DIGITAL LIBRARY FEDERATION
FALL FORUM 2006
BOSTON, MA
NOVEMBER 8 – 10, 2006
The Fairmont Copley Plaza
138 St. James Avenue
Boston, Massachusetts 02116
(617) 267-5300
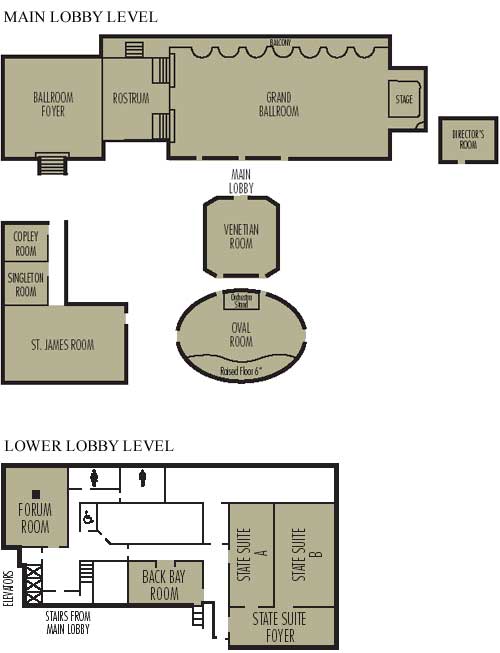
Floor Plan
PRECONFERENCE: Tuesday, November 7
9:00 a.m. – 5:00 p.m.
METS Editorial Board—open to project participants (Guest Suite)
9:00 a.m. – 5:00 p.m.
PREMIS Tutorial—open to all, registration required [see below] (Harvard Divinity School)
This 1.5 day tutorial provides an introduction to PREMIS, core metadata for digital preservation. It covers the PREMIS data model, the Data Dictionary, implementation considerations, and using PREMIS with METS. The tutorial includes hands-on exercises and an opportunity for participants to share their own implementation issues and experiences.
9:00 a.m. – 5:00 p.m.
Workshop on Developing a Services Framework for Libraries—open to all, registration required [see below] (Back Bay Room, The Fairmont Copley Plaza)
This workshop will provide an overview of the work of the DLF Services Framework Group to date and then focus on a hands-on approach to define various library/digital library activities. The workshop attendees will break into three small groups to work through the business logic for three library areas: Digitization, Storage of digital assets, and Discovery of digital assets. The output is expected to be a series of flow charts and a set of decomposed business processes and functions that will be included in the services framework.
PRECONFERENCE: Wednesday, November 8
8:30 a.m. – 12:30 a.m.
Developers' Forum—open to developers from DLF member institutions (State Suite B, The Fairmont Copley Plaza)
The Developers' Forum is intended for senior technology developers, technical managers, or those representatives that have influence in decision-making at their institutions.
9:00 a.m. – 12:00 p.m.
PREMIS Tutorial—open to all, registration required [see above] (Harvard Divinity School)
The 1.5 day tutorial continues. See above for more information.
9:00 a.m. – 12:00 p.m.
NDIIPP Roundtable—open to anyone from a DLF member institution (Back Bay Room, The Fairmont Copley Plaza)
9:00 a.m. – 12:00 p.m.
DLF Aquifer Metadata Working Group Meeting—open to project participants (State Suite A, The Fairmont Copley Plaza)
DAY ONE: Wednesday, November 8
10:30a.m. – 1:00 p.m. Registration (Opposite Teacourt, Main Lobby Level)
11:30a.m. – 12:15 p.m. First-time Attendee Orientation. (Ballroom Foyer, Main Lobby Level)
1:00 p.m. – 1:30 p.m.Opening Remarks. (Grand Ballroom, Main Lobby Level)
1:30 p.m. – 3:00 p.m.
Session 1: Semantics and Resources. (Grand Ballroom, Main Lobby Level)
"Collex: NINES in the Semantic Web." Duane Gran and Erik Hatcher, University of Virginia.PRESENTATION
This presentation describes the technologies behind Collex and and the design for producing a "semantic collections and exhibits builder for the remixable web." We will demonstrate the Collex software and describe opportunities for collaboration and for integration of the system into digital libraries. Collex is designed to be a generalizable, web-based tool for COLLecting and Exhibiting digital resources described with RDF, a standard format for the semantic web. It allows users to search and annotate objects and repurpose them in annotated bibliographies, course syllabi, and illustrated essays. Collex converts the semantics of RDF into a faceted browser with auto-suggest fields to reveal full text search matches in real time. Users produce a folksonomy by tagging objects and creating collections and exhibits. Patterns of use emerge as scholars annotate and repurpose objects. The software leverages these patterns to promote knowledge discovery in our prototype database of nearly 50,000 digital objects from ten scholarly digital editions of nineteenth century British and American literature (the NINES federation). Collex uses Lucene, via Solr, for full-text searching, faceting browsing, and more-like-this queries. Ruby on Rails supports the web tier of Collex. We have expanded on basic Dublin Core with specialized metadata suited to our initial dataset and user research interests. Emerging "Web 2.0" or "Ajax" technologies make the application immediately responsive to user actions such as search, object collection and annotation. We also provide syndicated Atom feeds for user-created tags and metadata facets. Features coming soon include drag-and-drop exhibit building, saved searches, and exposing more of Collex data with other information environments.
"Swimming in the Resource Pool: The USC Libraries' Gandhara Project." Todd Grappone and Zahid Rafique, University of Southern California. PRESENTATION
The original goal of USC's Gandhara Project was to provide a search interface to all metadata regarding resources and locally produced research. This goal has largely been realized.
By combining a simple locally developed XML wrapper technology with open-source software and programming labor resources, we have developed an elegant open standards based library information system that will be the basis for our future knowledge systems at USC.
We created a system to organically store, index and represent items regardless of format or origin. In addition, by using XML and open standards we are developing a user-centered tool for designing online libraries.
Using ingest harvesting and crawling technology, Gandhara creates a single search interface to the USC ILS, the USC Digital Archive, Institutional Repository, online chat reference sessions, the usc.edu web site as well as the medical library catalog.
Not only does Gandhara offer new bibliographic services but it also allows for backend flexibility. In the system currently being developed, indexing is not wedded to a single metadata standard; any resource that produces XML can be indexed and searched.
By focusing on developing collection-to-collection and collection-to-user data feeds, the "locked box" of an ILS is opened. This paper presentation will discuss the development of the system, a demonstration of the current system and next steps.
"SIMILE-Semantic Web browsing in DSpace." MacKenzie Smith, Massachusetts Institute of Technology.
Project SIMILE has created a new faceted browsing interface for the DSpace institutional repository platform that demonstrates the value of RDF and Semantic Web technology for that category of digital library systems. The new UI will be demonstrated, and its implications for DSpace and other IR platforms discussed. Since 2003, the MIT Libraries have been conducting a research project called SIMILE to demonstrate practical applications of Semantic Web technology for digital libraries, particularly in the area of metadata interoperability. The project has recently developed DWell, a faceted browsing interface for the DSpace digital repository platform based on the Longwell (general purpose) faceted browser. DWell uses OAI-PMH to extract RDF-encoded metadata from DSpace repositories, and provides new and powerful ways to explore the contents of the repository while still integrating the new features into the standard DSpace user interface via easy-to-use Javascript widgets.DWell will be released to the DSpace community in the near future, and clearly demonstrates how RDF and Semantic Web technology can add value to digital library systems with minimal effort. The DWell UI will be demonstrated, as well as other applications of the Longwell browser. http://simile.mit.edu .
Session 2: Web Archiving Update. (Ballroom Foyer, Main Lobby Level)
Kristine Hanna, Internet Archive [PRESENTATION]; Tracy Seneca, California Digital Library [PRESENTATION]; John Tuck, British Library [PRESENTATION]; Taylor Surface, OCLC Online Computer Library Center; and Jennifer Marill, Library of Congress [PRESENTATION].
Web archiving services under development and deployment at a number of different institutions will enable librarians and other document selectors to extend their historic collection-building roles into the domain of web-based materials. Such services allow curators to initiate and monitor web crawls relevant to specific topic areas, analyze and annotate harvested data, and search and browse local archives built from sites that may have been harvested multiple times. A great deal has been learned in the past year about the Do's and Don't's of web archiving, and the panelists will be presenting on their latest experiences.
3:00 p.m. – 3:30 p.m. Break (Rostrum, Main Lobby Level)
3:30 p.m. – 5:00 p.m.
Session 3: Architectures and Collaboration. (Grand Ballroom, Main Lobby Level)
"PennTags: Social Bookmarking in an Academic Environment." Michael Winkler, University of Pennsylvania. PRESENTATION
PennTags is a social bookmarking system that has been developed at the University of Pennsylvania for use in an academic environment. PennTags allows owners to capture links to content on the open web, much like del.icio.us and other social bookmarking tools. But, PennTags can also capture content links from the Library catalog, DOI & OpenURL sources and other proprietary research-support systems that can be elusive to non-academic bookmarking systems. After capture, PennTags allows owners to enhance their bookmarks with tags and annotations that support user-driven classification, contextualization and critical analysis of these resources. Owners can organize posts into projects - logical, synthetic groupings that enhance meaning and utility of the publication. Recent changes to PennTags enable multiple project participants that can add, edit and shape its intellectual content. Over the past year as PennTags has matured, we've observed several ways in which a tool like PennTags can be a powerful tool in an academic setting to organize resources, create content and support communities of learners and researchers. Librarians are using it to quickly produce on-the-fly research guides that can continue to grow and self-organize. Increasingly, the Library is using PennTags as a content management system for its web presence. But more exciting is that communities of users - librarians, researchers, students - have used PennTags to create shared knowledge-bases that range from class projects in film studies, to bibliographies on copyright, to resources collected by students in Veterinary Medicine, to reference tools discovered by and for medical interns. In each case, the community used PennTags to produce this corpus of resource links, metadata and synthetic organization in a harvestable, public venue. As the use of PennTags continues to grow, PennTags faces opportunities and challenges to support diverse and specialized needs to organize and present content, to support classroom use of digital objects and resources, and to integrate with the tools that researchers, faculty, students and librarians routinely use in their work. In this presentation, we discuss how PennTags has developed and what plans we have for further development.
"Cooperative Architecture and Cooperative Development of a Course Reserves Tool." Randy Stern and David McElroy, Harvard University. PRESENTATION
Harvard University Library and the Harvard University iCommons project have jointly developed a web based system to automate faculty creation, library processing, and student display of course reserves reading lists. In its first year of operation, the system processed over 14,000 reserves requests for more than 900 courses in the Faculty of Arts and Sciences and this year has been extended to support 5 Harvard graduate schools. Independent library, registrar, and courseware teams worked together over a 2 year period to cooperatively design, develop, pilot, and productize a unique set of SOAP services for communication of course and library data, and service requests from web based tools running in disparate environments. Citation lists can incorporate reading lists from previous years, on-line submission, as well as legacy submissions in paper or email format. The presentation will describe the technical architecture of the solution, the management challenges of development and support in a distributed organization, and present some screen shots of the system.
"OpenURL Unleashed: Six Questions (Q6) and the OpenURL Object Model (OOM)." Jeffery A. Young, OCLC Online Computer Library Center. PRESENTATION
Forget what you think you know about OpenURL. Think of it this way instead: OpenURL is the little bit of glue that allows programmers to drop their raw business logic on a server's classpath and have it appear as a web service. This glue amounts to six questions that a three year old could understand: who, what, where, why, when, and how. Since any imaginable web service request can be expressed in these terms, this simpler understanding breaks down the barriers that have prevented OpenURL from realizing its full potential. Furthermore, the OpenURL Object Model (OOM) is offered as a language- and platform-independent view of an OpenURL application that allows developers to focus on two simple interfaces for transforming their business logic into web services.
Session 4: Archives and Rights. (Ballroom Foyer, Main Lobby Level)
"Archiving Katrina Web Content for Enduring Access & Research: Lessons Learned from the Deployment of Open Source Tools & Resources for the Historic Preservation of Current Events." Gordon Mohr and Kris Carpenter, Internet Archive. PRESENTATION
On September 4, 2005, the Internet Archive began to collect, archive and make publicly accessible Web content covering Hurricane Katrina's historic landfall in the Gulf of Mexico and its immediate aftermath. The Internet Archive, the Library of Congress, a select group of universities, and many individual contributors worked together to compile a comprehensive list of websites to create this historical record of the devastation and the massive relief effort that followed. The goal was to collect content as it was generated or updated and to preserve each page for immediate viewing and for future research. The project was executed using a full suite of open source web archiving tools and end user applications including the: Heritrix web crawler; Hadoop scheduler; Nutch search; and Nutch wax & Wayback machine archive file viewers.
The Katrina collection spans content generated between September 4 and November 8, 2005 and has over 61 million unique pages, all text searchable, from over 1700 Sites. The collection is hosted at http://websearch.archive.org/katrina/. This talk describes the Katrina archives, the open source tools and applications used to create and support the collection, the lessons learned, and how these open source tools and applications have evolved as the result of this community-based collaboration.
"SCETI @ Ten." David McKnight, University of Pennsylvania.
The Schoenberg Center for Electronic Text and Image (SCETI) celebrates its tenth anniversary in 2006. A jewel in the crown of the University of Pennsylvania Library system, SCETI was at the forefront of the production and networked distribution of high quality digital facsimiles drawn from the University of Pennsylvania's rich and varied rare book collections. Touted as an integrated digital library, over the course of the past ten years SCETI has evolved and changed, like other comparable programs to the point where "integrated" by necessity must be redefined. While continuing to add significant content to the Web, the program faces a number of challenges many of which are driven by internal and external forces. The purpose of my presentation is four-fold 1) review, briefly, the history of SCETI from its inception in 1996 and the programs achievements; 2) examine the problems and issues related to the migration from a hybrid relational database system to an open source modular and tiered system architecture based upon XML; 3) analyze the impact the implementation and adoption of a new production model will have on SCETI's management, production and workflow; 4) explore the benefits that an XML production model will have upon the development of the expanding UPenn digital library and envisage the quality and nature of the user's experience while accessing and interacting with the Library's rare and special collections during the next ten years of operation.
"Faculty Rights and Other Scholarly Communication Practices." Denise Troll Covey, Carnegie Mellon University.
Please contact email Denise Troll Covey at troll@andrew.cmu.edu for more information regarding this presentation.
6.00 p.m. onwards POSTERS (part of the reception at the Boston Public Library)
1) Testing METS Based Digital Object Viewers for the Calisphere Web Site. Brian Tingle, California Digital Library.
In August 2006 the University of California announced the launch of the Calisphere Web site. This free Web site -- http://www.calisphere.universityofcalifornia.edu -- offers educators, students and the public access to more than 150,000 images, documents and other primary source materials from the libraries and museums of the UC campuses and cultural heritage organizations across California. These digital objects are represented by METS documents inside of an access repository. The poster will explain the METS Profile aware systems that are used by Calisphere and describe the methodology that was used to test these systems during the development of the Calisphere Web site. A "profile driver" is used by the system to manage the information needed view and extract metadata from the METS documents. A test page selects up to 20 random samples of documents matching each profile and allows the tester to examine how the METS are working or failing to work in the system.
2) Using Wikipedia to Extend Digital Collections. Ann Lally and Carolyn Dunford, University of Washington.
In the summer of 2006 the University of Washington Libraries Digital Initiatives unit analyzed the content of its Digital Collections for subjects relevant to articles in Wikipedia; and edited the Wikipedia articles to include links to our collections. Since that time the use of our collections has increased tremendously. This presentation will talk about the history of the project, the culture of Wikipedia as applied to this project and the results of our analysis of our web server statistics.
3) GOOBI:
A Workflow Management Software for Digitization Processes. Markus Enders, SUB Göttingen.
GOOBI is a workflow management system developed at SUB Göttingen, to manage and organize complex production workflows by integrating specific modules into a workflow engine which steering the production process. The production of Images and METS-metadata had become less error-prone and more efficient.
Business processes in digitization projects: The key to success of a digitization project is the production process. The efficiency of the digitization process depends on the management and its decisions:
- How to arrange duties? How do people know, what they should next?
- How to name processes? Folder? files?
- How to document the project's status?
- How to react in unconsidered situations - new workflows in the business process are needed
The bigger the projects gets, the more locations are involved, the higher the division of labor is, the more important the software support for project management gets. To manage and organize complex time- and place independent production processes in larger scale, GOOBI - a workflow management software for digitization projects was developed at the SUB Göttingen. The software supports the project manager with detailed statistics about the ongoing production, arranges duties to the project members and provides modules to carry out certain tasks. For platform independence it provides a web-based user interface. GOOBI consists of a highly configurable workflow engine with integrated data management. The data management manages the storage of images and metadata files while the workflow engine provides access to the data according to the process status and access privileges by copying the data to the user's home directory and document the process status. Using file system based access mechanism allows the integration of common tools as Photoshop, ACDSee etc. into the workflow. Beyond file system access, individual modules provide functionality for certain tasks: Access the OPAC to retrieve metadata, export metadata in METS/MODS format to the document management system, capture metadata and structure of work (based on a ruleset) using the web interface. Originally GOOBI was developed for a cooperative project between German and Russian partners. Because of the flexibility of its workflow engine, it was easy to adapt the system for the common GDZ digitization workflow. Based on the good experiences (less errors, higher quality of data) and more efficient workflow, the GDZ is offering the system as a service to other libraries as well. For the future the release under an open source license is planned.
4) The Olympic Community Museum: A Community-based Digital Project. Anne Graham, University of Washington.
For the past three years, the University of Washington Libraries, in partnership with a variety of community organizations and individuals on Washington's Olympic Peninsula have been digitizing materials intended to showcase aspects of the rich history and culture of the region. The Olympic Community Museum project is made possible by a National Leadership Grant for Library and Museum Collaboration from the IMLS (IMLS). This work resulted in an online "virtual museum," available to all web users, and served through CONTENTdm. Materials are organized as a series of exhibits, each representing a different aspect of the culture and history of the region. Community Museum online exhibits include: Makah and Quileute tribal cultures; timber history; the lives of early pioneers; and the growing local Hispanic population's culture. Curriculum materials were also created for use by teachers of grades 9 and beyond. A community-based approach was used to collect images and curate them. This poster will present the successes and problems which were overcome in the process of identifying, digitizing, and organizing over 12,000 items, and the lessons learned, which may in turn be useful to others involved in community-based digital projects. Lessons regarding permission procurement, especially permissions from the three tribal entities involved, will be presented. Other concerns to such a project, such as publicity, management approaches, training, and curating will also be described.
5) From Project to Program: A Checklist for Sustainability. Barrie Howard, Digital Library Federation.
Many digital library projects are funded on private and public funding in two-year timeframes, with little attention paid to how to sustain successful projects past the grant period. There is sparse literature about business planning for sustainability to help prepare these projects for integration into their host institutions' organizational and operational structure, and articulate their value to decision makers. This poster session will discuss the importance of business planning for digital libraries, and present a checklist of criteria for project directors and managers to consider when faced with a decision of whether or not to approach upper administrators with a case for sustaining a project. The checklist builds on frameworks discussed by Nancy Allen and Liz Bishoff in Business Planning for Cultural Heritage Institutions (2004), and Marilyn Struthers in Supporting Financial Vibrancy in the Quest for Sustainability in the Not-for-Profit Sector (2004).
DAY TWO: Thursday, November 9
8:00a.m. – 9:00a.m. Breakfast (State Suites A & B, Lower Lobby Level)
9:00a.m. – 10:30a.m.
KEYNOTE: Anurag Acharya, Principal Engineer, Google, and founder of Google Scholar (Grand Ballroom, Main Lobby Level)
10:30a.m. – 11:00a.m. Break (Rostrum, Main Lobby Level)
11:00a.m. – 12:30 p.m.
Session 5: Developers' Forum Panel: Networked Storage. (Grand Ballroom, Main Lobby Level)
John Kunze (Chair), California Digital Library; Keith Johnson, Stanford University; Shigeo Sugimoto, University of Tsukuba [PRESENTATION]; Clay Shirky, New York University [PRESENTATION]; and Mema Roussopoulos, Harvard University [PRESENTATION].
The Developers' Forum is intended for senior technology developers, technical managers, or those representatives that have influence in decision-making at their institutions. The Developers' Forum provides dedicated time at the DLF Forum to meet together to share problems, ideas, and solutions of a technical nature. This meeting will be structured as follows:
- Intro and Review
- Feasibility of a DLF tools registry as a community resource?
(populating, maintaining, subsidizing)
- Roundtable micro-presentations of 2-5 minutes from each attendee.
- From the safety of their chair, each person delivers a brief,
- informal statement giving consideration to each of the topics: cool new technology of interest; over-hyped technology; technical problems calling for group discussion; opportunities for collaboration
- There will be time for discussion after each micro-presentation.
- Selection of topic and temporary co-chair for a session and
birds-of-feather (BOF) meeting at the next main DLF Forum.
The temporary co-chair helps organize, moderate, and facilitate
that session and BOF.
Session 6: Partnerships with Scholars. (Ballroom Foyer, Main Lobby Level)
"The Voyages Project: A Sustainable Model for Partnership between Scholars and Digital Librarians." Liz Milewicz, Emory University. PRESENTATION
The Voyages project (http://www.metascholar.org/TASTD-Voyages) is an NEH-funded and scholar-digital librarian collaborative effort based at Emory University, which will create an expanded, online version of the Trans-Atlantic Slave Trade Database (Eltis, Behrendt, Richardson, & Klein, 1999) - a numerical humanities database currently in CD-ROM format, created by historians and used by scholars in multiple disciplines. This presentation will highlight two key issues that emerged in the early stages of this project and will remain critical through the life of the database: 1) connections between scholarly practices and data structures, and the implications for both when creating a sustainable digital resource; and 2) collaborative practices that encourage engagement from project partners while acknowledging their distinct contributions. The Trans-Atlantic Slave Trade Database represents decades of accumulated scholarly research on one of the largest forced migrations in world history, and currently incorporates data on over 27,000 separate voyages. It bears the marks of its digital evolution, from variable codes constructed in DOS files to date ranges formulated in SPSS tables. Challenges facing this project are numerous and varied, from contextualizing the data for a broader audience to making the database a sustainable and expandable resource. In particular, migrating this static resource into an online, publicly and freely accessible, and sustainable database impacts not simply the structure of data storage but established scholarly practice as well. Two of the great strengths of this project - its initiation by scholars and their committed engagement with its development, and the collaboration between scholars and digital librarians - help ensure the scholarly integrity and long-term viability of this unique resource.
"Collaborating with International Faculty to Develop Video Resources: A Case Study." Danielle Mericle and Melissa Kuo, Cornell University.
Audio and video resources pose new challenges and fresh opportunities for digital library development. At the most basic level, faculty members request these assets be made available for research and teaching; however, the great potential of new online technologies begs the question of what else can be done? Cornell University Library, in collaboration with faculty members from the Cornell University German Department and the University of Bremen in Germany, are completing development of an ambitious project to deliver 22 films by German filmmaker Alexander Kluge on the preeminent German playwright Heiner Mueller. What started as a relatively simple goal to make the material available quickly evolved into an extensive research project to give further context to the films. Using Flash technology, the films now have annotations, citations, and subtitles (in German and English). Extensive research & development on a wide array of software was done to produce the site, and a host of graduate students at both Cornell and Bremen worked with faculty to transcribe, translate, and caption the films. Cornell University Library had only three staff members assigned to the project (all with multiple projects). During this presentation, we will discuss the challenges of working with new technology on a limited budget; the intricacies of coordinating a large, international group of contributors; and the rich rewards of faculty/library collaborations.
"Partnering with Scholars: Exposing a City's Hidden Collections." Charles Blair and Elisabeth Long, University of Chicago. PRESENTATION
The University of Chicago Library is partnering with university faculty to create an innovative program for exposing primary archival sources in the Chicago area. The program includes both a technical component, the construction of an extensible, customizable infrastructure to enable searching either across institutions and collections or within individual collections, as well as a collaborative component in which the Library works with faculty to train graduate students in primary source research and archival processing techniques. This initiative will provide a model for actively engaging scholars in guiding archival processing decisions, exposing collections in a geographical region or subject area, and creating a technical infrastructure that can address the requirements of diverse institutions while enabling a cooperative endeavor. The presentation will discuss the strategic thinking that underlies this initiative, the process of collaborating with faculty and other institutions to effect such an ambitious project, and the development of a technical infrastructure using a current EAD-based implementation.
12:30 p.m. – 2:30 p.m. Break for Lunch [Individual choice]
2:30 p.m. – 4:00 p.m.
Session 7: Collections and Access. (Grand Ballroom, Main Lobby Level)
"Virtual Collections: Challenges in Harvesting and Transforming Metadata from Harvard Catalogs for Topical Collections." Randy Stern and Michael Vandermillen, Harvard University. PRESENTATION
The Virtual Collections system is a new centrally-supported system for Harvard librarians, archivists and curators to create new, topic-based collections from metadata existing in Harvard catalogs. A subset of OAI-PMH is utilized to request records from Harvard's OPAC (HOLLIS), visual materials catalog (VIA) and geospatial library (HGL). Using XSL, these records are transformed from their native XML form (MARC, VIA, FGDC) into a common metadata format, MODS, and loaded into a native XML database. A Web-based user interface provides browsing and searching confined to topically-defined collection rather than as part of a larger, general catalog. The Virtual Collection system uses XML transformed by XSL to deliver HTML, which allows collection curators flexibility in how content is presented. The collection can exist in a simple "out of the box" form using default XSL (and CSS stylesheets), or the collection content can be pulled into a more complex site and customized by editing stylesheet templates. This presentation will highlight some of the challenges in harvesting and transforming metadata and the use of a native XML database for storage. We will also discuss the use of XML and XSL to deliver customizable content.
"Is the World Flat? Sharing Hierarchical Image Metadata with Flat Database Partners."
Robin Wendler,
Michael Vandermillen, and
Gary McGath, Harvard University;
Emerson Morgan, ARTstor. PRESENTATION
Harvard's VIA catalog of visual images has been in place for nearly
eight years. From the beginning, VIA metadata records were designed to support hierarchical description, with a three-tier model of groups of works, individual works, and multiple surrogates. Harvard recently undertook a project with ARTstor to provide an alternate method of access to records for two Harvard libraries: the Harvard Fine Arts Library and the Loeb Library of the Graduate School of Design. Harvard makes the VIA records available for harvesting in MODS format. ARTstor, like the overwhelming majority of image databases, uses an essentially flat record structure where one record equates to one image. In disaggregating Harvard's compound records into single-image records, ARTstor and Harvard staff wrestled with:
- mapping descriptive fields for separate conceptual levels into a single tier of elements, retaining vocabulary for retrieval but losing, in some cases, a level of meaning and specificity
- identifying methods for maintaining ARTstor's separate records accurately as a single hierarchical parent record changes over time.
Emerging descriptive metadata standards for visual resources, namely Cataloging Cultural Objects and VRA Core Categories 4.0, are designed to support a hierarchical approach to image description. Harvard and ARTstor's experience moving hierarchical records into a flat record environment may be helpful as other institutions begin to develop systems that take advantage of the new standards. Different approaches will be appropriate in different contexts., but however an institution structures its records will have implications for metadata sharing and aggregation.
"Contextualizing Access to Subject Headings across Digital Collections: The "See Also" Problem." Joe Dalton, New York Public Library. PRESENTATION
NYPL Digital Gallery, which launched with 275,000 items in 2005, has grown to more than 500,000 searchable images. With this increasing scale it has been a challenge to provide effective ways to browse digital content. To answer the question "what have you got?" one option has been the "Subjects A-Z" index; however, since there are over 58,000 headings listed, it is not a particularly effective discovery tool. The New York Public Library's Digital Library Program has recently developed a new approach to subject browsing for the Digital Gallery, creating an index of all subjects and mapping their object-level relationships to related subjects.
This approach has broadened some of our previously-held ideas about "related subjects." A search using this index can open up avenues for exploration which are not always available with simple term searches across subject headings, faceted browsing, or semantically-derived ("see also") models. A subject search for "animals" using this framework returns, in addition to subject headings containing the exact term like "Aquatic animals," links for "Bears" and broader headings such as "Allegories" or "Dance." Results can be linked, for example, to all images whose subjects contain both "Animals" and "Allegories" and can provide serendipitous, related avenues for further exploration. This presentation discusses some challenges and opportunities in using this approach.
"SUSHI as a Model for Library/Vendor Collaboration." Adam Chandler, Cornell University [PRESENTATION], and Tim Jewell, University of Washington [PRESENTATION].
SUSHI (the Standardized Usage Statistics Harvesting Initiative) is one of 3 areas of focus for "ERMI 2" -- the second phase of the DLF-supported Electronic Resource Management Initiative. Its goal is to help automate the otherwise labor-intensive process of gathering vendor-based usage statistics by developing a light-weight SOAP/Web service protocol that can be adopted by data suppliers and consumers -- including libraries, ILS vendors and other service providers. Focusing first on COUNTER "JR1" reports, the effort has moved ahead very quickly -- with development tools for both the .NET and Java environments made available last spring and successful tests within the same time-frame, some organizations moving SUSHI-based services into production this summer, and a "Draft Standard for Trial Use" scheduled for release under NISO auspices in late September 2006. This presentation will provide background on libraries' needs for and use of vendor-supplied data, a detailed description of the SUSHI protocol and technology, "lessons learned" from the development process that may be of value to future collaborative projects, and discussion about the possible utility of SUSHI as a vehicle for gathering digital collection usage statistics offered by DLF member libraries.
Session 8: Preservation. (Ballroom Foyer, Main Lobby Level)
"Co-operating Preservation Archives: Sharing OAIS Collections Among Dissimilar OAIS Repositories." Bill Kehoe and Adam Smith, Cornell University. PRESENTATION
The MathArc project has created a protocol and software that enable multiple institutions to share and store digital objects in each other's OAIS repositories, regardless of the nature of each system's underlying repository. In the pilot version, the Göttingen State and University Library and the Cornell University Library are sharing, storing, and managing collections preserved in Göttingen's KOPAL system (based on DIAS) and Cornell's CUL-OAIS (based on aDORe). The digital objects include component TIFF, PDF, Postscript, XML, and LaTex files. The authors present a high-level view of the protocol, the software, and the inter-institutional co-operation that makes this system work.
"Global Digital Format Registry (GDFR): An Interim Status Report." Stephen Abrams, Harvard University, and Andreas Stanescu, OCLC Online Computer Library Center. PRESENTATION
The concept of "format" encapsulates the syntactic and semantic rules used
to encode abstract content into a digital bit stream. Without knowledge
of these rules, the information content of formatted digital assets cannot
be recovered, interpreted, or rendered. The Andrew W. Mellon Foundation
has funded the Global Digital Format Registry (GDFR) project at the
Harvard University Library (HUL) to provide sustainable services to
capture, manage, preserve, and distribute important representation
information about digital formats. This information will be used by
international preservation practitioners and memory institutions as part
of their ongoing digital curation and stewardship activities. HUL and
OCLC have recently reached an agreement to collaborate on the development
and deployment of the GDFR. This presentation will provide background
information on the project, review its progress to date, and preview its
future activities. This summary will cover functional requirements and
technical specifications, including the GDFR's proposed distributed
peer-to-peer architecture, data and service models, network protocols, and
submission policies. A forum for an extended discussion of these topics
will be provided by the companion Birds-of-a-Feather session.
"Life Cycle Management Meets Digital Preservation: Role of Collection Maintenance in Digital Collections Sustainability." Oya Y. Rieger, Cornell University. PRESENTATION
This presentation illustrates the day-to-day digital collection sustainability challenges for heterogeneous digital content. As our investment in digital content creation grows, digital preservation has become a widespread and highly publicized concern with several supporting initiatives and programs in place. The maintenance of digital collections for access provision is a somewhat neglected stage of life cycle management. This matter is especially important due to the escalating digital content discovery requirements of end users and the rapidly evolving digital content delivery systems. The goal of this presentation is to describe Cornell University Library's digital collections maintenance program and to outline the process of identifying operating principles to promote strategies for sustainability. The presentation will include a description of the stewardship concept, financial analysis of maintenance costs, and examples of collection repurposing processes (such as print-on-demand services). The Library's implementation of the Ockham registry for the dual purposes of digital asset and web services management will also be described.
4:00 p.m. – 4:15 p.m. Break (Rostrum, Main Lobby Level)
4:15 p.m. – 5:15 p.m. BIRDS OF A FEATHER 1
1) PREMIS with METS. Rebecca S. Guenther, Library of Congress. (Ballroom Foyer, Main Lobby Level)
The PREMIS Working Group released the Data Dictionary for Preservation Metadata (PREMIS) and its supporting 5 XML schema in May 2005, which defines and describes an implementable set of core preservation metadata with broad applicability to digital preservation repositories. A Maintenance Activity was established in early 2006 to oversee future development and maintenance and coordinate implementation. A number of institutions have begun planning for implementations of preservation metadata in their digital repositories using PREMIS. Because of the flexibility of the PREMIS and METS schemas, there is a need for the PREMIS and METS communities to develop best practices for using PREMIS within METS documents. This BOF will explore some of the approaches that implementers are taking in regard to using PREMIS with METS. These include a number of issues that are detailed below; it is suggested that attendees consider these issues in terms of the way their institutions are approaching them. The broader question of the types of events that institutions want to track and how event outcomes should be recorded will also be considered. It is hoped that the results of this session will lead to proposals for best practices.
Using PREMIS and METS together: issues
- Which METS sections are you using for which PREMIS entities?
- Are you repeating the main METS sections (e.g. amdSec, digiProv) and what guides the repetition?
- Should elements that are in both PREMIS and METS be recorded redundantly or only in one or the other (e.g. size, checksum)?
- How do you record elements that are in PREMIS as well as a format specific metadata schema (e.g. MIX)? Redundantly or in one or the other?
- How do you record structural relationships? The METS structMap covers this to some extent, but there are also PREMIS relationship elements that do the same.
- How do you deal with controlled vocabularies? PREMIS suggests using them in many places, but they are not enumerated in the schema and thus cannot be controlled/validated. What further work needs to be done?
- Are you using the PREMIS container schema or the other 4 schema separately without the PREMIS wrapper (i.e. object, event, rights, agent)?
Event issues
- What types of events are you tracking?
- How are you controlling event type values?
- What are you recording in eventOutcome and/or eventOutcomeDetail?
2) A Framework for the DLF Aquifer Distributed Digital Library. James Bullen, New York University. (Back Bay Room, Lower Lobby Level)
Aquifer Technology/Architecture Working Group: James Bullen (chair), New York University; Eric Celeste, University of Minnesota; Tim Cole, University of Illinois at Urbana-Champaign; Jody DeRidder, University of Tennessee; Jon Dunn, Indiana University; Todd Grappone, University of Southern California; Jerry Persons, Stanford University; Cory Snavely, University of Michigan; Thorny Staples, University of Virginia; Associate members - Rob Chavez, Tufts University; Bill Parod, Northwestern University.
The Technology/Architecture Working Group of the DLF Aquifer Initiative has been building on the asset actions experiments reported on at the DLF Spring forum. The focus has been on extending the model to more formats, such as text, introducing parameters to the model and developing procedures and protocols for creating and exchanging asset action data. The working group has also been developing a framework for the implementation of the Aquifer distributed digital library that brings asset actions together with the other strands of Aquifer and looks ahead to future Aquifer activities.
This Birds of a Feather session will be an opportunity to discuss the proposed Aquifer framework and asset actions and for the working group to get feedback on the direction this work is taking.
For a detailed look at the asset action experiments please see this article in the October issue of D-Lib Magazine: http://dlib.org/dlib/october06/cole/10cole.html .
And please find a draft of the framework for implementation at:
http://www.diglib.org/aquifer/aquifer_framework_v7.pdf
http://www.diglib.org/aquifer/aquifer_framework-figure_1_v9.pdf
http://www.diglib.org/aquifer/aquifer_framework-figure_2_v7.pdf
3) JHOVE2: A Next-Generation Architecture for Format-Aware Preservation Processing. Stephen Abrams, Harvard University; Evan Owens, Portico; and Tom Cramer, Stanford University. (State Suite B, Lower Lobby Level)
The open source JHOVE format identification, validation, and characterization tool has proven to be a successful component of many repository and preservation work flows. However, in the course of its widespread use a number of limitations imposed by its current design and implementation have been identified. To remedy this, Harvard University, Portico, and Stanford University are planning a collaborative project to develop a next-generation JHOVE2 architecture. Among the enhancements of
JHOVE2 are a more sophisticated data model that can support digital objects manifest in more than one file, a more generic plug-in mechanism to permit
JHOVE2 to be used for arbitrary stateful preservation work flows, and additional module support for audio, container, document, GIS, and web harvesting formats. This session will summarize the goals of the JHOVE2 project and provide an overview of its proposed functional requirements and technical specifications. The project partners are actively soliciting the advice of the JHOVE user community so that the new tool will better meet the needs of repository and preservation practitioners. The project proposal available at http://hul.harvard.edu/jhove/JHOVE2-proposal.doc, will be used as the basis for the BOF discussion.
4) Developers' Forum BOF: Networked Storage.
John Kunze, California Digital Library, Keith Johnson, Stanford University, and Shigeo Sugimoto, University of Tsukuba. (State Suite A, Lower Lobby Level)
This Birds-of-a-Feather session is intended to provide a place for
people to explore issues and questions raised during the Networked
Storage Panel that took place earlier in the day.
The amount of online storage required by digital libraries is growing at
a rate that is straining traditional IT disk and tape configurations.
Systems that make it possible to leverage the potentially vast
collective storage resources of groups of providers would supply welcome
relief to the pressure of accommodating the surge of information that
our institutions are called upon to save, to replicate, and to make
available in a variety of forms. At the same time, myriad policy,
service, business, and technical choices introduce challenges that may
take some time to understand. This session will surface a range of
approaches to networked storage.
5)Provision of Electronic Resources to Library Users in Transitional and Developing Countries. Denise Troll Covey, Carnegie Mellon University. (Forum Room, Lower Lobby Level)
Some Carnegie Mellon faculty participating in the University Libraries' study of their rights and scholarly communication practices mentioned heavy use of their out-of-print textbooks that they had made available open access on the web. Others mentioned their intention to make their out-of-print books available open access, but explained that their intention was being thwarted by a non-responsive or reluctant publisher who would not return copyright to them despite the terms of their copyright transfer agreement. The Scholarly Publishing and Academic Resources Coalition (SPARC) recently announced an alliance with Electronic Information for Libraries (eIFL), an independent foundation founded and partially funded by the Open Society Institute (OSI). eIFL works to provide electronic resources for library users in transitional and developing countries. OSI launched the open access movement for journals in 2002 and now wants to expand the movement to include "textbooks" broadly defined. OSI has expressed interest in funding an initiative that would provide eIFL members with online access to textbooks and other learning materials. Initiatives of interest include:
- Identifying and collecting existing textbooks and learning materials that are already available open access
- Working with SPARC to develop tools that help authors: Re-acquire copyright for their textbooks and other learning materials that are out of print;Negotiate copyright transfer agreements for textbooks and other materials that will facilitate re-acquiring copyright at some later date
- Creating a central organization that authors could contact to negotiate for them to: Re-acquire copyright for existing textbooks and other learning materials; Ensure for new books and materials that copyright reverts to them at some specified date or under specified conditions
Heather Joseph, the Executive Director of SPARC, Melissa Hagemann, Program Manager for OSI, and Carnegie Mellon University Libraries would appreciate an exploratory discussion with interested DLF institutions to brainstorm options, barriers, and strategies and to identify potential partners to work on providing open access to textbooks and other learning materials.
5:15 p.m. – 5:25 p.m. Break
5:25 p.m. – 6:25 p.m. BIRDS OF A FEATHER 2
6) DLF Implementation Guidelines for Shareable MODS. DLF Aquifer Metadata Working Group Chaired by Sarah Shreeves, University of Illinois at Urbana-Champaign. (Back Bay Room, Lower Lobby Level)
Aquifer Metadata Working Group: Sarah Shreeves (chair), University of Illinois at Urbana-Champaign; Laura Akerman, Emory University; John Chapman, University of Minnesota; Melanie Feltner-Reichert, University of Tennessee; David Reynolds, Johns Hopkins University; Jenn Riley, Indiana University; and Gary Shawver, New York University.
The Aquifer Metadata Working Group (MWG) will be releasing the final version of the DLF Implementation Guidelines for Shareable MODS by mid-September and will be focused on moving forward to other work including assessing levels of compliance with the Implementation Guidelines. This session will be an opportunity for those interested in the Guidelines and the work of the MWG to discuss the final version of the Guidelines, what levels of compliance with the guidelines might be, and what other work would be useful in the context of DLF's Aquifer Initiative.
7)Global Identifier Resolution. John Kunze, California Digital Library and
Tim DiLauro, The Johns Hopkins University. (State Suite B, Lower Lobby Level)
This Birds-of-a-Feather session is intended as a follow on to the
Developers' Forum Panel and BOF of the same name that took place at the
Spring 2006 Forum in Austin. Brief reports on recent developments are
welcome. Reports scheduled so far include Markus Enders on a working
distributed-query resolver and John Kunze on the Name-to-Thing (N2T)
resolver proposal.
8)Global Digital Format Registry (GDFR): A Review of Functional Requirements and Technical Specifications. Stephen Abrams, Harvard University; Andreas Stanescu, OCLC Online Computer Library Center. (State Suite A, Lower Lobby Level)
The Global Digital Format Registry (GDFR) project currently underway as a collaborative project of the Harvard University Library (HUL) and OCLC is developing a system to provide sustainable services to capture, manage, preserve, and distribute important representation information about digital formats. The initial phase of the project is dedicated to design activities including the identification of stakeholder communities, surveying their requirements, and developing functional requirements, technical specifications, and an implementation plan. This BOF session will provide a forum for an extended discussion of topics introduced during the summary paper presentation on GDFR. The discussion is expected to cover GDFR use cases, distributed peer-to-peer architecture, data and service models, network protocols, submission policies, and the ways in which GDFR can and should be integrated into existing and planned digital library and preservation workflows. This community feedback is important in determining whether the current project proposals in these areas meet the anticipated needs of the GDFR stakeholder communities. The current GDFR design documents are temporarily available at http://hul.harvard.edu/gdfr/documents.html. These documents, as well as information presented in the formal paper presentation, will be used as the basis for the BOF discussion.
9)OCLC Programs and Research: A Discussion of Work Agenda with Inclusion of RLG. Constance Malpas, OCLC Online Computer Library Center. (Forum Room, Lower Lobby Level)
On July 1, 2006, RLG and OCLC, two of the world's largest membership-based library organizations, combined. The combination has two important aspects; the first is the integration of RLG and OCLC services, including core bibliographic utilities representing the holdings of thousands of libraries and cultural heritage institutions worldwide. The second, more transformative aspect is the incorporation of RLG Programs and the OCLC Research into a new Programs and Research unit. The combined assets of this new unit, which brings together leading research scientists and a team of specialist program officers, create new capacities for community-building, applied research, and the development of new prototypes that will better enable research institutions respond to the challenges of a rapidly changing information services environment. More than a hundred Partner institutions representing libraries, museums and archives worldwide actively support and participate in the work of this new unit and contribute to shaping its agenda. Attend this session to learn about the emerging work agenda of this new partnership and how you can be involved in shaping its future. The discussion will be facilitated by staff from OCLC Programs and Research.
DAY THREE: Friday, November 10
8:00a.m. – 9:00a.m. Breakfast (State Suites A & B, Lower Lobby Level)
9:00a.m. – 10:30a.m.
Session 9: DLF/IMLS OAI Project Update. (Grand Ballroom, Main Lobby Level)
David Seaman, Digital Library Federation; Katherine Kott, DLF Aquifer; Kat Hagedorn, University of Michigan; Tom Habing, University of Illinois at Urbana-Champaign; and Liz Milewicz, Emory University. PRESENTATION
The DLF/IMLS grant is in its final stages, after a highly successful two years. This grant was designed to test 2nd generation OAI tools, services and training opportunities. The results of this research include:
- Creation of best practices for shareable metadata, OAI data provider implementations, and tools and strategies for using and enhancing/extending the OAI protocol.
- The second generation of the Martha Brogan report on OAI service and data providers.
- Comprehensive training documents used in several training sessions for potential OAI data providers.
- Two enhanced registries for data providers and service providers.
- Two searchable portals that collect all DLF OAI data providers and all DLF OAI data providers that are using the MODS metadata format.
- An effort at clustering metadata topically for inclusion into the DLF OAI data provider searchable portal.
The grant participants will speak briefly on each of these research areas. Katherine Kott will provide a general DLF Aquifer update and focus on the methods DLF Aquifer is developing for integrating aggregated collections into a variety of local environments. The scenarios are:
- Through a commercial search service
- Through a course management system (e.g. Sakai(tm))
- Through tools designed for citation management (e.g. RefWorks or EndNote(r))
- Through a federated search tool in a library environment (e.g. SFX(r))
Technical details on architectural models under consideration and current asset action development will be discussed at a BOF held by the DLF Aquifer Technology/Architecture Working Group. The Metadata Working Group will also hold a BOF to discuss levels of compliance with The DLF Implementation Guidelines for Shareable MODS in a service context.
Session 10: Mass Digitization and the Collective Collection. AND Mass Digitization: Building a digital Library of Alexandria or a White Elephant? (Ballroom Foyer,
Main Lobby Level)
"Mass Digitization and the Collective Collection." Constance Malpas, OCLC Online Computer Library Center; Robin Chandler, California Digital Library; Barbara Taranto, New York Public Library; Carole Moore, University of Toronto. PRESENTATION
The purpose of this session is to stimulate meaningful reflection on the current status of the mass digitization enterprise and thoughtful discussion of where we (as a community) want it to head in the future. A moderated Q and A session format will enable us to surface community concerns about how mass digitization is transforming the library service environment and identify shared interest in specific collaborative solutions.
Panelists have been selected from institutions that are actively participating in large-scale digitization efforts (including Google Book Search, the Open Content Alliance and AlouetteCanada projects) whose collective experience can help to inform decision-making at other institutions. A core set of questions designed to prompt reflection and debate will be formulated by members of a recently formed working group that is exploring the opportunities and challenges associated with the build-out of a "collective" digital library collection. These questions will be circulated to panelists in advance of the Forum. Audience members will be encouraged to pose, and respond to, additional questions during the course of the discussion. The panel will be moderated by a staff member from the recently integrated Programs & Research division of OCLC.
Questions to be addressed:
- Has the (increasing) availability of a system-wide digital collection enabled your institution to implement meaningful change in local acquisitions and/or weeding policies? Is there a threshold at which such change will become possible? How will you know when the threshold has been met?
- Has participation in a mass digitization effort reduced expenses in any area of local library operations? Examples: efficiencies in conversion/capture or post-processing; savings in personnel costs; increased use of remote storage; efficiencies in document delivery services
- What one thing do you wish you had known (or understood) before you "got in the game" of large-scale digitization?
- The most widely publicized mass digitization efforts are focused on conversion of monographic works, including widely held titles. How do you justify the community investment in improving access to works that are already so widely distributed?
- What do you need to know about how your local users (or other constituencies) are using the output of your mass digitization efforts?
- Most large-scale digitization efforts in the US have been massively subsidized by commercial interests. If no external funding had been available to support your participation, would you have made different decisions about (e.g.) what materials to convert, or the specifications for capture or handling of materials?
- What is the most significant compromise your institution has made in order to make mass digitization possible? Are you comfortable with the consequences of your initial decisions?
- In deciding to enter into a mass digitization arrangement, how did your institution weigh community or public interests and local needs?
- Have you made your existing digital content available for re-aggregation or redistribution?
- Do you expect (or need) your current partners to ensure the persistence of aggregate digital collections to which you've contributed?
"Mass Digitization: Building a digital Library of Alexandria or a White Elephant?" Stuart Dempster, Joint Information Systems Committee (JISC). PRESENTATION
Like any construction project, mass digitisation should be a means to deliver a well designed, durable structure that meets the needs of its users and is fit for purpose. And just as some construction projects run late, are poorly planned, use poor quality materials and do no meet the needs of either of their backers and users, so too can mass digitisation fail to meet expectations.
The Joint Information Systems Committee (JISC) has invested £16 million since 2003 on mass digitisation. It builds upon work of the Distributed National Electronic Resource including HEDS and TASI .In the UK context a multitude of public bodies have a role or take a view on mass digitisation in the UK with none fully able to take a UK-wide overview. The challenges raised by the not-for-profit and for-profit mass digitisation prompted the JISC and the Consortium of Research Libraries (CURL) to commission a Study and Report into the state of digitisation across the UK research libraries and archives. The Loughborough Study as it became known discovered deep fragmentation in all areas of the digitisation infrastructure. These shortcomings beg the question is mass digitisation building a digital Library of Alexandria or a white elephant? In order to mitigate the enormous challenges of mass digitisation the JISC has allocated funding to address one of the primary recommendations of the Loughborough Study through the establishment of a UK e-content framework.
10:30a.m. – 11:00a.m. Break (Rostrum, Main Lobby Level)
11:00a.m. – 12:30 p.m.
Session 11: MBooks: Google Books Online at the University of Michigan Library. (Grand Ballroom, Main Lobby Level)
Phil Farber, Chris Powell, and Cory Snavely, University of Michigan. PRESENTATION
The digitization partnership between the University of Michigan Library and Google has recently taken on a new public face with the launch of MBooks, the online delivery system that was developed specifically for the Michigan materials digitized by Google. MBooks uses the online catalog, Mirlyn, as the discovery system, and links to a page-turner accessing digital objects in a new repository. This completely automated system has provided new opportunities for collaboration between Core Services, Digital Library Production Service, and Systems Office staff.
This presentation will describe the various units and processes involved in making these books available online at Michigan. Panelists will provide an overview of MBooks; describe the workflow for retrieving the books, validating the incoming files, and assembling them in a METS wrapper for use in the online system; explain the process of creating links from Mirlyn to the pageturner application; describe the pageturner and its interaction with Mirlyn, the search engine, and the rights database created for this material; and discuss the current usage trends and possible future directions.
Session 12: Preservation Repositories and OAIS. (Ballroom Foyer, Main Lobby Level)
"Expanding the CDL Digital Preservation Repository for New Projects." Stuart Sugarman,Shifra Pride Raffel, Mark Reyes, and David Loy, California Digital Library. PRESENTATION
This paper will describe the integration of two new services, the Open Content Alliance services and the NDIIPP Web-at-Risk Web Archiving Service, with the California Digital Library's existing Digital Preservation Repository. Emphasis will be on technical decisions, technical details of implementation, and the use made of both our own and others' software. For both projects, the process of integration is ongoing; both will have had at least limited release and use by the time of paper submission. For OCA, the decision was made to develop two new services, tracker and feeder, that would allow the exposure of work flow from book to preservation. The tracker service provides up-to-the-moment status for the manual processes of scanning, QA, and submission for preservation. The feeder service identifies digital objects for preservation, dynamically creates and submits METS records for ingest, and monitors the ingest process. Both services will be discussed. For the web archiving project, a somewhat novel data model has been constructed that postulates an object which is composed of the archival and other files associated with an entire crawl. Metadata, preservation and other decisions that stem from this data model will be discussed. The use of IA's Heritrix crawler will be briefly covered.
"Implementing OAIS Information Packages and Producer-Archive Agreements." Donald Sawyer, GSFC/NASA, and Louis Reich, CSC. PRESENTATION
In January 2002, Consultative Committee for Space Data Systems (CCSDS) officially published the Open Archival Information System Reference Model (OAIS RM) as CCSDS 650.0-B-1 and later ISO published it as ISO 14721:2003. Subsequently, CCSDS has been working on Information Packaging standards to meet the new requirements including use of the internet as the primary data transfer mechanism, leveraging the better understanding of long-term preservation from the OAIS RM, and incorporating XML as an emerging universal Data Description Language. A stable CCSDS Draft Recommendation, "XML Formatted Data Unit (XFDU) Structure and Construction Rules" and the XFDU Toolkit Library, a reference implementation consisting of a set of JAVA Libraries has been developed. CCSDS has also produced an ISO standard, the Producer-Archive Interface Methodology Abstract Standard (PAIMAS). It provides a model for negotiation between the Producer and the Archive. Currently CCSDS is to developing an implementable mechanism for the formal model that describes the organization of data to be delivered to an archive, and it must work with a standard delivery package structure, the XFDU standard, to act as a SIP for delivery of the data.
NASA, in partnership with the NARA ERA research program, is performing research into advanced information encapsulation, information models and procedures, and highly scalable ingest mechanisms based on the Open Archival Information System Reference Model (ISO 14721:2003) and the emerging XDFU technologies. This research is in support of NASA requirements in the packaging of large digital datasets and ancillary data and NARA's requirements to provide the American public with access to federal, presidential, and congressional electronic records collections. It applies the emerging standards to NASA and NARA specific data and ingest requirements to determine the utility of the draft standards and to illuminate both technical and operational issues. In this presentation we will describe the results of the early phases of this research and the status of current ongoing efforts including:
- the impact of XML schema versioning and extensibility mechanisms
- the performance and scalability of the XFDU Toolkit library both in packaging and validation
- the usability of the XFDU data model for a range of disciplines and datatypes
- the prototyping of the Producer Archive Interface Standard (PAIS) Submission Information Package (SIP) using the XFDU Toolkit Libraries
"A DSpace-based Preservation Repository Design." Joseph G. Pawletko and Ekaterina Pechekhonova, New York University. PRESENTATION
At NYU's Digital Library we are building a Digital Preservation
Repository (PR) that uses DSpace as a core component. During the system
design phase we were faced with the question "Should we build a
monolithic application that does everything, or distribute the
preservation functionality over a collection of components?" We decided
upon the latter approach. In this talk we will discuss why we chose the
component approach; the DSpace features and add-ons that enable us to
use DSpace as a component; the role DSpace plays in the overall PR
architecture, other components and implementation technologies used in
the PR (Java, Ruby, SRW/U, XML-RPC, Shibboleth, the Handle System, METS,
MARC/XML, LC-AV, and others); the current system development status; and
future plans.
12:30 p.m. Adjourn


{kind=link}