|
1
|
- The Melvyl Recommender Project
- originally presented as a CNI Project Briefing 2006 April 3 by
- Colleen Whitney
- California Digital Library
- and UC Berkeley School of Information
- Peter Brantley
California Digital Library
- DLF reprise
- Brian Tingle
- California Digital Library
|
|
2
|
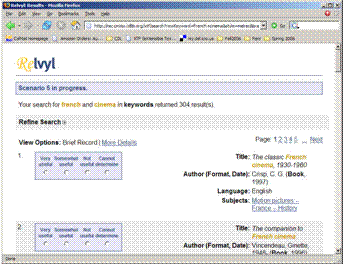
- http://recommend-dev.cdlib.org/
|
|
3
|
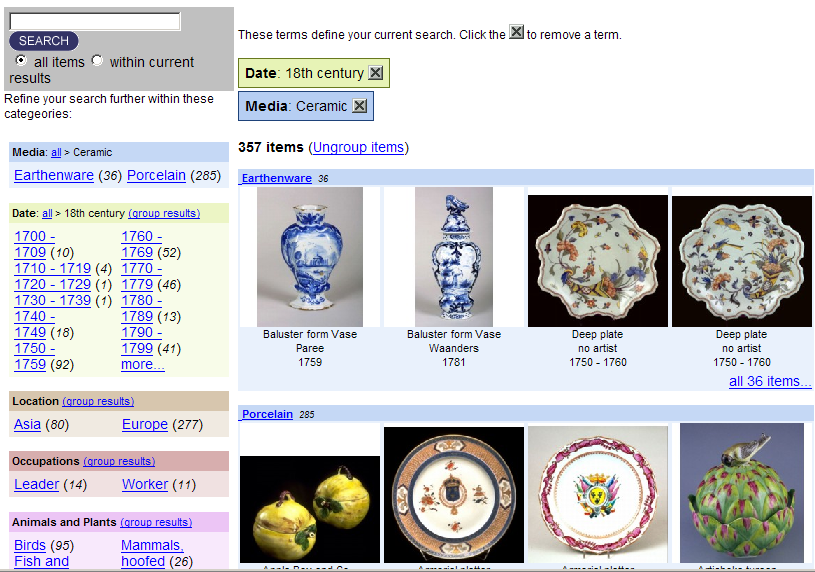
- Fundamental changes in user needs and expectations
- Library catalogs do not meet these needs
- Exploratory project
|
|
4
|
- Text-based discovery system
- User interface strategies
- Spelling correction
- Enhanced relevance ranking
- Recommending
|
|
5
|
- eXtensible TextFramework (XTF):
built on Lucene, Saxon
- Open source, standards-based (XML, XSLT, Java servlets)
- Very different from relational approach
- Built-in ranking capability
|
|
6
|
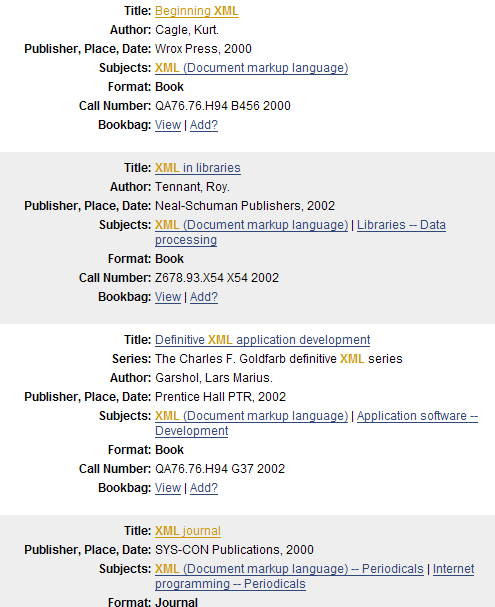
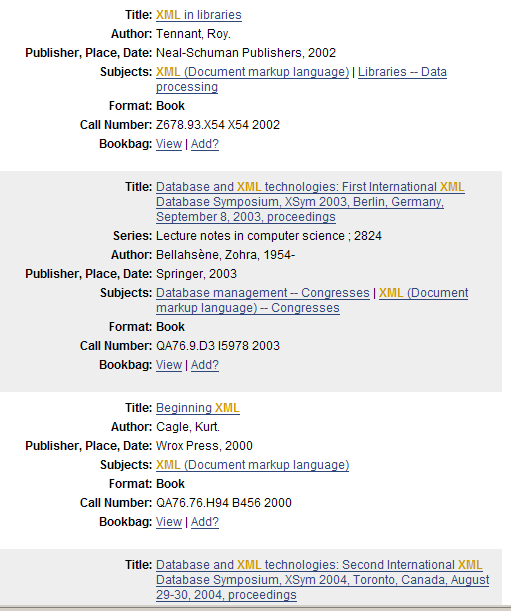
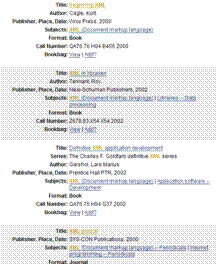
- Bibliographic records
- MARC export from Melvyl
- ~4.2 million UCLA records used in the current prototype
- Experimented with using UCB records as well, for a total of 9 million
|
|
7
|
- Scalability and Performance
- Successfully indexed and searched up to 9 million records
- How will it do with 35 or 40 million records?
|
|
8
|
- Text-based discovery system
- User interface strategies
- Spelling correction
- Enhanced relevance ranking
- Recommending
|
|
9
|
- Asynchronous JavaScript And XML
- Using to call to additional services from outside the core system
- Render the page, then update portions as data arrives
- Adds flexibility while maintaining speed
|
|
10
|
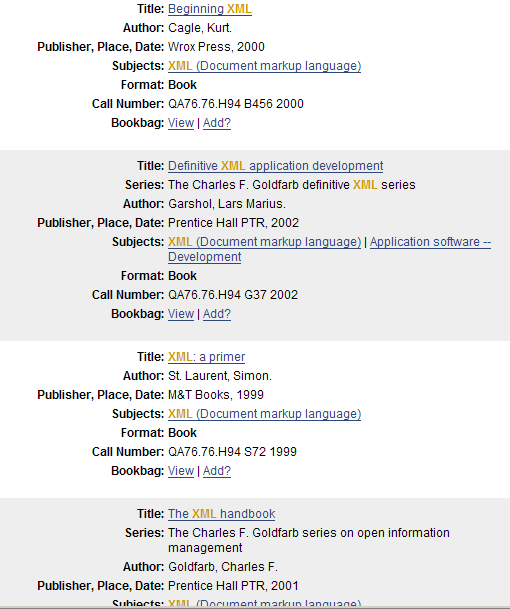
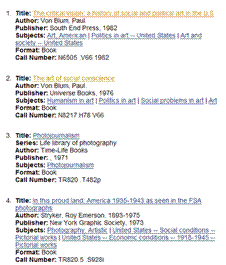
- Functional Requirements for Bibiliographic Records
- Work (Hamlet)
- Expression (in French)
- Manifestation (Presses universitaires de France, 1987)
- Item (UCLA’s copy of it)
- Researching existing implementations
- Analyzing how we would apply the concepts, and how we would implement
|
|
11
|
|
|
12
|
- Underlying mechanics in place
- For effective browse, will require:
- substantial metadata enhancement
- significant UI design work
|
|
13
|
- Text-based discovery system
- User interface strategies
- Spelling correction
- Enhanced relevance ranking
- Recommending
|
|
14
|
- Goal: 90% correct on first try
- Dictionary-based (aspell) vs. index-based
- Proper nouns
- Multilingual environment
|
|
15
|
- Chose index-based strategy
- “N-gram” speller from Lucene:
- “primer” => pri prim rime imer mer
- form query from n-grams
- retain top 100, rank by closeness to original word
- Modified in several ways
- adjust for transpositions and insertions
- use metaphones
- boost on word frequencies
- Tested successfully on Wikipedia and aspell datasets
|
|
16
|
- “Mexaco” => “Did you mean...Mexico?”
- “Javasript” => “Did you mean... Javascript”
- “frehman” => “Did you mean...freeman”
- “flod” => “Your search for flod in keywords returned 12 result(s).”
- “Cailfornia” => “Your search for cailfornia in keywords returned 1
result(s).”
|
|
17
|
- Relative benefits of this approach:
increase in indexing time (construction of bi-grams)
- Consider when to intervene...only on 0 results?
- Multi-word correction
|
|
18
|
- Text-based discovery system
- User interface strategies
- Spelling correction
- Enhanced relevance ranking
- Recommending
|
|
19
|
- Using built-in Lucene capability
- “Boosted” with circulation data
- ~9 million UCLA circulation transactions
- September 1999 – May 2005
- Data from two systems: Taos,
Voyager
- “Boosted” with holdings data
- For 10 UC campuses, provided by OCLC
|
|
20
|
|
|
21
|
|
|
22
|
|
|
23
|
|
|
24
|
- Small-scale user test in March
- Key questions:
- Which ranking method works best for our academic users?
- How do academic users evaluate relevance?
- Is there a difference based on subject matter expertise?
|
|
25
|
- Task-based, facilitated and observed
- Rotated through 4 ordering methods:
- Content ranking only
- Content ranking boosted by circulation
- Content ranking boosted by holdings
- Unranked, sorted by system id
- Grouped by naive vs. expert
|
|
26
|
|
|
27
|
|
|
28
|
- In general, all 3 content ranking methods beat unranked in returning
“Very Useful” items
- All 3 content ranking methods put more “Very Useful” items in top
quartiles
- Preferences differed by expertise
- No clear-cut advantage to a single ranked method
- More queries per task using unranked method
|
|
29
|
- Additional observations:
- All users place strong emphasis on title and publication date in
assessing relevance
- Expert users rely heavily on author
- Many commented that term highlighting helps them assess matches against
the query
|
|
30
|
- Content-based ranking appears well worth pursuing, but consider....
- Adjustments to field weights, given observations?
- Relative costs of incorporating boosts?
- Sources of expanded metadata, which helps users assess relevance.
|
|
31
|
- Text-based discovery system
- User interface strategies
- Spelling correction
- Enhanced relevance ranking
- Recommending
|
|
32
|
- Exploring multiple methods:
- Circulation-based
- Similarity-based (more like this…)
- Same author, subject, call number
|
|
33
|
|
|
34
|
|
|
35
|
|
|
36
|
|
|
37
|
|
|
38
|
|
|
39
|
|
|
40
|
|
|
41
|
|
|
42
|
|
|
43
|
|
|
44
|
|
|
45
|
|
|
46
|
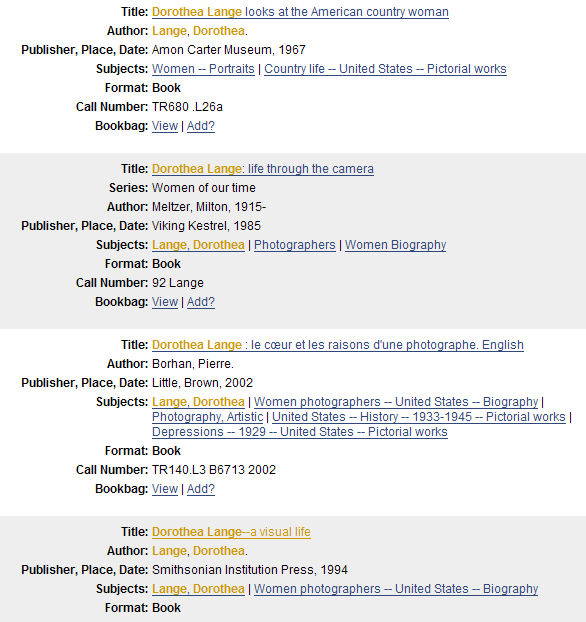
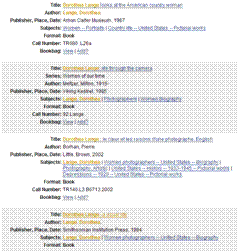
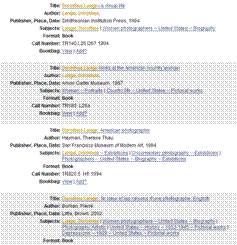
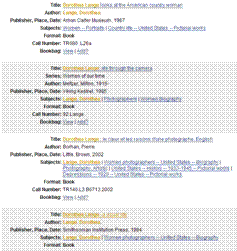
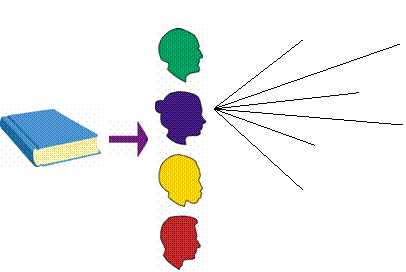
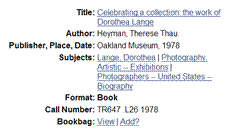
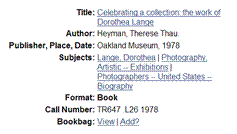
- Generated from content of the record.
- “More like this...”
|
|
47
|
|
|
48
|
|
|
49
|
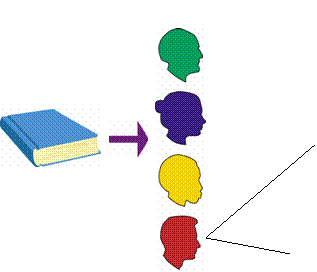
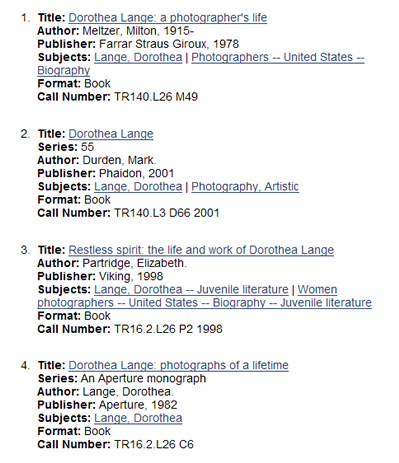
- Integrate several methods
- Author, subject linkages
- Call number “shelf browse”
- “More like this...”
- Circulation-based recommendations
- Limitations of circulation-based method
- Identify other data rich in human-generated linkages....citations,
reading lists...
|
|
50
|
- Completing user tests on circulation-based recommendations this month.
- Wrapping up in June.
|
|
51
|
- Mellon Foundation
- RLG
- OCLC
- UCLA Library
- UC Berkeley Library
- CDL Team
(Peter Brantley, Lynne Cameron, Rebecca Doherty, Randy Lai, Jane
Lee, Martin Haye, Erik Hetzner, Kirk Hastings, Patricia Martin, Felicia
Poe, Michael Russell, Lisa Schiff, Roy Tennant, Brian Tingle, Steve
Toub...)
|
|
52
|
- Project Home:
- http://www.cdlib.org/inside/projects/melvyl_recommender/
- Prototype:
- http://recommend-dev.cdlib.org/melrec/
|
|
53
|
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}