|
1
|
- DLF Spring Forum
- Austin, TX
- Tuesday, 11 April 2006
- Bill Landis, Metadata Coordinator, CDL
|
|
2
|
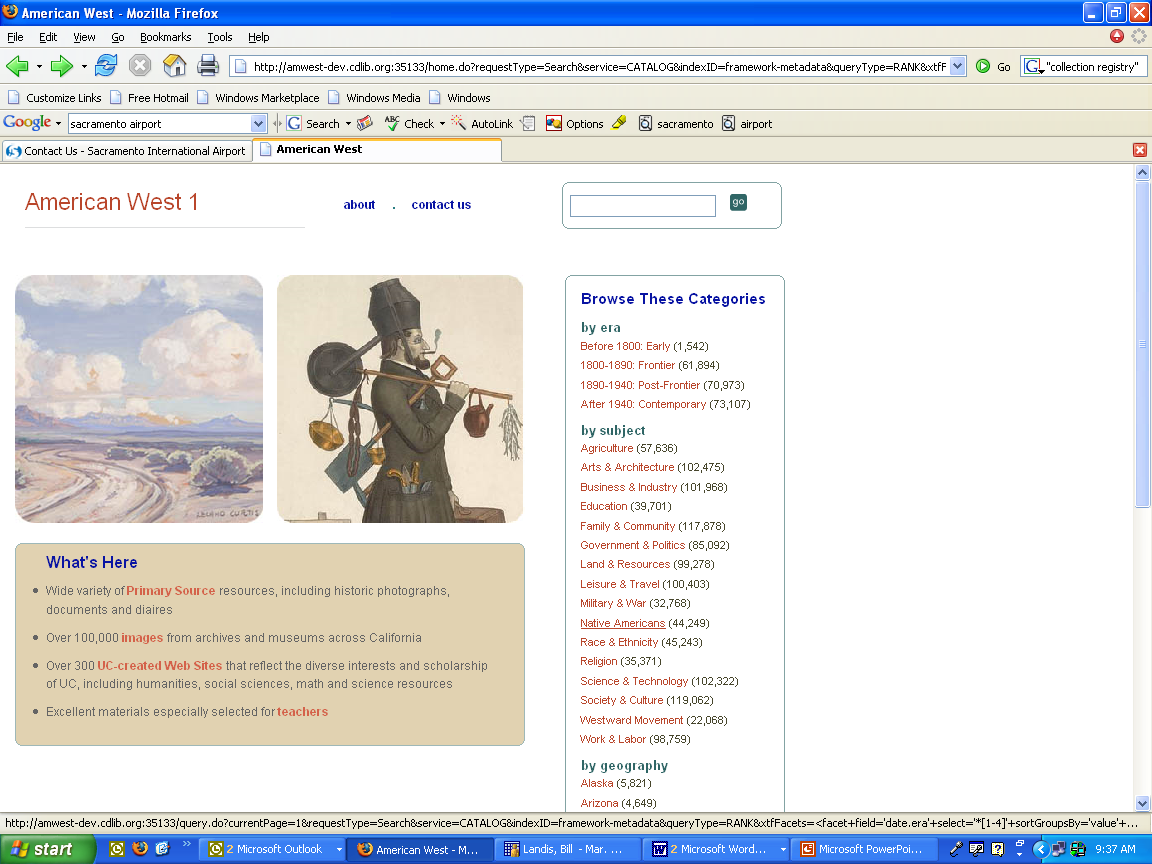
- American West Project (CDL) context for topic enhancement
- Clustering: experimentation & for real
- Issues for ongoing work/cogitation
- Discussion/Questions for Speakers
|
|
3
|
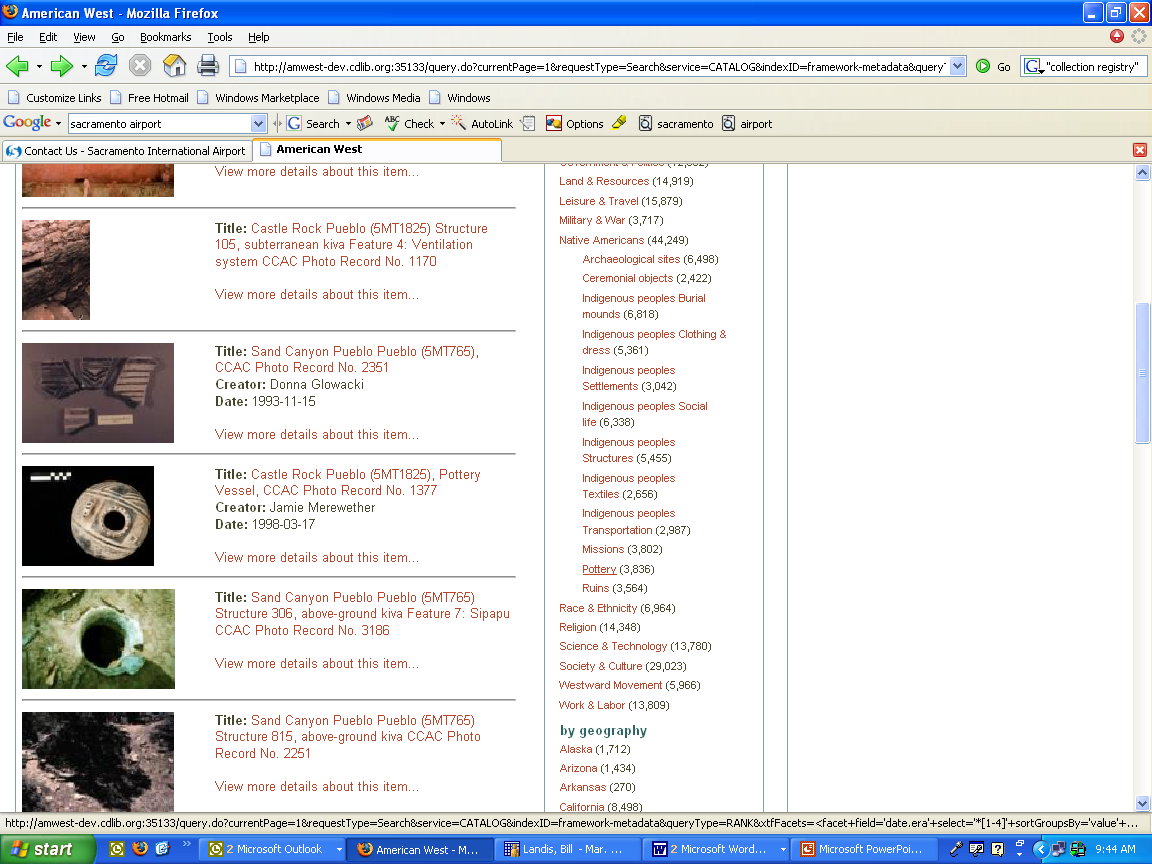
- Assembled testbed collection of OAI harvested metadata (approx. 250K
objects)
- 8 content providing partners: CDL, Collaborative Digitization Program,
Harvard, LC, Universities of IN/MI/VA/WA
- CDL Common Framework repository
- Manage, remediate, enrich metadata objects
- Access platform (XTF indexes, Struts Action Framework)
- Explore CDL infrastructure needs for OAI harvesting and metadata
enhancement
|
|
4
|
- Faceted hierarchical browse surfaced as primary access mechanism
- Inspired by Marti Hearst’s Flamenco project work at SIMS-UCB
- Need to “tailor” specific metadata elements for browse to function
efficiently
- AmWest focus initially on
- Topic, Geographic locations, Dates, [Genres]
- CDL goal to do user assessment on faceted browse (teachers, undergrads,
?)
|
|
5
|
- Experimentation
- Enough metadata in OAI records to get good results?
- Explore process/workload
- Harvested approx. 360K records from AmWest-likely OAI sets from
partners and other data providers
- Did 7 topic model runs on this prototype “collection”
- Used dc:title, dc:description, dc:subject only from harvested records
- “For real” clustering
- Approx. 240K records from AmWest partners only
- Did 4 topic model runs using the same DC elements noted above
|
|
6
|
- convert to lowercase
- remove punctuation
- delete words with £ 2
characters
- replace collocations (e.g. war_relocation_authority)
- apply stemming (‘rivers’ à ‘river’)
- delete words starting with a digit (e.g., dates)
- delete words in stopword list
- delete infrequent words (< 10 occurrences)
|
|
7
|
- Words that don’t contribute topically should be in a stopword list
- Issue of what to do with proper nouns?
- States: remove – captured by Geographical browse facet
- Localities: remove only if they impact topic clustering (e.g., Seattle,
Port Townsend)
- Personal and corporate names: probably best to remove since their
importance as known entities is fairly subjective
|
|
8
|
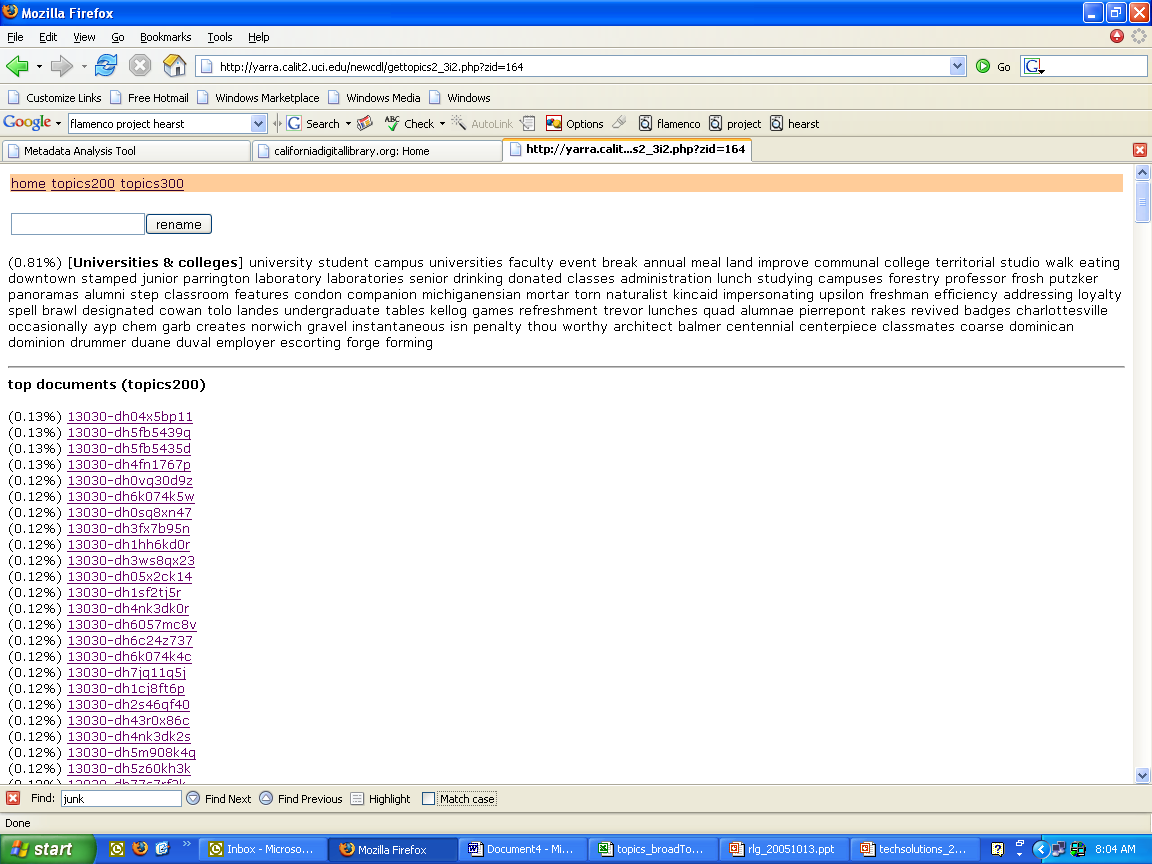
- Reviewed quality of topics using Web-based topic browser
- Does list of most likely words in topic make sense?
- Can we give this topic a label (LCSH, other)?
- Do the most likely objects in this topic seem reasonable?
- Do the topics assigned to each object seem reasonable?
- Assigned topic labels
- Experimental round: LCSH -- too big/granular to work with for deriving
approx. 150 topics
- “For real” round: TGM II, Subjects -- worked quite well for this
particular application with a few stretches
|
|
9
|
|
|
10
|
|
|
11
|
|
|
12
|
|
|
13
|
|
|
14
|
|
|
15
|
|
|
16
|
- And the reason why we’re doing all this work?
|
|
17
|
|
|
18
|
|
|
19
|
|
|
20
|
- Thought we could push all normalization/ enhancement activities up to
point of ingest – NOT!
- Out-of-scope materials have dramatic impact on surfacing topics through
clustering
- “Curators” of digital content need a mechanism for subsetting out
unwanted materials from OAI sets prior to any topic-surfacing
activities
- The better one is able to articulate the scope of a “collection,” and
the more focused that “collection” is on the needs of a tangible
audience, the more successful clustering will likely be
|
|
21
|
- Sustainability???
- With AmWest, we have topically enriched metadata records, but no clear
process at this point for reharvesting or adding additional materials -
YIKES!
- Clustering ÜClassifying
on ingest?
- CDL Experiment (fingers crossed): Can we build a classifier into our
ingest routine for harvested sets to filter records matching 1+ of the
147 topics/word bags we’re
calling “The American West”?
- Maybe at some point need to re-cluster to test validity of those those
topic/word bags and see if additional valid topics can be surfaced?
|
|
22
|
- Metadata for “cultural heritage material” is all over the map and will
likely continue to be so
- Best practices are great, but they won’t directly (maybe indirectly)
get us the consistent metadata we need to drive our specific
applications/implementations
- Why do this at all? Who is the audience?
- This is a bigger question that the Academic/Digital Library community
really needs to explore
- At what level of application does this buck produce a bang?
- Collections to end all collections
- Collections built by front-line librarians to meet very specific,
assessable faculty teaching/research needs
- Bit of both?
|
|
23
|
- Some flavors of it are more straightforward than others (e.g., dates,
maybe geographic location)
- Some flavors of it don’t rely as much on “collection” context (a date
normalized for indexing is a date normalized for indexing …)
- Need a more common understanding of the balance between what we can do
globally/collaboratively, and what makes sense only more locally
- Clustering::global::shared topic label/bag o’ words pairs (e.g., Logging
(LCSH) = logging lumber lumber_company company loggers logs mill
industry crew business timber steam shingle town donkeys log camp
railroad donkey_engine sawmill …)
- Classification::local::remediating specific metadata records for
specific purposes
- Aquifer a possible experimentation platform for arriving at a better
understanding of this balance?
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}