was the case in 2003, users are informed that Arc "is an experimental research service of Digital Library Research group at Old Dominion University. Arc is used to investigate issues in harvesting OAI compliant repositories and making them accessible through a unified search interface. It is not a production service and may be subject to unscheduled service interruptions and anomalies." In fact, Arc was unstable during the five-month period while this report was written, making it difficult to evaluate fully. Arc researchers report that they have been working on a fast, parallel search-based, robust new version that should be available by mid-June 2006. It is based on Lucene parallel indexing. Arc contains more than seven million metadata records, including 4.3 million from OCLC's XTCat (bibliographic records of dissertations and theses extracted from WorldCat, which has been static since its initial harvest several years ago). During the six-month period of this review, Arc remained static in size. Access to the "Administration" page that contained details about the last harvests when this service was reviewed in 2003 is now restricted and inaccessible. With few exceptions, Arc's search and retrieval functions have not changed since the last report was released nor have the problems identified in conducting searches been addressed (further evidence that Arc is intended for R&D purposes-not for end-users). However, two new features are worth noting for their (as yet unrealized) potential usefulness. In advanced search mode, there is an option to "search the last results" or conduct a "new search." In addition, queries can be limited within a specified archive to particular "archive sets." In most instances, unfortunately, the archive only has the default option-"all sets"-available; however, two examples with "archive sets" illustrate the value of this feature. A search of the University of Nottingham's repository can be limited to one of eight constituent departmental archives; similarly the National Science Digital Library (NSDL) development site at Cornell can be filtered to eight different collections. In cases where repositories have meaningful sub-collections of materials, this filtering device would prove very useful. In "Lessons learned with Arc, an OAI-PMH Service Provider," Liu et al. (2005) inform readers how Arc-which introduced the concept of "hierarchical harvesting" that formed the basis for OAI aggregators-has served as the platform for other projects including Archon (described in the 2003 DLF report and included in Appendix 3 of the current report), Kepler (enables self-archiving by means of an "archivelet"), the Networked Computer Science Technical Reference Library (NCSTRL), and DP9 (an OAI gateway service for Web crawlers). Among more recent initiatives undertaken by the Department of Computer Science at Old Dominion University, the Digital Library Grid, funded by The Andrew W. Mellon Foundation, is developing software tools that take advantage of grid computing so that costs associated with federating heterogeneous digital libraries are more effectively distributed, thereby improving sustainability. "Because of Arc's immense scale," these researchers rightfully conclude, "it has informed the community on a number of issues related to synchronization, scheduling, caching, and replication." Their current work will "merge OAI-PHM digital libraries with grid computing," helping to secure the technical architecture and infrastructure required by large-scale operations (Liu et al. 2005, 602). 4.1.7 OAIster
With Arc serving primarily as a research test-bed, OAIster is the only large-scale OAI multidisciplinary aggregator operating as a full production service for the benefit of end-users. OAIster harvests metadata on a weekly basis and prominently notes new "institutions" and new record counts on its home page. (This was recommended in the 2003 DLF report.) Growing by leaps and bounds, as of mid-May 2006, OAIster harvested five times the number of metadata records from more than triple the number of institutions as it did in mid-2003. A hallmark of OAIster is that it limits harvesting to OAI-compliant records that have full digital representation associated with the item (e.g., full text, digital image, etc.); however, it is important to note that OAIster's definition of "freely available" includes some full-text licensed resources. The most prominent example is the inclusion of the Institute of Physics' journal articles (210,000 records), but there are others such as African Journals Online (18,000 records). OAIster is currently re-thinking its collection parameters with the intent of broadening its scope to embrace items with restricted access to full-text. In addition to providing users with a collection development policy, it would be helpful if OAIster's search results marked items only accessible through licenses or if it permitted users to filter results by restricted versus non-restricted access. Since 2003, three enhancements to OAIster's user interface stand out. First, "dataset" was added as a "resource type," making it possible to limit searches to this medium. A keyword search for "data" coupled with the filter to retrieve "datasets" returned 280,495 results. Searches can be refined or limited by selecting among the institutions highlighted in the left-hand frame. Twenty-one institutions hold datasets, and at a glance, it is evident that the vast majority of them (279,286) come from one source-PANGAEA: Publishing Network for Geoscientific and Environmental Data. The second enhancement dates from November 2005 when OAIster deployed a "bookbag" feature, enabling users to save records during a session and download or email them. Most recently, in March 2006, OAIster added "language" as a search field option. A search for <Afrikaans> returns one dissertation from the Netherlands but <German> returns more than 74,000 results. (More than half of these records are from Bibliotheksservice-Zentrum Baden-Wurttemberg although more than 120 different archives in OAIster hold German-language materials.) OAIster makes a vast reservoir of digital content available, but constructing effective searches is not always straightforward, requiring, for example, an understanding of how terms are combined and nested. As evident from the following search results for dissertations on global warming, the first two terms are nested together and then coupled with the third term:
Many enhancements depend on the concerted efforts of data providers, achieved by conforming to accepted standards and best practices. For example, effective date searching hinges on more widespread uniformity in the metadata expressing dates. When asking, "why normalize," OAIster's Kat Hagedorn illustrates the wide variance in expressing dates in OAIster:
OAIster is exploring how to adapt CDL's date normalization utility to help overcome these inconsistencies. [[33]] Browsing by topical categories relies on appropriate metadata subject tags from data providers. And searching within institutions/collections depends on archives providing "sets" that reflect meaningful sub-collections. For these reasons OAIster's developers are among the key proponents of improving and enriching metadata through DLF's best practices. OAIster is also experimenting with visualization and semantic clustering techniques based on work at Emory University (e.g., MetaCombine project, see SouthComb in section 4.4.9), [[34]] UIUC (e.g., refer to the prototype CIC Metadata Portal in section 4.1.8), and UC-Irvine. Among the more vexing problems, not only for OAIster but affecting other aggregators as well, is managing duplicate records. As Khan et al. (2005) attest, duplication is easy to eradicate when two records have identical metadata fields, but difficult to detect when they differ slightly (for example, due to data entry errors or different practices in expressing an author's name). Using a subset of data from Arc as a test bed, the authors demonstrate a duplication detection algorithm they developed which might be applied to other large aggregations like OAIster. OAIster has identified the improvements that it intends to make as time permits:
OAIster was among the first OAI data providers to collaborate with Yahoo! Search and Google; OAIster sends them metadata on a monthly basis. Yahoo! Search uses the complete metadata records in their search index, whereas Google uses the URLs included in the records to find pages for their search index. These partnerships facilitate deeper indexing than available via regular Web crawling. [[35]] In March 2006, OAIster announced the availability of its metadata for use by federated search engines via SRU and created a Web page with instructions about how it use its metadata outside OAIster's interface (http://oaister.umdl.umich.edu/o/oaister/sru.html). External referrals from general search engines may account for 20 or more times the number of queries than direct OAIster searches. [[36]] While precise data is scarce on the topic, ProQuest has analyzed Web traffic to its Digital Commons' repositories and reports that most users (95 percent) find their way to OAI content via general search engines. This trend decreases slightly over time as users become aware of the repository: after the first year of deployment, external referrals dropped to 75 percent. A growing number of institutional repositories, such as the University of Minho (Portugal), are starting to make OAIster directly searchable from their sites as illustrated by the screenshot below. [[37]]
The prominent inclusion of OAIster helps researchers see how their work fits into a larger scholarly communication framework, bringing increased visibility and the potential for wider impact. For instructions to replicate this integration, refer to "Using OAIster Metadata Outside this Interface" available from OAIster's home page. 4.1.8 Consortial Portals: CIC Metadata Portal, DLF Portal, DLF MODS Portal
CIC Metadata Portal Founded in 1958, the CIC is an academic consortium of the eleven institutional members of the Big Ten Athletic Conference plus the University of Illinois at Chicago and the University of Chicago. The CIC Metadata Portal is a collaborative pilot project undertaken to research issues related to aggregating metadata and testing different user interfaces. As of December 2005, the CIC metadata repository contained more than 550,000 records harvested from 187 digital collections held by eleven of the thirteen CIC member institutions. Nearly half of the records (267,000) are contributed by the University of Michigan; the University of Illinois at Urbana-Champaign accounts for another 22 percent (~125,000). Participating institutions adopt the general CIC collection policy and metadata guidelines. Resources include a wide spectrum of types of information. An estimated 70 percent of the records refer to digital objects (have a referring URL); an estimated 50 percent are restricted access, only available to those universities with licenses to access the content. [[38]] The portal uses the University of Michigan DLXS software also deployed by OAIster, and therefore, exhibits similar advanced search functionality including searching by field, filtering by resource type, and user-control over the ways in which results are sorted. The CIC portal has several resource types not available via OAIster that allow users to limit their queries to sheet music, theses, software and Web sites (but not datasets). It also utilizes an automated process to generate thumbnails and thumbshots from the URLs pointed to in the metadata records (Foulonneau, Habing and Cole 2006). Thumbnails are provided at both the collection and item-level. As of December 2005 only an estimated 35,000 item-level records had thumbnails. [[39]]
From the CIC search portal, users can conduct simple searches, view "featured collections," or browse collection-level records by institution. Unlike OAIster and the DLF portal (described below), the CIC portal has not deployed a Book Bag function that permits users to save results within a session. The CIC is experimenting with four innovative user interfaces:
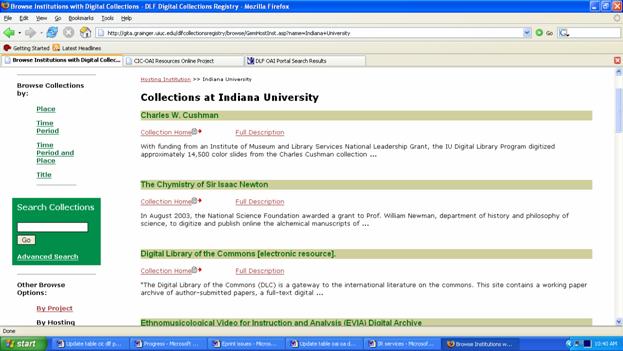
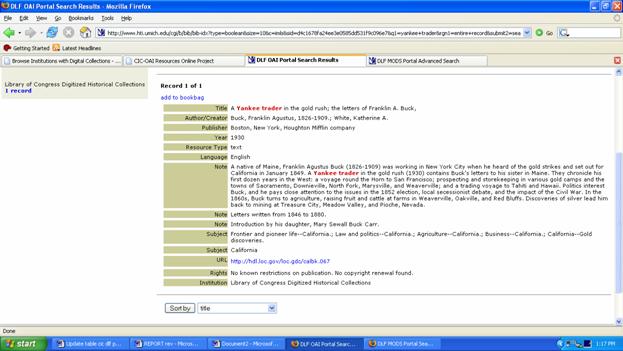
DLF OAI Portal The DLF OAI Portal, in an early stage of development as of May 2006, is a metadata repository containing more than one million items from 45 DLF collections/institutions. DLF's membership includes major research libraries in the United States that are leading the way in digital library innovation, along with a small but influential number of international partners. As a result, this aggregation contains some of the finest digital collections, coming from such prestigious institutions as the Library of Congress, the California Digital Library, Cornell University, Emory University, the University of Chicago, the University of Illinois, Urbana-Champaign, and the universities of Indiana, Michigan, Pennsylvania and Virginia. Once fully developed with more complete holdings from repositories at the Bibliotheca Alexandrina, the British Library, Columbia, Harvard, New York Public Library, Princeton, Stanford and Yale, this portal will offer access to a rich aggregation of premier digital collections. [[40]] Utilizing the DLXS software, the user interface has the unadorned look and feel of OAIster. It supports simple and advanced searches (Boolean operators applied to keyword, title, author/creator/, subject, and language) as well as delimiters by resource type (text, image, audio, video, and dataset). As is the case with OAIster, "Browse Institutions" represents a mélange of both high-level composite general collection descriptions (e.g., Indiana University's Digital Library's multiple digital collections are represented by a composite entry) and specific digital collections within an institution (e.g., the University of Pennsylvania is represented as several "institutions" with separate entries for various digital projects). The descriptions represent both the specificity of information provided by the institution as well as the number of separate data repositories deployed within an institution. In short, there is one description in "Browse Institutions" for each repository in the portal. Users, however, would benefit from a more uniform representation of what constitutes a "collection." After updating its contents, the DLF Collections Registry (described in section 4.4.3) and the DLF OAI Portal need to harmonize their collection/institution descriptions. [[41]] The figures below show the difference in the way Indiana University is represented in the DLF OAI Portal (and OAIster), the DLF Collections Registry, and the CIC Metadata Repository. The user is at a loss to know how many "collections" IU's digital library hosts: three, eight or seventeen?
DLF MODS Portal The DLF MODS Portal, developed with funding from the DLF's current IMLS grant, is the testing ground for new features and functionality that are subsequently ported to OAIster. Among its accomplishments (noted in the description of OAIster above as well) are the inclusion of thumbnails, the bookbag feature, user-choice of simple or advanced searching modes, and improved capabilities for sorting results by date, title and author. In an early stage of deployment, the DLF MODS Portal also serves as a prototype to test out the enriched Metadata Object Description Schema. The MODS element set is richer than Dublin Core but simpler than full MARC. As of mid-May 2006, this portal contains more than 250,000 MODS records from four institutions:
The screenshots above show the differences in record display for two different metadata implementations for the same object, A Yankee Trader in the Gold Rush; The Letters of Franklin A. Buck, from the Library of Congress American Memory collection. This comparison between the DLF OAI and DLF MODS portal reveals how the enriched MODS record, with its more specific tagged fields, makes possible enhanced search and retrieval functions. The DLF Aquifer project (see section 4.4.8) will also require contributing institutions to use the MODS standard for bibliographic data. The DLF MODS Portal will continue to evolve based on needs of the DLF user community and the DLF Aquifer Project. 4.1.9 Germany: OA and OAI Access PointsDINI (Deutsche Initiative für Netzwerkinformation E.V.) in Germany exemplifies a coordinated national approach to OA and OAI adoption. In addition to organizing workshops to promote the Open Access and self-archiving, DINI maintains a centralized directory of OA repositories, establishes quality control through a repository certification process, and operates an OAIster-like search engine across German OA repositories. The directory can be searched or sorted by place, university, URL, contact person, OAI interface, and DINI certification. The DINI certificate distinguishes the repository from common institutional web servers and assures potential users and authors of digital documents that a certain level of quality in repository operation is warranted. In addition, DINI sees its certificate as an instrument to support the Open Access concept. (Dobratz and Schoger 2005)A separate search engine, DINI OAI Search Engine (OAI-suche) for German Open Access Repositories, currently conducts searches across 50 German libraries, archives and document servers, comprising 44,336 items. Repositories are harvested on a weekly basis and statistics about the number of records and most recent harvest dates are readily available. Content is searchable by author, title, keyword, or abstract and queries can be limited by language, date, date range or archive. Users can pre-select whether results should be returned by date and they can control the number of returns per page. A search for <wirtschaft> (economics) returns 740 results with briefly annotated entries and links to full-text content. The Electronic Journals Library (EZB--Elektronische Zeitschriftenbibliothek), with nearly 31,000 titles (an estimated 12 percent are e-only), is arguably the world's largest database of scholarly electronic journals. Operated by the University of Regensburg, EZB represents a consortium of 343 libraries that pool bibliographic information and metadata about freely available and licensed e-journals subscriptions. Ninety-four percent of all German university libraries (n=77) participate along with 80 percent of German national and central subject libraries (e.g., constituents of the Max-Planck Institute). Full-text accessibility is indicated by color-coded dots. An estimated 41 percent of all titles are freely available in full text (i.e. Green).
Source: http://rzblx1.uni-regensburg.de/ezeit/about.phtml Journals are browsable by forty-one different subject areas or by title. Nine subject areas have 400 or more "green" titles (or 63.6 percent of the freely available full-text e-journals).
Source: Based on data from the Electronic Journals Library: Annual Report 2005 (April 2006). In contrast, Chemistry & Pharmacy is represented by eleven hundred titles but only 20 percent are freely available in full-text (221 titles). Users can search for journals by various fields including title, keyword and publisher with the option to limit queries to specific subjects. Through the "preferences" Web page, users can select particular regions or institutions and conduct searches to display their holdings. EZB partnered with the German subject gateway, Vascoda, to incorporate e-journal titles into discipline-specific virtual libraries. [[42]]
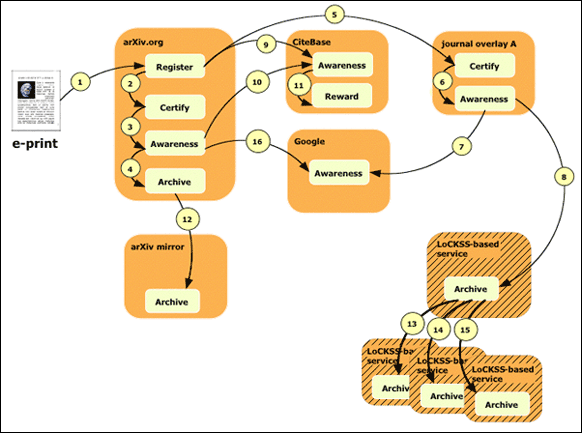
More than forty information services incorporate EZB's content through OpenURL linking. Currently EZB is working with Vascoda to streamline authentication and permissions so only a single sign-on is required to access licensed resources. [[43]] 4.1.10 Current Issues and Future DirectionsThese services now contain a wealth of information. In general, they warrant more widespread marketing and use. At the same time, it would be beneficial to better understand the characteristics of their users and the nature of their uses. "Open access" and "freely available" may carry different meanings in these services. Users are not as concerned about the fine points of definitions, but they would like to know the scope of coverage, what is or is not included. Items that are restricted to licensed users should be clearly indicated. In many instances it is difficult to distinguish records representing metadata-only from those that also link to full-object representation. Users may wish to have access to the broader spectrum of resources, but should be able to decipher whether or not additional content is available and under what circumstances. Application of visualization and clustering tools (by subject, geographic area, time period) helps users to interpret and navigate through large results sets. The database management information from many of these resources is of great value to analyzing the growth in digital repositories worldwide. This data should be readily available for mining by any interested user, ranging from journalists to academics. The synergistic relations between these services help to foster enhanced OAI-compliance, improved coverage, broader use of resources, and better communication between OAI data and service providers. Examples include cooperative efforts between DOAJ and OpenDOAR, OpenDOAR and ROAR, and the UI OAI Registry and OAIster. Further collaboration might lead to more uniform agreement of terminology and better delineation of service coverage while reducing redundancy (e.g., multiple technical registries for OAI-PMH and overlapping lists of publisher/journal self-archiving policies) A recent comparative study (the first of its kind) that investigated coverage of the "OAI-PMH corpus" by three general search engines found that Yahoo indexed 65 percent, followed by Google with 44 percent, and MSN with 7 percent (McCown et al. 2005). According to the researchers, 21 percent of the resources were not indexed by any of the three search engines. The authors suggest that if these popular search engines supported OAI-PMH directly, it would increase interest in registering and implementing OAI-PMH repositories. They conclude: "Search engines would benefit by being able to index more content, and DLs would benefit by being able to share their contents with search engines without incurring web crawling overhead." It might prove worthwhile to call a summit of the core OAI registries and general OAI search services to discuss how to better market their services, not only by extending the reach of their content into these generic popular search engines but also by attracting more users directly to their sites. This would build on various options already deployed such as RSS feeds, A9.com open search, Firefox search engine plug-in, and the development of OA toolbars like OASes, geared to academic users. [[44]] 4.2 Links in the Scholarly Communication Value ChainChanges in the landscape of scholarly communication over the past few years come into sharp focus through a review of how e-print services are evolving. As discussed earlier in this report, in the short span of time since the original report appeared, the open access movement has gained international momentum and engendered a multitude of commitments from major funding agencies, intergovernmental organizations, private and public foundations, university and library consortia, publishers and single institutions. [[45]] Stemming in large part from self-archiving and harvesting of research output from e-print repositories, the aggregations described in this section represent various subject-based services, along with affiliated discovery and citation analysis tools. Connected together, they serve vital functions in the scholarly communication value chain supporting registration, certification, awareness, archiving and rewarding of intellectual capital (see figure 19, Van de Sompel et al. 2004). The specific services reviewed here include four varieties of self-archiving and aggregating content: discipline-driven, centralized, author self-archiving of preprints (arXiv); research agency-driven, centralized archiving of technical reports and harvesting of related archives (NASA Technical Reports Server and CERN Document Server); semi-mandated author or publisher centralized self-archiving of peer-reviewed journal articles (PubMed Central); and community-driven centralized deposit of domain-based literature (Open Language Archives Community). Each of these services was also reviewed in the 2003 DLF survey; the discussion here updates and expands on the earlier report. Special consideration is given to electronic theses and dissertations (ETDs) because they represent a prevalent form of research output. Often aggregated in repositories at the institutional level, ETDs also form the basis of an international community of practice via the Networked Digital Library of Theses and Dissertations. Recent activities to coordinate ETD deployment at the national and transnational level in Europe are described. Finally, tools for discovering ETDs are discussed, most notably Elsevier's Scirus ETD search engine. The University of Illinois's Grainger Engineering Library OAI Aggregation serves as a cross-repository niche search engine, harvesting records from more than 50 data providers including other services discussed in this report (e.g., arXiv, CDS, DOAJ, NSDL). Covering similar territory, PerX, a pilot search engine developed in the UK for engineering, is briefly described. Future DLF studies should include discussion of the U.S., Department of Energy, Office of Scientific & Technical Information (OSTI) E-Print Network Search service (http://eprints.osti.gov/). [[46]] CiteSeer and Citebase round out this section and represent services that support reference linking and citation analysis of research literature. CiteSeer focuses on computer science, aggregating literature via Web crawling and data mining techniques in addition to supporting self-archiving, whereas Citebase covers a broader subject domain in the sciences through OAI harvesting. It is beyond the scope of this report to examine recent parallel services such as Google Scholar (http://scholar.google.com/), Microsoft Academic Search (http://academic.live.com/), and Thomson Scientific's Web Citation Index (http://scientific.thomson.com/free/essays/selectionofmaterial/wci-selection/), but it is important to note that they draw their inspiration and to varying degrees, their core technology, from CiteSeer. 4.2.1 arXiv
At fourteen years old, arXiv.org remains the earliest, largest and most successful example of a subject-based e-print archive, with readership and monthly submissions growing steadily. Warner reflects on "lessons learned" and charts arXiv's evolution from a "self-contained preprint redistribution service" to a key component of "an integrated global communication system" (2005, 58). ArXiv's content is integrated into federated searches and harvested by aggregators on a worldwide basis. ArXiv was conceived as a means to formally communicate and rapidly disseminate research progress, not to replace peer-reviewed journals which are considered indispensable to certification and reward systems. Indeed, arXiv has served as a nexus of innovation by demonstrating "how conventional peer review can be implemented on top of an open access substrate," for example, through the creation of journals such as Advances in Theoretical and Mathematical Physics, Geometry and Topology, Logical Methods in Computer Science and all journals of the Institute of Mathematical Statistics (Warner, 2005, 58-59). Both the American Physical Society and the Institute of Physics (UK) accept direct electronic article submissions from arXiv. Warner discusses the importance of "community" (through the creation of subject advisory boards) and "critical mass" to arXiv's success. To ensure high quality, relevant submissions, in January 2004, arXiv instituted an "endorsement system" that requires most new users to receive ratification from another user prior to submitting their first paper. To support this endorsement system and provide authors with a list of papers they have written, arXiv has established "authority records" that link a person's arXiv account with their papers. In terms of rights and permissions, Warner explains that for many years "arXiv operated without any explicit statements about rights"; it was assumed that the act of submission granted arXiv the non-exclusive right to distribute the paper. Several years ago, arXiv instituted a license click-through as part of the submission process in which the author:
ArXiv created a proxy submission site in France as part of HAL (hypertext articles online at Center for Direct Scientific Communication in Lyon) whereby submissions in relevant subject categories are automatically transferred to arXiv (unless the depositor expressly prohibits it). Similarly, documents for which the full text is already available in arXiv (or TEL-French Theses online) do not need to be uploaded again into HAL; the insertion of a link in HAL makes the file visible. [[47]] Using arXiv as the exemplar, in "Rethinking Scholarly Communication," Van de Sompel et al. (2004) postulate about new ways to combine the five functions of scholarly communication:
When looking to the future, Warner suggests that it is too early to determine what impact institutional repositories will have on arXiv, speculating that the "intermediate stage will be for arXiv to act as a slave subject-based publishing venue with institutional repositories serving as the primary archives, or vice versa" (2005, 67). In the long term, the funding model of institutional repositories, which is more closely aligned with its direct beneficiaries, may prove more viable than arXiv's situation, where the Cornell community comprises only a minor constituency among arXiv's global authors and readers, but has fiduciary responsibility for operating the service with NSF contributing some research funding. 4.2.2 NTRS: NASA Technical Report Server[[49]]
The NASA Technical Report Server (NTRS) aggregates more than 900,000 metadata records from 18 agencies, 40 percent of which are derived from four external (non-NASA) services. Among the fourteen NASA agencies covered, the Center for AeroSpace Information (CASI) is by far the largest, contributing some 540,000 metadata records about 23 percent of which represent full-text documents. The significant growth in content aggregated by the NTRS is due primarily to an increase in records from CASI, the Jet Propulsion Laboratory (not covered in 2003), and the Department of Energy, Office of Scientific and Technical Information's "Information Bridge" (OSTI). Not only have CASI's metadata records nearly doubled but its full-text documents have grown from 100 to more than 90,000. Although according to its Web site, "NASA citations and full-text documents found on NTRS are unlimited, unclassified, and publicly available," most full-text technical reports are not free-of-charge, but can be ordered from NASA. Since the 2003 DLF survey, NTRS use has increased dramatically from an estimated 6,500 searches per month to 17,000 unique visits daily in late 2005. Over the past two years, resources from one NASA agency have been removed due to unresolved copyright issues, the Goddard Institute for Space Studies, [[51]] and another added, the Dryden Flight Research Center (589 full-text papers). As evident from Table 13, five other NASA agency sites are static; NTRS has not recorded any harvests or updates since July 2004. Correspondence with NASA officials reveals that the records for four of the agencies (GENESIS, Goddard, Kennedy and Stennis) were obtained by isolated Web crawls and that RIACS (Research Institute for Advanced Computer Science) has ceased operation of its e-prints software system. [[52]] (RIACS technical reports can be downloaded directly from its Web site.)
Among the four external archives, only two are actively harvested-the UK's Arc service, which comprises historical documents (and is also static at 2,647 reports) [[56]], and OSTI, which continues to grow. Neither arXiv nor BioMed Central, despite their continual growth, have been harvested or updated at the NTRS site since July 2004. Harvesting of these two services was possibly curtailed (users are not informed) as a result of NASA's emphasis on upgrading the functionality of their own publications and the technical capabilities of the contractor operating NTRS. [[57]] This narrowing of focus is supported by an examination of user log files from April 2003 to June 2004 that shed data [[58]] on which NTRS repositories received the most downloads. "While contributing significantly to the total number of holdings in NTRS," Nelson and Bollen found that the "Energy Citation Database [OSTI], BioMed Central and arXiv.org contributed little to the download totals" (2005, 393). The authors postulate that the prominent number of downloads from NACA and the UK's Arc "suggests an interest in historical aeronautical publications." [[59]] They also speculate that users are most interested in aerospace-focused materials and that the "presence of other STM [scientific, technical, medical] materials has yet to expand its user base." Noting that arXiv is harvested by a host of other services, Nelson and Bollen conclude that its presence does "not guarantee its use in NTRS" (Nelson and Bollen 2005, 393). Search Features Whereas Simple Search defaults to NASA-only agencies, in Advanced Search users are given the option to select among twelve NASA agencies and four external archives. If a deliberate decision was made to cease from actively harvesting metadata from arXiv and BioMed Central, users are not warned from either Advanced Search (which is used twice as much as simple search according to Nelson and Bollen) or from the "Help" page. Users need to consult "About the Collections," browse by archive and sort results by date added to NTRS, or utilize the "Weekly Update" function to ascertain the status of harvests and updates for each service. According to NTRS's News Archive, searches were expanded in September 2004 to include accession and document identification numbers. In July 2005, NASA's Scientific and Technical Information Program Office announced the implementation of persistent unique identifiers for all public full-text documents (NASA 2005). [[60]] New User Interface In February 2006, a new public interface for NTRS will launch, featuring direct searching of text files and searching within a browse function (or vice versa) (NASA 2006). According to the January 2006 pre-launch announcement, users will be guided by navigation menus that are recalculated with each new search. When large result sets are retrieved, customized refinement options are presented to the user. Customized browsing options will enable users to look for new related information. The new system also offers automatic spelling corrections and "did you mean . . .?" suggestions. "Navigation and search options are captured in the browser URL," permitting users "to save and share any view of data by bookmarking the link or cutting and pasting it into an email message." Search results are relevance-ranked and sortable. The new NASA interface utilizes the Endeca Guided Navigation search engine. The recommendation service (linking from the results page to recommended related documents) instituted by NTRS in September 2003 was terminated, although this is not noted in the News Archive. [[61]] However, NASA officials are quick to point out that Phase 2 of the new interface (anticipated in summer 2006) will have "recommendation like services." Among its features: Phase 2 will also incorporate multimedia. NTRS as Hierarchical Aggregator As an OAI hierarchical aggregator, NTRS offers the potential advantage of convenient, one-stop shopping for other OAI service providers (Nelson et al. 2003). The scientific search engine, Scirus harvests four NTRS collections (GENESIS, Langley, Marshall and NACA), totaling 12,265 full-text records; OAIster harvests seven (Ames Research Center, CASI, Goddard, Kennedy, Langley, Stennis, and the UK's Arc), totaling 3,466 records; and NSDL eight (GENESIS, Ames, Goddard, Johnson, Kennedy, Langley, Stennis and UK Arc), totaling 8,288 records. OAIster harvests directly from five NASA agencies rather than relying on the NTRS aggregation (e.g., GENESIS, Dryden, Johnson, Marshall, and NACA). (OAIster does not harvest from any collections that do not point to freely available digital objects, e.g., full-text documents). Representatives from NSDL report that NTRS sets are complex and problematic, returning many failed messages. Although NSDL would like to cover more NTRS resources, since mid-December 2005, its only successful NTRS harvest is UK Arc metadata. [[63]] 4.2.3 PubMed Central
Since launching its OAI service in October 2003, PubMed Central (PMC), the National Institutes of Health's (NIH) free digital archive of full-text life sciences journal literature and data managed by the National Library of Medicine (NLM), has become the third largest resource in OAIster (after Picture Australia and CiteSeer). It ranks first, in the category of OAI-compliant peer-reviewed, full-text journal article aggregations; second only to HighWire Press in the number of freely available articles. (HighWire Press, which is not a fully OAI-compliant service, boasts nearly 1.2 million free, full-text articles from 918 journals.) PubMed Central has quadrupled in size over the past two years, providing access to 430,000 articles (including more than 250,000 retrospective scanned articles) from 200 journals by fall 2005. With the advent of its OAI service, PMC also began to accept individual open access articles from journals, such as Science and Biological Chemistry that are not regular contributors to PMC. In May 2005 the NIH put into effect a public access policy, specifying PMC as the central repository of articles emanating from NIH-funded research. According to the policy, researchers are requested to submit to PMC the final version of their peer-reviewed electronic manuscript no later than twelve months after its publication in a scientific journal. NIH offers three primary reasons for endorsing public access:
PMC was chosen as the central repository because it is publicly accessible, a permanent archive, and searchable. In the early implementation of NIH's new public access program (NIHPA), submissions are estimated below four percent of the eligible articles. [[65]] Upon review of these low deposit statistics, the NIH Public Access Working Group recommended a policy change to require deposit by researchers. The CURES Act, introduced before Congress in December 2005 includes a provision supporting public access to federally-funded medical research. ARL reports that "under the proposed legislation, articles published in a peer-reviewed journal would be required to be made publicly available within 6 months via NIH's PubMed Central online digital archive." [[66]] As of this writing, the bill is still pending. Updates about the proposed legislation will appear in ARL's SPARC Open Access News. [[67]] As of December 31, 2005, NIH had received 2,830 articles under NIHPA and 745 were available in PMC. By mid-February 2006, PMC held more than 1,600 NIHPA articles. According to PMC staff, the lag between submission and availability of these articles in PMC stems from two factors: (1) internal processing time, which is typically a few weeks, and (2) an author may delay release of an article in PMC for up to 12 months after publication. [[68]] Meanwhile since July 2005, the Research Councils UK (RCUK) has promulgated an even more far-reaching draft policy that would make all government-funded research in the UK freely available to the public. While it has yet to be adopted, the biomedical community is already leading the way. In June 2004, the NLM announced a cooperative project with The Wellcome Trust, the UK's largest non-governmental funding source for biomedical research, and JISC (Joint Information Systems Committee) to digitize, and make freely available to the public, the complete backfiles of a number of historically significant research journals. Effective October 1, 2005 Wellcome Trust began to require public deposit of electronic copies of any research papers supported wholly or in part by its funding, within six months of publication. [[69]] In response, "Oxford University Press, Blackwell and Springer changed their copyright agreements with authors to allow immediate self-archiving of Wellcome-funded research." [[70]] PubMed Central (USPMC) serves as the central repository while a UK PubMed Central (UKPMC) is under development. The UKPMC site, which will serve as a mirror to USPMC while also accepting UK submissions, is expected to launch in early 2007 with more than 500,000 research articles. The UKPMC represents an alliance among six biomedical research and funding agencies, led by The Wellcome Trust. PMC has eliminated the "SmartSearch" label discussed in the 2003 DLF survey; however, the underlying technology is still used. There are numerous improvements to PMC's search interface and functionality. PMC serves as one of many sources of full-text articles linked to PubMed and MEDLINE citations and the Entrez retrieval system supports access to online books, sequence databases, a taxonomy database and other resources. Users can search the full-text of all SGML or XML-based content deposited in PMC and there are various linking options across articles, issues and journals to commentaries, cited in, referenced articles and corrections. The PMC "Utilities" tab includes an "Open Access List" of journal titles included in PMC with fully or partially open content. [[71]] Author manuscripts resulting from NIH's public access policy have a distinctive page banner and watermark with a left-margin stripe running the length of the record (Figure 20).
In early February 2006, NLM announced that it created a new status tag to PubMed citations, signaling author manuscripts for published articles added to PubMed Central due to the public access policy. According to the press release, the new status tag, [PubMed - author manuscript in PMC], "appears on PubMed citations for articles that would not normally be cited in PubMed because they are from journals that are a) not indexed for MEDLINE or b) do not participate in PMC. This small number of citations can be retrieved using the search: pubstatusnihms. As these citations are processed," PubMed continues, "the status tag will change as appropriate, with a final designation of [PubMed]. To retrieve all citations in PubMed for which author manuscripts are available in PMC, use the search: author manuscript [sb]." [[72]] As of mid-February 2006 the PubMed search query "pubstatusnihms" retrieves 66 articles, whereas the later search query, "author manuscript [sb]" yields 1,655 results.
PubMed Central's phenomenal article retrieval statistics provide persuasive evidence that it attracts a wide spectrum of users. In an editorial discussing the impact of the Journal of the Medical Library Association's (JMLA) participation in PMC, T. Scott Plutchak revels in the increased exposure open access brings to the journal-an estimated 20,000 to 30,000 unique readers monthly or about four to six times the core audience of 4,500 MLA members (Plutchak 2005). However, when evaluating its potential impact on MLA membership and JMLA revenues, Plutchak is more tentative, stating that the "jury is still out," and that "it is too early to label the experiment [open access] an unqualified success." So far, the impressive usage statistics have persuaded him that open access is worth the risk. Only time (and revenues) will tell if the MLA will continue to support public access on a permanent basis. 4.2.4 CDS: CERN DOCUMENT SERVER
Founded in 1954, CERN, the European Organization for Nuclear Research with 20 European member states, constitutes the largest particle physics' laboratory in the world. For more than fifty years, CERN has been an international proponent of "publishing or making generally available" the research results of its experimental and theoretical work, as originally mandated by the CERN Convention (Pepe et al. 2006). Since its inception the CERN Library has operated a document archive and free preprint distribution service. Over the past twelve years, CERN Library services have evolved on the Web as an institutional repository, starting with dissemination of preprints, then extending access to periodicals, books and other library-related materials, and today, integrating all types of multimedia materials including photos, posters, lectures, and videos into the CERN Document Server (CDS). In addition to providing access to CERN documents, CDS harvests metadata from related subject repositories, including arXiv. (In fact, the majority of CDS full-text documents come from external sources. As of mid-February 2006, UIUC Grainger Engineering Library harvested an estimated 70,000 CERNmetadata records, but OAIster only harvests around 38,500 full-content items directly from CERN.) [[73]] Besides hosting documents in the field of high-energy physics (HEP), CDS provides a growing suite of tools and services to facilitate sophisticated searching, collaborative and social networking, and citation and usage metrics (Pepe et al. 2006). The search interface offers the ability to limit queries by field or collection as well as manipulate search results through options in sorting, display and output. Marked results can be saved and stored if users register and log-in. CDS expects to "adopt a comprehensive system of commenting, reviewing and messaging that will allow users and groups to discuss content and share knowledge privately and publicly" (Pepe et al. 2006, 3). CDS also generates a citation index through the extraction of references from full-text documents and uses it to rank documents according to the number of times it is cited by or co-cited with other papers. Finally, the CDS system ranks documents based on the number of downloads and offers users links to "find similar" documents from each result. Presently, CERN estimates that only 30 percent of its scientists' current article production is not available as open access on CDS; moreover, the library plans to fill this gap. [[74]] CERN has achieved this impressive record by steady implementation of practices and policies in support of open access, including adoption of the OAI protocol in 2002 and promulgation of an electronic publishing policy in 2003. The policy encourages:
The LHC collaborations feel positive about exploring new publishing models provided that features such as peer-review and long-term archiving are preserved. It is also of high importance that the funding agencies start to consider publication costs as being part of research budgets. In addition, it was stressed that open access publishing requires a range of actors, as has been the case under the current paradigm, in order to regulate the market and maintain a healthy competition among the publishers. [[77]]As a result of this meeting, CERN formed a task force mandated to bring about action by 2007. In the hat open access publishing requires a range of actors, as has been the case under the current paradigm, in order to regulate the market and maintain a healthy competition among the publishers. [[77]] As a result of this meeting, CERN formed a task force mandated to bring about action by 2007. In the press release, CERN's Director General Robert Aymar gave this endorsement: The next phase of LCH experiments at CERN can be a catalyst for a rapid change in the particle physics communication system. CERN's articles are already freely available through its own web site but this is only a partial solution. We wish for the publishing and archiving systems to converge for a more efficient solution which will benefit the global particle physics community. [[78]]CERN's High Energy Physics Libraries Webzine, freely accessible from the Library's Web site, features articles about recent developments at CDS and in the field in general. For example, an in-depth article about applying usage statistics to CERN's e-journal collection appeared in August 2005 (Dominguez) and two articles from March 2006 examine CERN's continuing participation in Open Access (Gentil-Beccot 2006) and investigate the growth in its metadata and full-text eprint coverage (Yeomans 2006). From 2001 to 2005, the CDS Library at CERN offered high-profile annual workshops on the Open Archives Initiative. Beginning in 2005, the CERN workshops are held every second year in alternation with the Nordic Conference on Scholarly Communication (2006). Presentations (and Web casts) from these conferences are available from their respective Web sites. [[79]] 4.2.5 OLAC: Open Language Archives Community
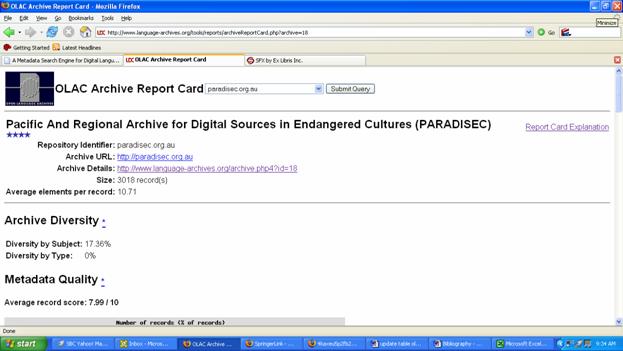
OLAC continues to fulfill its twin stated objectives of developing: (1) consensus on best current practice for the digital archiving of language resources and (2) a network of interoperating repositories and services for housing and accessing such resources. It comprises an estimated 28,000 records aggregated from 34 participating archives. OLAC aims to provide linguists with the data, tools, and advice relevant to the study of human languages, documented in digital and non-digital form from published or restricted sources. OLAC's founders continue to recruit new content by offering tutorials, making conference presentations, and participating in the interdisciplinary research community. [[80]] OLAC actively promotes the E-MELD (Electronic Metastructure for Endangered Languages Data) Project, funded for five years through 2006 by the National Science Foundation. Among other initiatives, E-MELD has created the successful online "School of Best Practices in Digital Language Documentation." [[81]] In summer 2006, E-MELD will host a Digital Tools Summit in Linguistics, held in conjunction with the Linguistic Society of America (LSA) conference. The summit will address the cyberinfrastructure needs of linguistics and extend the work of the "E-MELD Toolroom." [[82]] According to the summit's organizers: Four new archives joined OLAC in 2005. While the number of archives represented in OLAC has increased, half of the content is derived from SIL International (formerly Summer Institute of Linguistics), specifically from SIL: Language and Culture Archives (metadata records extracted from the bibliography of 20,000 citations spanning 70 years of SIL International's language research in over 2,000 languages) and from Ethnologue: Languages of the World (metadata records for each of the 7,000-plus modern languages in the world-both living and recently extinct-identified in the Web edition of this reference work). Two other sources-Digital Archive of Research Papers in Computational Linguistics and PARADISEC (Pacific and Regional Archive for Digital Sources in Endangered Cultures), each contributing more than 3,000 records-make up an additional 25 percent of the content. A number of archives have remained static in size since 2003; 15 archives contribute fewer than 25 records. [[84]] OLAC provides a useful synopsis of search queries for 2005: In 2005, the OLAC Search Engine handled 824,676 queries, an average of 2259 per day or an average 68273 per month. The most popular languages searched for in 2005 were Dutch, English, Quechua, Arabic, Greek, German, Chinese, and Malay. Only 35 percent of queries specified a particular archive, the majority were generic searches across all archives. The most commonly searched repository was SIL-LCA, followed by PARADISEC and SCOIL.An early adopter of OAI, OLAC operates a registry service with guidelines about how to become a data provider (including static repository implementations); conformance testing and validation of new archives is integral to the registration process. OLAC supports a unique metadata standard, based on all 15 elements of Dublin Core, supplemented by metadata extensions with controlled vocabularies specific to the community, including Language Identification, Linguistic Data Type, Linguistic Field, Participant Role, and Discourse Type. [[85]] Since 2003, OLAC developers have introduced an innovative "metadata report card" system to assess the semantic and syntactic quality (as opposed to the structural composition) of the metadata submitted by each archive (Hughes 2004). [[86]] According to the composite Archive Report Card, OLAC receives a score of 6.77 out of 10 points for metadata quality, with an average of 8.77 elements per records. [[87]] Every individual archive is also given a score according to its conformance to OLAC's metadata best practice guidelines. For example, the 3,018 records in PARADISEC have an average of 10.71 elements per record and receive an average score of 7.99/10 for metadata quality taking into consideration the usage of elements and codes in the record.
To inform their "efforts to create good controlled vocabularies," OLAC has also initiated a survey of OLAC metadata implementations that allows "users to see how any attribute or field of OLAC metadata has been used by OLAC archives." [[88]]
Clicking on any element in the survey brings up details about the frequency, language, type, code, and content with which it is used. For example, as indicated below in the top results for "contributor" in OLAC, Arthur Capell is identified as a researcher 859 times and as an author 401 times in OLAC.
Among OLAC's most significant accomplishments since 2003 is its implementation of a Google-style search interface (http://www.language-archives.org/tools/search/). Searches can be conducted across the entire aggregation or limited to specific archives. Features of the search engine include a variety of string matching algorithms; a thesaurus of alternate language names; language code searching; keyword-in-context display in search results; search for similarly spelled words; search for similar items; support for standard string search operators and domain-specific inline syntax; and automatically derived search links for other web search engines. A notable contribution of this research is the inclusion in the search engine results of a metadata quality-centric sorting algorithm (Hughes and Kamat 2005).
OLAC has also implemented a customized version of an OAI DP9 gateway for Web crawlers, facilitating the indexing of its constituent archives' Web pages by generic Internet search engines. In addition, as described in the original DLF survey, OLAC is searchable via The Linguist List Web site (in basic and advanced search modes). [[89]] Full documentation about OLAC is available from its Web site, http://www.language-archives.org/documents.html. 4.2.6 Electronic Theses and Dissertations (ETDs)ETDs continue to figure heavily in the content of e-print repositories and frequently serve as a core component of university IR deployment strategies. The Networked Digital Library of Theses and Dissertations (NDLTD), celebrating its tenth anniversary in 2006, is an international federation that aims to improve graduate education by developing accessible digital libraries of theses and dissertations. NDLTD charges annual dues for membership based on institutional configuration (single degree-granting versus multi-campus systems and consortia) and country of origin. The 2003 United Nations Human Development Report is used to group countries into three categories. As a result, membership fees vary widely, ranging from $100 per year for a single institution from a category II or III country to $75,300 for a consortium with 500 or more members from a category I country. [[90]] The NDLTD Membership Directory is accessible at its Web site and can be sorted by country, name of institution, last update, and join date. [[91]] Every institution is linked to a template that provides more details about its deployment of ETDs, including the number collected, their formats and languages, search and retrieval information, catalog access (OPACs), and organizational contact information. Unfortunately, many institutions have incomplete and out-of-date information. This skews the composite statistics, which would otherwise be quite valuable. Throughout the six-month duration of writing this report, NDLTD's membership site was in transition. There are 231 NDLTD members, constituting 201 member universities (including 7 consortia) and 30 institutions. [[92]] UNESCO's "Guide to Electronic Theses and Dissertations" (2001) and an online ETD tutorial developed by Ohio State University in cooperation with Adobe Acrobat, Inc. and NDLTD (Gray et al. 2005) are available from NDLTD's Web site along with links to NDLTD's annual conference information. [[93]] The site's wiki, launched in October 2005, contains basic documentation, but has not been fully developed as of mid-May 2006. Using NDLTD's membership information and OpenDOAR (described in section 4.1.5) as points of comparison, there are more than 200 institutions in over 40 different countries actively collecting electronic theses and dissertations. Among the 380 repositories registered at OpenDOAR as of mid-May 2006, 227 contain dissertations (and 78 have undergraduate theses). In terms of content types, dissertations are second only to "articles" (with 241 instantiations) in OpenDOAR. Of course these figures give an incomplete picture since not all institutions with ETD deployments are NDLTD members (OhioLink for example dropped its consortial membership in NDLTD, leaving it up to individual institutions to join if they wish) nor is OpenDOAR comprehensive. There are a growing number of ETD aggregations organized at the state, national, and trans-national level. Many such efforts build on long-standing traditions of coordinated bibliographic control of citations and abstracts of theses and dissertations in print form. Notable examples are noted below. OhioLink has a growing online catalog of electronic theses and dissertations from member institutions that includes full-text (circa 7,300) when available. Accessible from: http://www.ohiolink.edu/etd/. The Theses Canada Portal, hosted by the Library and Archives of Canada, (launched in January 2004), contains nearly 46,000 full-text ETDs as of mid-May 2006. [[94]] Accessible from http://www.collectionscanada.ca/thesescanada/index-e.html. In Africa, the Association of African Universities maintains the Database of African Theses and Dissertations (DATAD) which includes a growing number of full-text ETDs. Accessible from http://www.aau.org/datad/database/. In Brazil, the IBICT (Instituto Brasileiro de Informação em Ciência e Tecnologia), funded by the Ministry of Science and Technology, coordinates the library of Brazilian digital theses and dissertations, BTDT (Biblioteca Digital de Teses e Dissertações). Accessible from http://bdtd.ibict.br/. The original gateway to Australian digital theses, (initiated by seven universities in 1998), expanded in scope and re-launched in January 2006 to become Australasian Digital Theses, embracing institutions in Australia and New Zealand. [[95]] To help bring more repositories online, ADT partnered with ProQuest in 2005 to test its Digital Commons Deposit and Repository software (Kennan et al. 2005). This initiative not only brought new content into the aggregation but also increased its user base. (In early 2006, ADT contained about 3,500 ETDs). Nevertheless, a recent study of the impact of mandatory ETD policies in Australia concludes that universities "seem to be wasting their money if they maintain a voluntary deposit policy" and further finds that mandatory policies based on date of submission achieve 80 percent compliance rates five or six years faster than policies dated from enrollment (Sale 2006). For ADT to succeed, Sale advises that it must advocate strongly for mandatory thesis submission policies. He further suggests that if the Australian Government amended its guidelines for Australian Postgraduate Awards (APAs) by requiring graduates to deposit both a paper and an electronic copy of his or her thesis with the university, the ETD deposit rate would increase dramatically as universities would likely extend the requirement to all graduates. (Accessible from http://adt.caul.edu.au/.) On the European front, JISC (UK) and SURF (Netherlands) convened a workshop in January 2006 to discuss ETD trends and issues. The pre-conference survey responses from 11 countries reveal how different cultural, educational, governmental, and legal frameworks impact the deployment of systematic ETD programs in various European countries. [[96]] Many countries have active centrally-managed ETD programs underway. Especially noteworthy are: The Scandinavian DiVA (Digitala Vetenskapliga Arkivet) portal; accessible from http://uppsok.libris.kb.se/sru/uppsok. The Netherlands' "Promise of Science" initiative to make 10,000 e-these available by the end of 2006 as part of its national search and discovery service, DAREnet. Accessible from (http://www.darenet.nl/nl/page/language.view/promise.page. The EThOS Project in the UK, co-supported by the British Library and the Consortium of University Research Libraries (CURL), which aims to develop a prototype e-theses service in the framework of a national infrastructure. Accessible from http://www.ethos.ac.uk/; DissOnline, Digital Dissertations on the Internet, coordinated by the German National Library, where a portal is under development that will enable the integration of domain-specific subsets into the German interdisciplinary Internet for scholarly information, Vascoda (http://www.vascoda.de/) or other services. Accessible from http://www.dissonline.de/. Jacobs (2006a) provides a useful summary of the workshop's findings relative to national trends and elaborates on common thematic issues, including site interoperability, enrichment (links to data/multimedia, and preservation), and management. He notes that a fundamental, and unresolved, issue revolves around whether or not ETDs warrant a separate pan-European gateway or if they should be treated as a manifestation of research output alongside many others, and integrated into a generic European repository infrastructure. Two prototypes under development, DART-Europe and DRIVER, represent these different conceptual approaches. DART-Europe is briefly described below and DRIVER is discussed more fully in section 2.1. (See Figure 03). DART-Europe (Digital Access to Research Theses-Europe) The University College London and Dartington College of Arts in partnership with ProQuest are exploring the creation of a pan-European portal for the "deposit, discovery, use and long-term care of research theses." The DART-Europe gateway would enable "free-at-the-point-of-use access to the full text of electronic research theses," leveraging ETD efforts at the institutional and national level across Europe. DART-Europe intends to move beyond "traditional, text-based material" to embrace "disciplines and institutions that are already widening the definition of research by redefining the formats of theses." Project plans and conference papers are available at the Web site. ETD Software Developments There is no comprehensive source to compare what software systems are used by ETD services worldwide. At present, the best source is ROAR (described in section 4.1.4). Despite its incomplete representation, ROAR offers easy identification of OA repositories with e-theses content through drop-down menus with filters by software system and country. Among the 68 e-theses archives from 19 countries (there are no entries from the U.S. in this category) listed in ROAR in mid-May 2006, Virginia Tech's ETD-db software has the greatest use (23), followed by GNU EPrints (13), DSpace (7), and the Danish DoKS system (3). Two other systems have one instantiation: the Swiss CDSware and the German MyCoRE. Twenty other deployments use various "other" software programs. The base URLs for these systems as well as Fedora are provided below along with links to relevant background information. ETD-db: http://scholar.lib.vt.edu/ETD-db/#about GNU EPrints: http://www.eprints.org/software/ o How to Create a Theses Repository: http://www.eprints.org/software/howto/theses/ DSpace: http://www.dspace.org/ o Theses Alive Plug-In for Institutional Repositories (TAPIR) developed at Edinburgh University Library (Jones 2004): http://www.ariadne.ac.uk/issue41/jones/ o TAPIR SourceForge page: http://sourceforge.net/projects/tapir-eul/ DoKS: http://www.doks.dk/ CDSware: http://cdsware.cern.ch/ MyCoRE: http://www.mycore.de/engl/ FedoraTM: http://www.fedora.info/ o VALET from VTLS: http://www.vtls.com/Products/valet-for-ETDs.shtml VALET for ETDs is a customizable, web-based interface that allows remote users to submit Electronic Theses & Dissertations into a FEDORATM digital object repository. . . VALET for ETDs is offered as a free, open-source solution for web self-submission of ETDs. This solution builds upon our collaborative experience with the NDLTD Project at Virginia Tech, the ADT Program and the ARROW Project in Australia to build a 'best of breed' solution for web submission of ETDs. ETD Union Catalogs and Search Engines OCLC runs the NDLTD Union Catalog using OAI with a SRU service on top. As of mid-May 2006, it harvests 242,458 ETD records from 59 entities, wherein the OCLC ETD set is the largest, with 69,564 records, followed by the Library and Archives Canada ETD repository with 45,795 records. [[97]] The catalog has an undetermined number of duplicate records. OCLC harvests all relevant ETD records including bibliographic metadata only as well as records with associated abstracts or full text, when available. It is estimated that about 70 percent of the records in the NDLTD Union Catalog represent unique full-text ETDs. A variety of services have built search engines based on the NDLTD Union Catalog's harvested records. Among the six options to "browse or search ETDs" linked from NDLTD's Web site (http://www.ndltd.org/browse.en.html), several have restricted access, are out-of-date, or only represent a subset of available ETDs. Among the useful links for digital library developers is the SRU search by OCLC . This Web service machine interface performs remote searches through OCLC's central NDLTD metadata collection. External services and portals may directly connect to this service for seamless integration of ETD searching into any other system (http://alcme.oclc.org/ndltd/SearchbySru.html). [[98]] The VTLS deployment (http://zippo.vtls.com/cgi-bin/ndltd/chameleon) updated in March 2006 after a long period of dormancy contains 160,392 records, virtually all of which have associated URLs to the full text. The user interface can be switched to appear in ten languages other than English, including a number of Slavic languages and other non-Roman scripts, such as Arabic and Korean. The ETD content itself appears in more than 25 languages; however, the vast majority is in English (135,000). [[99]] Users can save search results for printing or e-mailing, and it is possible to review "search history." 4.2.6.1 Scirus ETD Search Engine
The Scirus ETD search engine offers basic keyword or advanced searches that allow Boolean operators and fielded queries (among the 11 options are keyword, author, title, date, language, abstract, and rights). Searches can be limited to a specified range of publication dates, all subjects or any of 19 different subjects. Queries can be conducted within the ETD collection or the "Scholarly Web" at large. Unlike its broader scientific search engine (Scirus described in section 4.5.1), Scirus ETD does not provide any data about its sources, size or scope, other than noting that the data is harvested from the NDLTD Union Archive hosted by OCLC. There is no "Help" page but a query for <ALL THE WORDS: global warming> retrieves 1,257 hits and is automatically rewritten as "global warming." Searches can be refined via a linked list to keywords found in the results. Results can be sorted by relevant or date (descending order only) and users can jump to the next page or in 20 page increments but not to the end of the results. There is no functionality to reorganize the chronological display or to save, store or email results. Worthy of wider attention, is OhioLink's Worldwide ETD search service (http://search.ohiolink.edu/etd/world.cgi). The index is developed primarily from OAI harvesting of collections covered by the NDLTD Union Catalog. Records that appear only to have ETDs available for sale or accessible only on local campuses are removed. [[100]] In addition, the service uses a Web crawler to retrieve a handful of sizeable ETD collections that do not have an OAI service, but which run on Virginia Tech's ETD-db software. As of mid-May 2006, the index contains almost 160,000 full-text, freely available ETDs. The user interface supports field-specific keyword searches. Searches can be limited to retrieve ETDs in "English only" or by level of degree (doctoral or masters). There are several options to sort results for display, but no post-processing features are available. 4.2.7 Grainger Engineering OAI Aggregation (UIUC)
Grainger Engineering Library's OAI aggregation comprises a growing collection of e-prints, technical reports, theses and dissertations, and e-journals predominantly in the fields of engineering, computer science, and physics. The site is accessible from the Grainger Library's "Public Access Menu" (see "OAI Engineering Collection" under Technical Reports), but curiously missing as an option from its main "Resources" page. The OAI aggregation is a target in the Grainger federated search system called Grainger Search Aid, accessible from http://shiva.grainger.uiuc.edu/searchaid/searchaid.asp. Selecting the "Preprints and Open Reports" check box under Technical Reports and Preprint Servers in the left-hand frame will include this aggregation in the federated search. As of May 2006, it covers 51 data providers and has more than one million items. It harvests records from many other services discussed in this report, including arXiv, CERN Document Server, DOAJ articles, OSTI's OAI repository, NSDL, Wolfram Functions, the Max Planck Institute, and UIUC's engineering document collection (16,300 items). The utilitarian user interface and functionality have changed little since 2003 but it is now possible to display up to 500 short results per page as well as track queries during a session with the "search history" feature. There is no help page or advice about how to construct queries but the search syntax is returned with the results. A search for <carl lagoze> in the author/editor field returns ten results for "carl" near "lagoze"-all relevant and drawn from four different source archives (ECS e-prints, dLIST, Cogprints and arXiv). In welcome contrast to many other services under review in this report, users can readily access data about the most recent OAI harvests via a link appearing at the bottom of the search page (http://g118.grainger.uiuc.edu/engroai/LastHarvest.asp). The intended frequency of harvests is not indicated but as of early May 2006, metadata from the majority of data providers has been re-harvested within the past three weeks. A handful of services, constituting more than 300,000 records, have not been re-harvested since January 2006 or earlier. [[101]] The total record count includes an undetermined number of duplicates. 4.2.8 PerX: Pilot Engineering Repository XsearchPerX, a cross-repository search tool focusing on engineering funded by JISC, is the result of a discipline-based landscape analysis and subject-specific inventory of relevant sources (http://www.engineering.ac.uk/). As discussed in section 2.1.2 of this report, the project's methodology, analytic framework, and deliverables are applicable to other disciplines. The pilot search service supports basic and advanced searches. In basic mode, the keyword query box is supplemented by a drop-down menu of options to limit the search by type of resource.
Advanced search mode supports Boolean operators and limiting to specific collections. A search in across all collections for <nanotechnology> returns 2,917 items, summarized by collection with an option to link the results. In this particular search, the most results (1,295) come from the COPAC union catalog, representing the holdings of 24 research university libraries in the UK and Ireland, plus the British Library, the National Library of Scotland and National Library of Wales (http://copac.ac.uk). Clicking on COPAC returns brief item records with the option to view the full record. When available, items are linked to full text. Users can control whether or not search terms are highlighted by turning the "highlight" function on or off. At this juncture there are no post-processing features other than the ability to edit searches, view the last result set or previous search queries. PerX effectively demonstrates how to combine searches across different foundational resource collections (e.g., library catalogs, Web sites, learning object repositories) into a unified search interface. 4.2.9 CiteSeer
Originally created at NEC Research Institute (now NEC Laboratories) by Steve Lawrence, Lee Giles and Kurt Bollacker, CiteSeer is hosted by Pennsylvania State University's College of Information Sciences and Technology with funding from NSF, NASA, and Microsoft Research. Comprising more than 700,000 records, CiteSeer is an autonomous citation index for computer and information science, created primarily through author and archive submissions, and Web crawling, using data mining and intelligent search functions. The recipient of a $1.2 million NSF grant in mid-2005, Penn State and University of Kansas researchers will improve CiteSeer over the next four years. [[102]] According to Principal Investigator, Lee Giles, the next generation CiteSeer project will increase the breadth of the collection and enhance the site's usability and services. Giles outlines the following goals:
A search conducted in early May 2006 of <open archives initiative> returns 64 articles, sorted in descending order by citedness. Lagoze and Van de Sompel's 2001 article, "The Open Archives Initiative: Building a Low-Barrier Interoperability Framework," heads the list with 18 citations. Clicking on the title launches a page with an abstract, offers links to the full-text document in various formats, and links to other citation indicators (citing and cited references), including a graph of citations to the article by year (only up-to-date through 2003). Similar articles based on the text and related articles based on references (co-citation) are generated. References within the original article are listed in citedness order and users can click on any title to identify other articles referencing this citation as well as the context in which the citations occur. Users can rate and comment on articles; they can also submit corrections. In its present stage of development, CiteSeer is not without its glitches. Lagoze and Van de Sompel's article is noted with 18 citations on the opening results page, but with 19 on the detailed page. Moreover, when the author tried to retrieve these 18/19 citations, only seven were available, two of which point to the same article. HELP is available only from CiteSeer's companion search service for business, SMEALSearch, (http://smealsearch1.psu.edu/help/help.html). This page provides basic information about how to construct search queries (advanced and wildcard searches are not supported); describes the user interface; and answers frequently asked questions about algorithms, author contributions, document formats, legal issues and other matters. In his highly favorable review of CiteSeer, Jacsó (2005a) concludes: What it lacks in user friendliness it makes up in smartness, especially in selecting high-quality sources, and in normalizing/standardizing the terribly inconsistent, incomplete and inaccurate citations prevalent in every scholarly field.Effective February 2005, CiteSeer links to the ACM (Association for Computing Machinery) and DBLP servers. [[104]] Based at the University of Trier, the DBLP (Digital Library and Database Project) provides bibliographic information from major computer science journals and proceedings. [[105]] And more recently, Microsoft's new Windows Live Academic search system, launched in April 2006, links to CiteSeer's content (http://academic.live.com/). 4.2.10 Citebase
Citebase, a prototype citation analysis service developed at the University of Southampton, is "an autonomous scientometric tool to explore and demonstrate the potential of OA material" (Hardy et al. 2005, 55). In his 2004 review of Citebase, Jacsó praised it highly asserting that Citebase: . . . shows the perfect model for the ultimate advantages of not only self-archiving scholarly documents but also of linking to full text - and offering citation/impact analysis on the fly to help researchers make an informed decision in selecting the most relevant paper son a topic from a combination of archives. (Jacsó 2004).Over the past two years, Citebase has increased the scope and sources of its full-text content. Previously relying primarily on arXiv, Cogprints, and BioMed Central, as of February 2006, Citebase also harvests OAI metadata associated with full-text documents from 13 additional sources spanning eight countries and representing publisher- and author-based article archives, institutional repositories, departmental archives, national research institutes, international disciplinary archives and university collaborative research teams.
As of February 2006, the database contained more than 430,000 articles, 12.7 million references (of which 2.9 million are linked to the full-text), and approximately 311,000 authors, up nearly 20 percent since July 2005. [[106]] Citebase reports an average of 7,000 users on a daily basis. Extensive usage statistics are available from 2002 to present.
Source: http://www.citebase.org/awstats/ Users can search Citebase in three ways: by metadata (i.e. author, title/abstract keywords, publication title, and the date the article was created), citation or OAI identifier. The metadata search engine provides links to abstract/citations pages or cached PDF files (when available). Results are returned in user-specified descending or ascending order according to one of eight rankings:
Each result is linked to a page of citation tools that provides a graph of the article's citation/hit history; lists all the articles cited by the article (with links out to Google Scholar for each article); identifies the top five articles citing this article (with option to view all articles citing it); and the top five most co-cited articles with this article (with option to view all co-cited articles). The "Correlation Generator" (CG) is a unique tool that provides graphs (or tables) of the correlation between citation impact and usage impact ("hits") from either the UK arXiv.org file or a subset of NASA's Astrophysics Data Service (ADS). [[108]] In effect, the CG forecasts future citation rates based on Web usage. Southampton researchers posit a positive correlation between initial downloads (i.e. derived from preprints in OA archives) and later citations, suggesting that early Web usage statistics can serve as predictors of later citation impact (Brody, Harnad and Carr 2005). Steve Hitchcock offers commentary on various studies about the effect of open access and downloads ("hits") on citation impact in a companion (linked) bibliography. Launched in September 2004 in conjunction with Citebase's umbrella initiative "OpCit," this selective bibliography focuses on the relationship between impact and access. Hitchcock estimates that only 20 percent of research articles are published OA despite a growing body of literature offering preliminary persuasive evidence of its positive effect. One section of the bibliography covers the correlation between research assessment rankings and citations (referred to as "the financial imperative.") Although "it does not attempt to cover citation impact, or other related topics such as open access, more generally," Hitchcock includes influential papers as starting points for wider study. [[109]]
Source: Compiled from Hardy et al. 2005. In the intervening two and a half years since the original DLF report appeared, a variety of studies, surveys, and conferences have explored the impact of disciplinary differences on both the use of digital resources and the preferred means of disseminating research results. The "JISC Disciplinary Differences Report" reviews the recent literature and surveys the scholarly communications habits and preferences of 780 academics, representing a wide variety of institutions and departments in the UK (Sparks 2005). One of the key findings substantiates what is already widely known: the importance of journal articles for the medical and biological sciences; the importance of e-prints (pre and post) in the physical sciences and engineering; the broader mix in the social sciences and the particular importance of books in languages and area studies. The survey also corroborates differences in patterns of collaboration and communication, namely that 'harder' disciplines were more likely to collaborate in the research process, and be prepared to use less formal methods to disseminate results, while 'softer' ones were more likely to communicate work-in-progress informally but rely on more formal means of dissemination. While the survey found a high level of awareness of current debates about open access across the board, it also reported that the overwhelming majority of researchers in all disciplines do not know if their university has an institutional repository. It comes as no surprise that physical scientists (44 percent) are most likely to deposit their work in subject archives whereas academics in the arts and humanities are least likely. The majority of this cohort, across all disciplines favored the mandating of self-archiving by research funding agencies. 4.2.11 Current Issues and Future DirectionsThese resources are at the nexus of key debates about the role and function of different stakeholders in the lifecycle of scholarly information. Authors, researchers, universities, public research funding agencies, publishers, libraries, and vendors are all seeking to reformulate their responsibilities and contributions in view of new modes of creating, organizing, disseminating, and preserving scholarship. Moreover, as evident from the review above, these matters are increasinglng scholarship. Moreover, as evident from the review above, these matters are increasingly played out in highly visible arenas involving national and international advocacy campaigns, policy development, and legislative initiatives. Four inter-related issues come to the foreground:
The Future of the Self-archiving Movement "Ours is just to deposit and die, not to post endlessly reasoning why . . ." Although uptake of self-archiving is on the rise, a survey of author self-archiving habits (N= 1,296) conducted in the last quarter of 2004 found that posting articles at personal Web sites was the most frequent method of publicizing one's work (Swan and Brown 2005). Of the 49 percent who deposited their work, 20 percent used IRs and only 12 percent subject archives. According to another UK study, the vast majority of researchers (N=780) did not know if their university had an IR or not (Sparks 2005). Use of IRs and subject archives for self-archiving varies by discipline, with greatest adoption by physical scientists (Ibid). Swan and Brown report that the vast majority of researchers (81 percent) would willingly comply with a self-archiving mandate by their employer or funding agency. In the absence of such mandates, however, studies in the UK and Australia conclude that only an estimated 15 percent of researchers would voluntarily self-archive their papers. To increase content in IRs, proponents have discovered ways to align self-archiving more closely with the regular work habits and needs of authors, making it a more valuable activity serving multiple purposes (Foster and Gibbons 2005). As described earlier in this report, JISC is working with EPrints.org and DSpace to mesh IR submission workflows with the UK's Research Assessment Exercise. The Netherlands has been at the forefront of devising innovative means to encourage self-archiving. "Cream of Science" program showcases the work of prominent Dutch scholars (http://www.creamofscience.org/) and its off-shoot "Promise of Science" aims to bring in ETDs from young scholars. The actual number of institutional self-archiving mandates is slim at present, although the situation could change rapidly in the next year. At present, four universities in as many countries (Australia, Portugal, Switzerland, and the UK) and two research institutes (CERN and the National Institute of Technology, Rourkela) in Switzerland and India require self-archiving. [[110]] Policy commitments to OA are more prevalent; three countries-the U.S. (NIH), Germany (German Research Foundation) and Finland (Ministry of Education)-have moved national-level OA policies from proposal to adoption. [[111]] An important report released by the European Commission in 2006 calls for "guaranteed public access to publicly-funded research, at the time of publication and also long-term" (Dewatripont et al. 2006). Most importantly, in early May, Senators John Cornyn (R-TX) and Joe Lieberman (D-CT) introduced the Federal Research Public Access Act of 2006 (FRPAA) in the U.S. Senate (Bill 2695). According to Suber: CURES [described above], FRPAA will mandate OA and limit embargoes to six months. Unlike CURES, it will not be limited to medical research and will not mandate deposit in a central repository. It will apply to all federal funding agencies above a certain size. It instructs each agency to develop its own policy, under certain guidelines laid down in the bill. Some of those agencies might choose to launch central repositories but others might choose to mandate deposit (for example) in the author's institutional repository. Finally, while CURES was mostly about translating fundamental medical research into therapies, with a small but important provision on OA, FRPAA is all about OA. (Suber, SPARC Open Access Newsletter, issue #97, May 2, 2006, http://www.earlham.edu/~peters/fos/newsletter/05-02-06.htm#frpaa.)The Association of Research Libraries, Association of College & Research Libraries, Association of Health Science Libraries, and SPARC have all endorsed FRPPA. No matter what its fate, FRPPA appears likely to stimulate other countries to push forward with national-level policy adoption. While the legislation is under debate, it is still instructive to review the findings of study assessing authors' understanding of and compliance with the current version of NIH's public access policy (Hutchings and Levin 2006). The survey, conducted on behalf of the Publishers Research Consortium, gives valuable insights into researchers' attitudes and clues about ways to increase compliance. The author reports overall "high awareness but low understanding of the benefits" of the public access policy. It suggests that authors need more details about how the process works, including:
As of this writing, it is safe to conclude that a combination of social, political, cultural and economic factors will affect the future of self-archiving. Obviously national legislation mandating OA deposit of publicly-funded research, as proposed by FRPPA would have a far-reaching effect. In the absence of mandates, self-archiving must become a meaningful activity in its own right, most importantly by demonstrating how it increases visibility and impact of an author's work or brings other added value to busy scholar's work routines. Also hanging in the balance are the role of journal publishers and evaluation of new OA economic models (Walters 2006). Usage, citation analysis and research impact via Web-based interchange "Collections principle 6: A good collection has mechanisms to supply usage data and other data that allows standardized measures of usefulness to be recorded." NISO, A Framework of Guidance for Building Good Digital Collections, 2004 As scholarship transitions to the Web, understanding what data needs to be collected and what types of analyses are useful to different disciplines becomes an essential undertaking. Analyzing use (views/downloads), let alone its impact on citations, in an open access environment is a complex affair (Hitchcock 2004-present). Project COUNTER (http://www.projectcounter.org/) [[112]] and its recent harvesting off-spring, SUSHI (Standardized Usage Statistics Harvesting Initiative), [[113]] are proving effective as a means to gather e-journal usage statistics, and they are in the initial stages of establishing Codes or Practice for collecting usage statistics from IRs repositories. It is imperative to develop agreed-upon practices for producing article-level statistics from IRs and OA aggregators in the UK because its national Research Assessment Exercise, (http://www.rae.ac.uk/) will move to a metrics-based approach to assessing research quality and allocating "quality-related" public funding after 2008 (UK, HM Treasury 2006). Interoperable Repository Statistics (IRS, http://irs.eprints.org/about.html) is an international effort, led by Southampton University (UK), University of Tasmania (Australia), Long Island University (USA), and Key Perspectives Ltd (UK), under the sponsorship of JISC. IRS complements Project COUNTER and is investigating a coordinated approach to gather and share OAI statistics. IRS, which runs from 2005-2007, has established an international consultative committee that includes principal investigators from various projects reviewed in this report (e.g. CDS, Citebase, DOAJ, OAIster, PubMed Central, SHERPA) IRS expects to "build generic collection and distribution software for all IRs," and to launch a "pilot statistics analysis service modeled as an OAI service provider." Its principal deliverables are:
If successful, IRS will help to overcome some of the challenges noted by OAI services in this section of the report, including scaling, stability, moving from prototype to production services, and most importantly sharing impact values with archives that serve the same documents. The interplay between disciplinary archives and institutional repositories The OAI protocol facilitates interoperability across heterogeneous repositories so in the long-run the distinction between archiving in centralized subject-based repositories versus depositing research in dispersed institutional repositories may become irrelevant. Presently, in certain arenas, there is a creative tension between these two strategic directions. Institutional repositories have taken flight since the 2003 DLF survey appeared. By late May 2006, institutional or departmental repositories comprise just about half of the total listings (341 of 686) in the Registry of Open Archives Repositories (ROAR). They are deployed in nearly 40 countries, with more than 100 implementations in the United States alone. (This is a conservative estimate given the voluntary nature of IR registries.) Their low average number of records, just over 3,000, belies their growing influence on campuses worldwide. Nevertheless, it is too soon to tell if they will become the preferred vehicle for depositing and disseminating research output, gaining precedence over discipline-based archives. As noted earlier, Warner speculates that despite arXiv's overwhelming success, in the long-run IRs may prove more sustainable than subject-focused repositories, which are often dependent on funding from external sources, financially-strapped learned societies or public benevolence on the part of the host institution. Using the field of library and information science (LIS) as an example, Coleman and Roback (2005) argues contrariwise that not all institutions can afford to set up IRs and that subject-based repositories, such as dLIST (Digital Library for Information Science & Technology) and its parent aggregator, DL-Harvest (http://dlharvest.sir.arizona.edu/), may realize economies of scale and have a positive impact on LIS scholarly communication. However, if subject-based aggregators are to "bridge islands of disparities" and achieve their potential, it will require coordinated and strategic planning within the LIS community. In the field of economics, a high profile pan-European effort is underway to create a disciplinary network that provides integrated access to quality economics resources, drawing on submissions deposited in dispersed IRs. "Nereus" is a consortium of 16 university and institutional libraries with leading economics research ratings in eight European countries, developed in collaboration with researchers (http://www.nereus4economics.info/). According to its developers, "a cornerstone for Nereus is Economists Online (EO)," which "aims to increase the usability, accessibility and visibility of European economics research by digitizing, organizing, archiving and disseminating the complete academic output of some of Europe's leading economists, with full text access as key. EO is building an integrated open access showcase of Europe's top economics researchers based on IRs" (Proudman 2006). Nereus's content will be made available through existing subject search engines and aggregations such as SSRN: Social Science Research Network (http://www.ssrn.com/) and RePEc: Research Papers in Economics (http://repec.org/). In the UK, JISC has funded a demonstration project (2005-07) to bridge institutional and disciplinary-based repositories. Known as CLADDIER (Citation, Location, And Deposition in Discipline and Institutional Repositories), it links publications held in two premiere IRs-the University of Southampton and CCLRC (the UK's multidisciplinary research organization)-with data held by the discipline-based British Atmospheric Data Centre (BADC). The goal is to create a system that will enable environmental scientists "to move seamlessly from information discovery (location), through acquisition to deposition of new material, with all the digital objects correctly identified and cited." Experience gained through CLADDIER will be applicable to relationships between other discipline-based repositories and IRs. Economic models of Open Access [[114]] Scholarly publishing-through informal and informal mechanisms-is now in a transitional phase with many unknowns. Willinsky (2006) identifies "ten flavors of open access to journal articles" along with their affiliated "economic models;" he distinguishes the following types of open access (some of which defy strict definitions of OA) and examples:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||