|
1
|
- 10 April 2006
- John Kunze, California Digital Library
|
|
2
|
- What is resolution
- Why we care
- Why it’s hard
- How it can be easier
- Where it can still be improved
|
|
3
|
- Resolution is a computation, possibly performed in multiple-stages, that
maps an identifier to information associated with it.
- Examples:
- Click on id in email, get associated page
- Enter in browser, get list of format choices
- Click reference in document, see metadata
- The id can be of any type:
- URL, DOI, URN, ISBN, ARK, Handle, etc.
|
|
4
|
- Resolution results in access to an associated information object of
appropriate type
- What “the” object is depends on service provider, e.g.,
- a specific representation,
- a menu of sub-objects,
- a metadata record, or
- a 404 Not Found (as result of a completed computation)
- And it depends on the resolution type, e.g., I2I, I2R, I2C
- IETF URI WG conceived all such resolution types
|
|
5
|
- After all, we can ask Google for anything we want
- Ambiguous queries, changing services
- With good resolution (at least to metadata), we get
- Precise reference to information resources
- With good resolution to information resources,
- Actionability (automated access)
- With good, long-term resolution to resources,
- Persistent, precise, actionable reference
|
|
6
|
- A resolver is a system that performs one or more stages of the
resolution computation, e.g., a web server.
- Simplest resolver is 1 server, 1 URL:
|
|
7
|
- Resolvers often work in multiple stages
- Each stage is a resolver
- The “sum” of the stages is a resolver
- Simplest example: familiar redirection
|
|
8
|
- N-stage resolution directed by browser:
- always with us because of Their Stuff
|
|
9
|
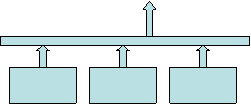
- Any resolver stage may initiate back-end stages
- Like a recursive computation (think DNS)
- Server-initiated resolution is “horizontal”
- Simplest two-stage example: web proxy
- Proxy, as browser target, talks to real target
- In reverse proxy, id-a real target, not URLa
|
|
10
|
|
|
11
|
|
|
12
|
|
|
13
|
|
|
14
|
|
|
15
|
|
|
16
|
|
|
17
|
- Two-stage resolution with only native web tools
- Back to the future
- Updates harvested from memory organizations
|
|
18
|
- Pick a stable hostname:
- Generic: id.archive.org
- Fast, scalable hash table with Apache rewrite
- Harvest using sitemaps (e.g, a la google)
- Examples
- http://id.archive.org/urn:nbn:se:uu:diva-3324
- http://id.archive.org/ark:/13030/tf5p30086k
- http://id.archive.org/doi:10.1111/j.0307-6946.2004.00571.x
|
|
19
|
- Scaling tests and load balancing alternatives
- Update synchronization with service changes
- Security and authenticity checks
- Multiple resolution
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
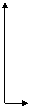{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
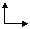{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}