|
1
|
- Martin Halbert & Aaron Krowne
- Emory University
- DLF Spring 2006 Forum
- Tuesday, April 11, 2006
- Austin, TX
|
|
2
|
- Some project context and goals
- Problems with scholarly portal technologies
- MetaCombine Project goals
- Open Source Tools Developed
- Clustering and classification tools
- Focused web crawlers
- Next Steps
|
|
3
|
- A new services created and maintained by libraries for learning
communities, either for single campuses or for multiple institutions
- An emerging field (Examples: OAIster, UIUC portals, Emory portals,
AmWest)
- Usually seek to implement metasearch, through simultaneous searches
across multiple OAI repositories harvested
|
|
4
|
- Metadata problems
- Inadequate (not enough subjects, etc)
- Inconsistent (fields not standardized)
- Important information “realms” not addressed
- Web pages
- Selective parts of library catalogs
- Archives not exposed via OAI-PMH
|
|
5
|
- “I want to be able to browse (not just keyword search) the holdings of a
digital library to understand what’s in it.”
- “Any assemblage of information is subject to bias; I want to know who
selected the sources to include in this database.”
- “I am a scholar of a specific subject; I don’t want to have to wade
through everything in the universe.
Can’t you just show me the stuff that I’m interested in?”
|
|
6
|
- Partnered with teams of scholars to understand how to best design portal
services for research needs, especially in specific subject domains /
area studies
- Developed and adapted open source
software (OSS) tools for metadata harvesting, data providers, indexing,
and searching
- Explored models for inter-institutional cooperation in creating metadata
aggregation networks using OAI-PMH
|
|
7
|
- Can standardized subject taxonomies be assigned and/or derived for ad
hoc information aggregations? (To answer the need: “I want to browse the
collection.”)
- What are the most effective interfaces for browsing such taxonomies?
- Can institutions collaborate on metadata remediation activities through
loosely coupled digital library frameworks?
- Undertaken 2004-2006, sponsored by a grant from the Andrew W. Mellon
Foundation
|
|
8
|
- Classification: assigning information to one or more access points in a
predesignated subject taxonomy
- Clustering: semantically analyzing a body of information to see what
patterns can be found in the corpus, and then create a subject taxonomy
based on these patterns
|
|
9
|
- Clustering and classification tools still need refining, but are
beginning to be genuinely useful for portal functions provided you
invest in required expertise
- Different groups of scholars want to rank and present results according
to different criteria, especially when in a metasearch context where
information from different “realms” is being retrieved
- Loosely coupled DL frameworks can be useful for metadata remediation and
enhancement, but need standards for exchanging information consistently
|
|
10
|
- Clustering tools, using new NMF algorithms
- Classification tools, using training set based on Encyclopedia of
Southern Culture
- Web services framework for inter-institutional exchange and remediation
of metadata, built using OAI-PMH
- Visualization tools for graphical browsing of subject clusters
- (Through affiliated IMLS work) Search engine that can rank results
according to quality metrics of various groups of scholars
|
|
11
|
- Major Tool Groups
- Core clustering
- Visualization and editing
- Focused crawling
- Web services
- Other interfacing tools
- Federated Framework Model (OCKHAM-xform)
|
|
12
|
- "Ab initio" (unsupervised) topic discovery/structuring
- Useful when you must organize resources but:
- You lack an ontology
- You have specialized/nuanced collections
- There is no training set available
- Developed by Aaron Krowne, Steve Ingram
- Our system based on recent NMF algorithm
- Flat and two hierarchical methods
- Depends on Sparselib++
- Also developed support tools:
|
|
13
|
|
|
14
|
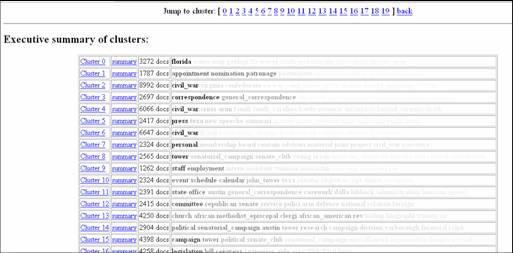
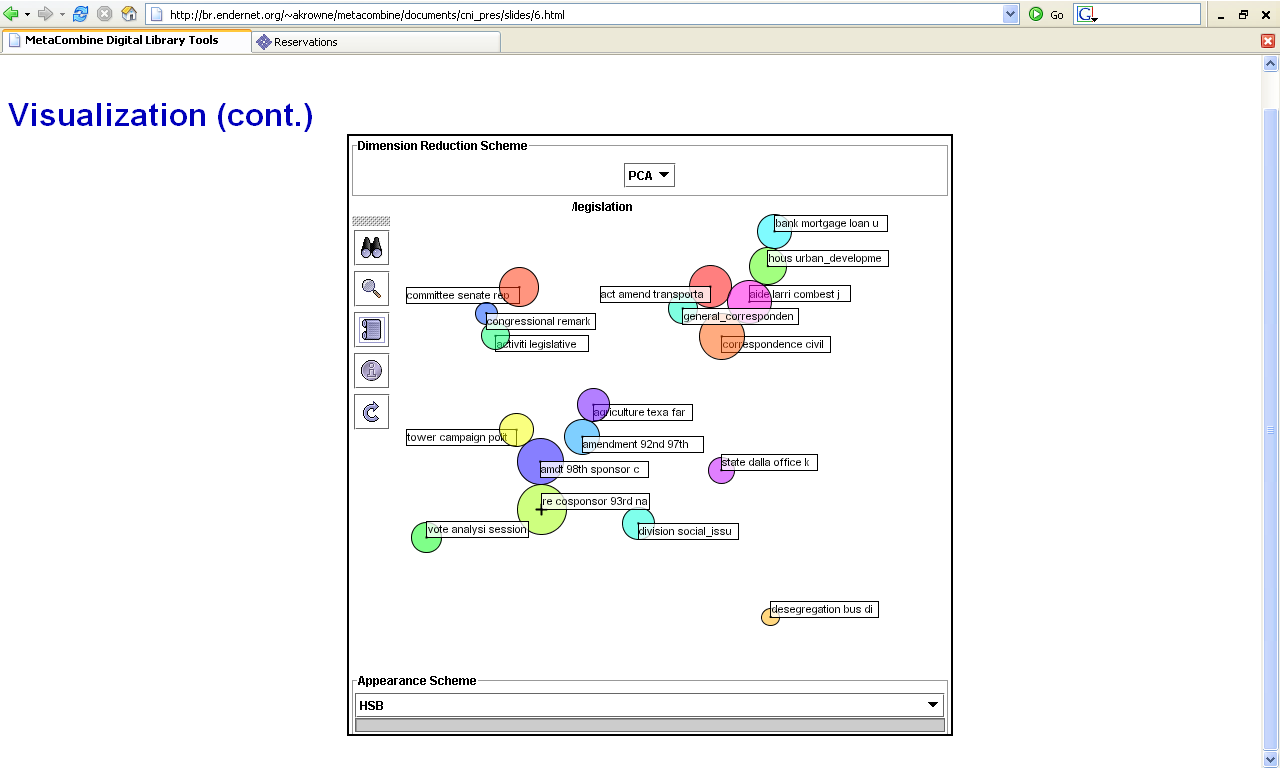
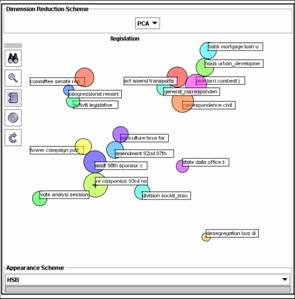
- Navigating/interpreting clustering results
- dev. Steve Ingram (sup. Aaron Krowne)
- Java-based system
- based on Prefuse viz. library
- hierarchical, "drilling down"
- use MDS techniques to project to 2D (PCA and NMF)
|
|
15
|
|
|
16
|
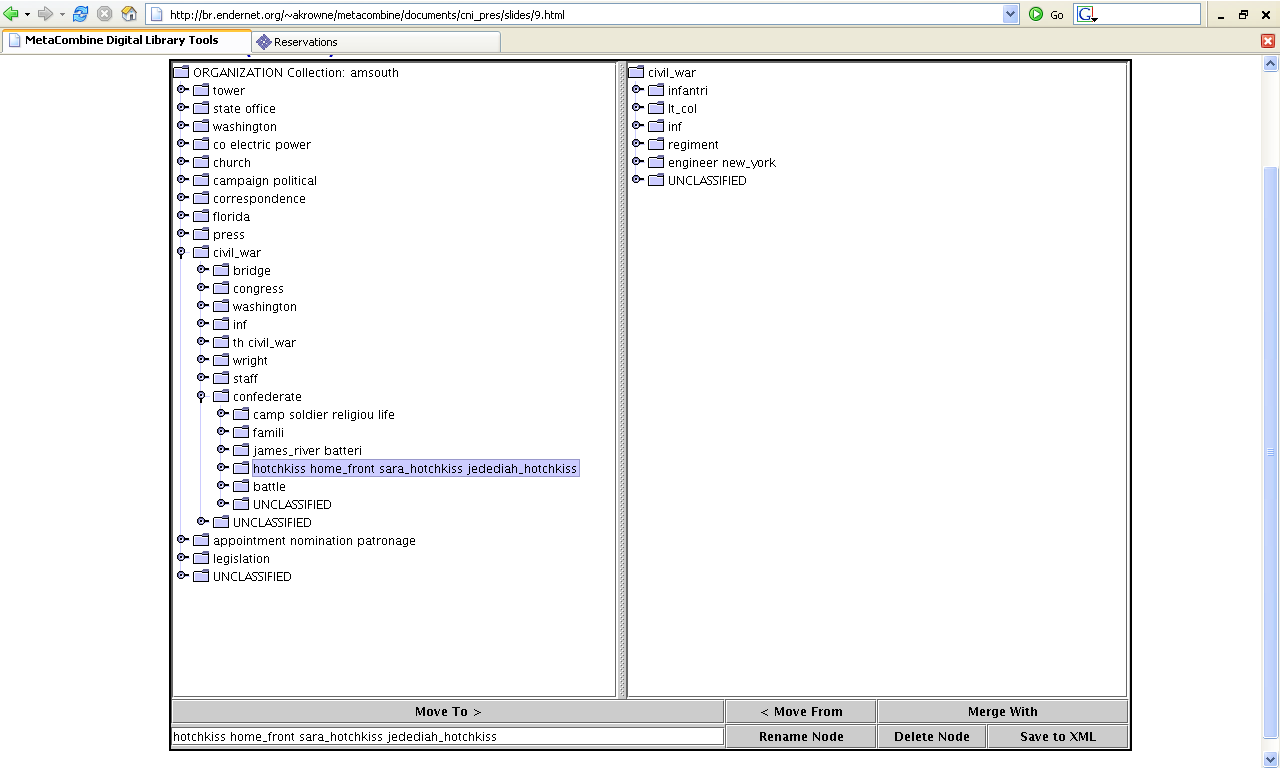
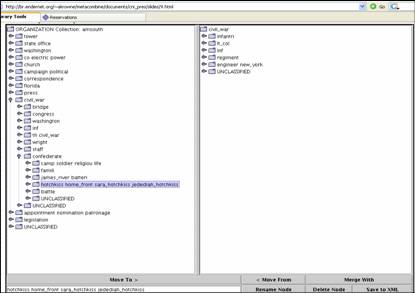
- Massaging/expert tweaking of clustering results
- Dev. Steve Ingram (sup. Aaron Krowne)
- Java-based
- Esp. naming clusters (into "real" categories)
- Merging/deleting clusters
- Works with XML clustering organization files
|
|
17
|
|
|
18
|
|
|
19
|
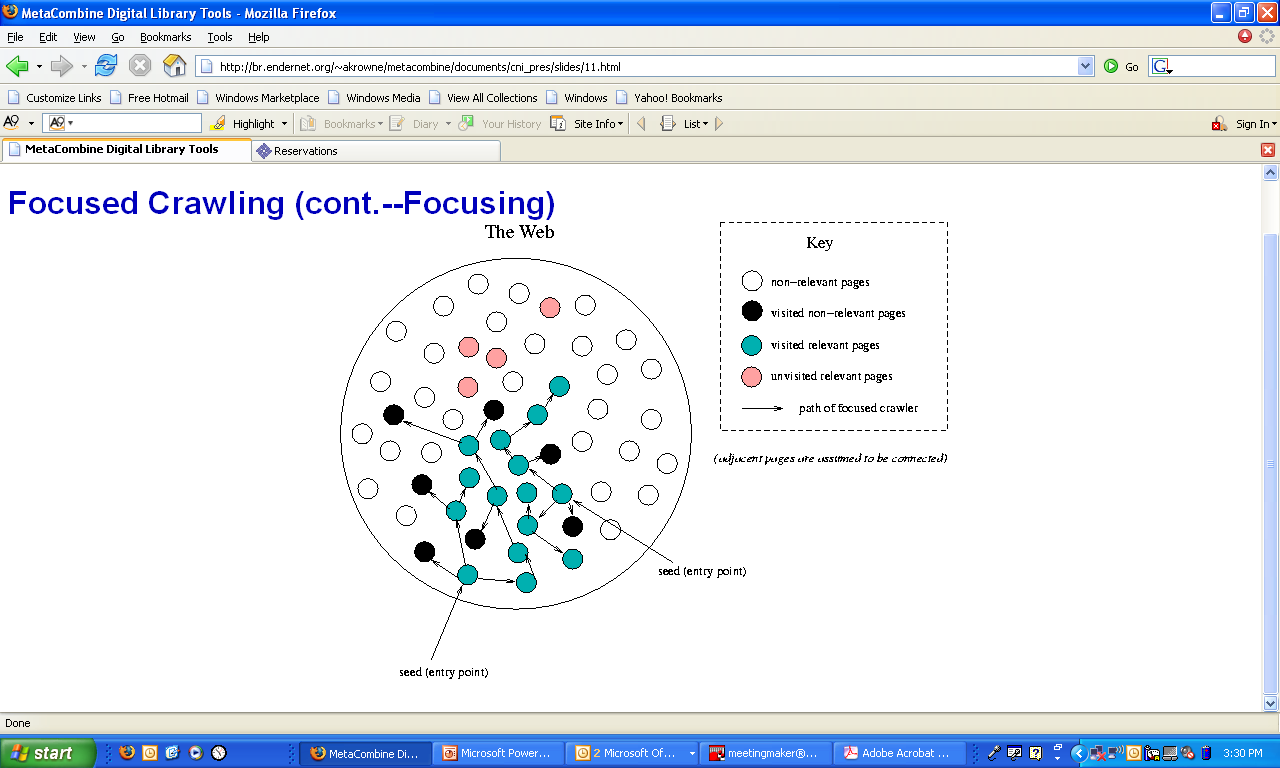
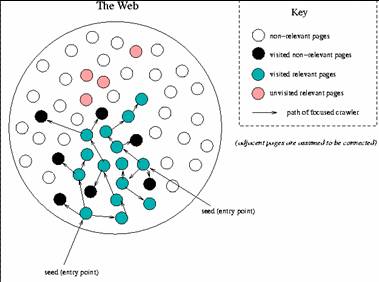
- "Focused crawling system" (FCS)
- dev. by Aaron Krowne, Saurabh Pathak, in cooperation with Donna Bergmark
- Built on Heritrix
- Purpose: efficient, topic-driven discovery of web resources
- "Focused" with a classifier (BOW)
- Based on BOW module for Heritrix
|
|
20
|
- Why build:
- needed something that worked
- need something unencumbered by IP
- need something easier for digital librarians to use
- Guided bootstrapping:
- Ability to utilize phrase/keyword lists
- Gleaning seeds through search engine (Google)
- Seeding through Open Directory (also for negative set)
- Seeding/training via OAI repositories
- Development of phrase lists with phrase finder
|
|
21
|
- Clustering and classification
- SOAP web services as wrapper around actual machine learning systems
- dev. Urvashi Gadi (sup. Aaron Krowne)
- Key benefits:
- Don't need to install machine learning tools
- Don't need to have the computation resources
- Can use training sets to which you may not have direct access
|
|
22
|
- I/O:
- input: OAI repository base URL
- output: new "static" temporary repository at new URL w/set
structure
- alt. output: XML organization file
- Modules (in PHP):
- Server module (depends upon BOW or NMF tool)
- Client module
|
|
23
|
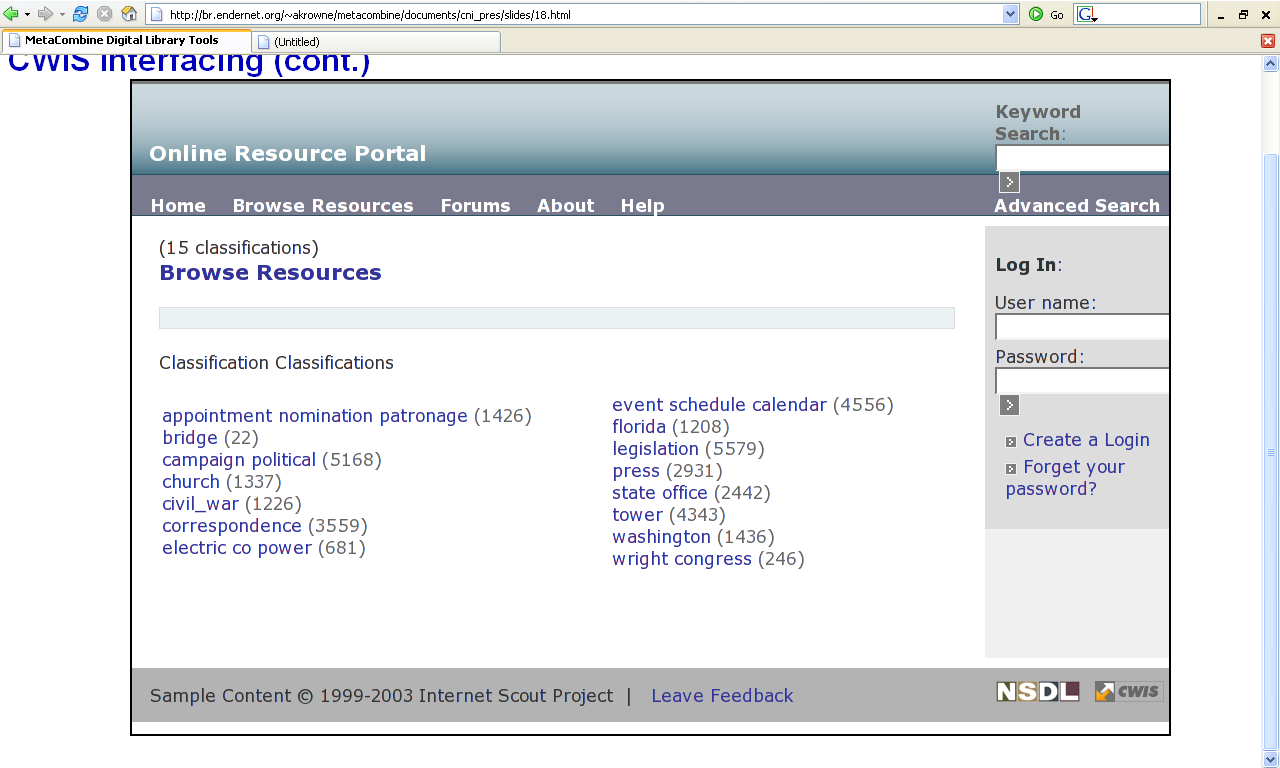
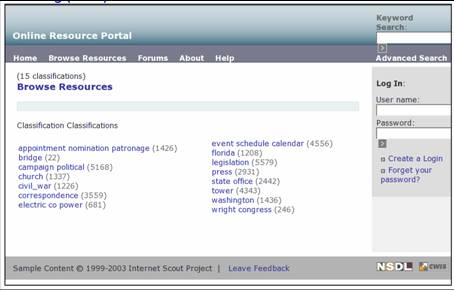
- CWIS clustered scheme import script
- Demonstrates porting of clusterings to mainstream DL software
- I/O:
- Input: clustered organization XML file
- Updates CWIS database to add categories, classifications
- Must also import records
|
|
24
|
|
|
25
|
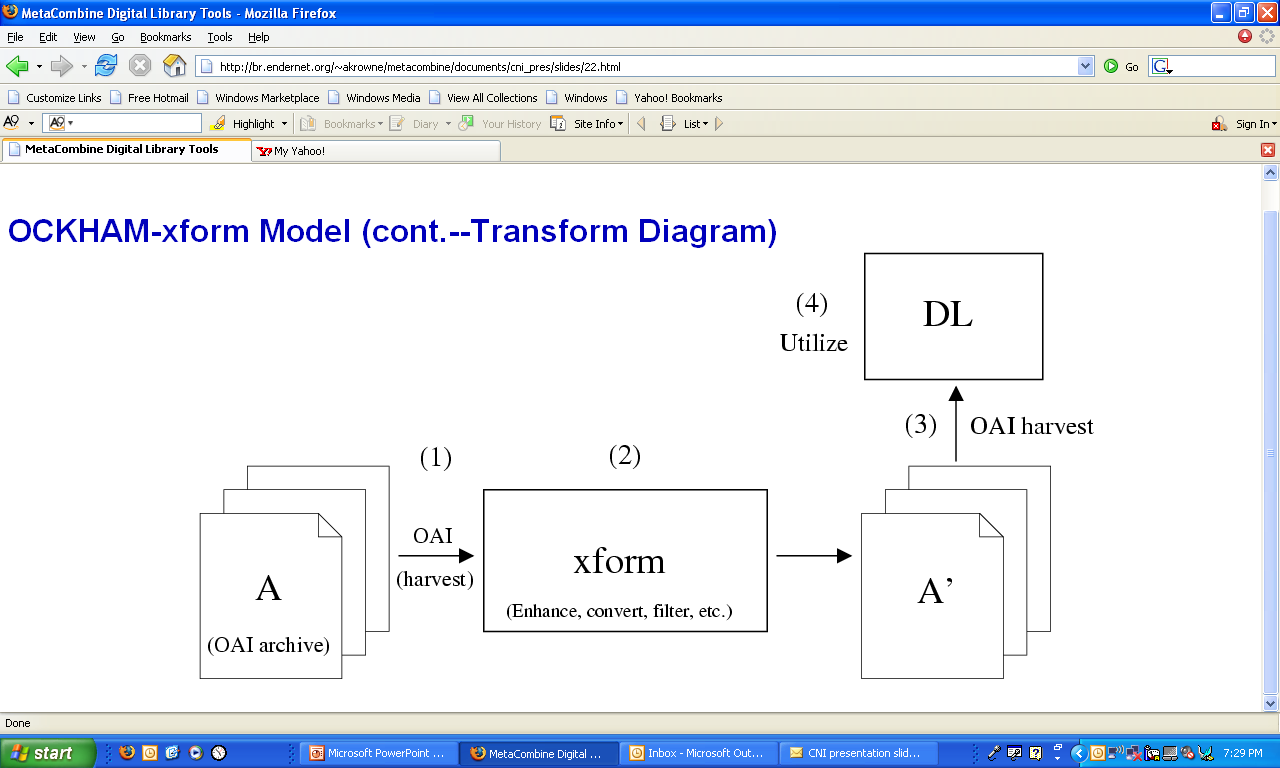
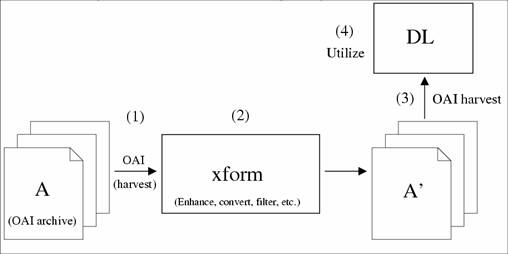
- Use OAI repositories as atomic, portable objects
- These objects can be transformed to useful ends
- The transformed results can be loaded into digital libraries for new
purposes
- Enhanced services can be built upon them
- MetaCombine web services, OAICopy fit into this framework (developed in
the OCKHAM NSDL/DLF project)
|
|
26
|
|
|
27
|
- "Glue" tool of OCKHAM-xform
- I/O:
- Input: OAI repository (base URL)
- Output: "static" OAI repository (OAI-XMLFile-based) in a
subdirectory
- "Save" OAI repository output of Metacombine Web Services
(classification) clustering
- Single, intuitive command: oaicopy < base_url > <
local_directory >
- Afterwards: new OAI repository at
http://your_server/web_root/subdir_name/
- Other uses:
- Repository caching (with no database required)
- Repository upgrading (1.0/1.1 -> 2.0)
|
|
28
|
- "Pipelining" tools/facilities
- Digital librarian-friendly management tools
- More collaborative transform services, e.g.
- Thumbnail generation
- Collection-level metadata augmentation
- Date normalization
- UTF sanitiziation
|
|
29
|
- New funding from Mellon Foundation will go toward developing production
level versions of these services over the next 2 years
- Emory will develop a new portal for Southern Studies based on these
technologies
- Emory will collaborate with other institutions in the DLF Aquifer
project on frameworks for metadata remediation and enhancement –
workshop to be held in Atlanta in July 2006.
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}