|
1
|
- DLF Spring Forum 2006
- David Newman
- University of California, Irvine
|
|
2
|
- Keyword inconsistency
- Suboptimal subject categories
- Artificial domain or institutional boundaries
- Different subject headings for different collections (LCSH, MESH)
- Controlling subject heading vocabulary
- Managing a dynamic collection
- Designing a good user interface
- Integrating automatically generated topics into existing systems
|
|
3
|
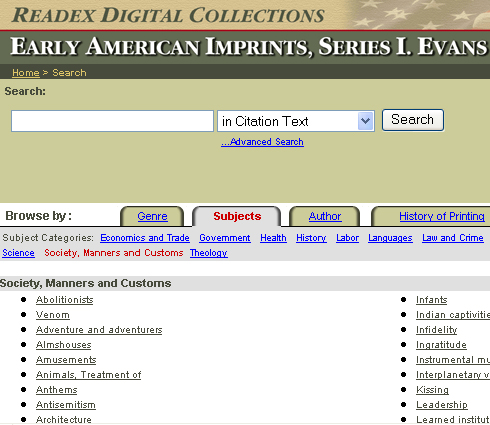
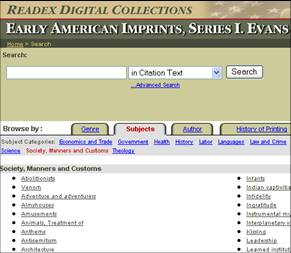
- Example from the Pennsylvania Gazette:
- The top-3 keywords are:
- advertisement (16,000 articles)
- real-estate (7,000 articles)
- runaways (5,000 articles)
|
|
4
|
|
|
5
|
|
|
6
|
|
|
7
|
|
|
8
|
|
|
9
|
|
|
10
|
|
|
11
|
|
|
12
|
|
|
13
|
|
|
14
|
|
|
15
|
|
|
16
|
|
|
17
|
|
|
18
|
|
|
19
|
|
|
20
|
|
|
21
|
|
|
22
|
- Clustering algorithms are similar
- All algorithms start with same bag-of-words representation
- Preferable to use algorithm that can assign multiple topics per single
document
- Quality of result is highly dependent on preprocessing
- Clustering is limited
- Short documents (or limited metadata) can be difficult to categorize
- All methods produce junk topics
- When to freeze topics?
- Human input is required
- Clustering algorithm is automated, but everything else isn’t
- Preprocessing (tokenization and stopword removal) is key
- Need human to interpret topics and assign labels
- Need to choose number of topics
|
|
23
|
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}