|
1
|
- Thorsten Schwander, Herbert Van de Sompel
- Los Alamos National Laboratory, Research Library
- Digital Library Research & Prototyping Team
|
|
2
|
- Union Catalogues
- FRBR-izing catalogues
- MetaSearch engines
|
|
3
|
- LANL Research Library locally hosts a large data collection
- A&I databases: ISI Citation Databases, Inspec, BIOSIS, Engineering
Index, …
- Full-text collections: Elsevier, Wiley, APS, IOP, …
- Duplicates in LANL data collection:
- amongst bibliographic records
- between bibliographic records
and citations
- amongst citations
- De-duplication need:
- join records from several databases that describe the same work
- find works that cite a given work
|
|
4
|
|
|
5
|
|
|
6
|
- Strategy:
- Batch processing
- Bibliographic key matching
- Complex heuristics
- Issues:
- Extensive processing time
- Scalability problem in light of growing data collection
- Revision of heuristics requires reprocessing of collection
- Explore alternative:
- On-the-fly de-duplication
- De-duplication approach that is appropriate for citation matching
- Flexibility regarding revision of matching approach
|
|
7
|
- Netrics in the literature:
- C. Lee Giles Steve Lawrence Kurt D. Bollacker. 1998. CiteSeer: an
automatic citation indexing system.
International Conference on Digital Libraries. Proceedings of
the third ACM conference on Digital libraries Pittsburgh, Pennsylvania.
Pages: 89 – 98. DOI 10.1145/276675.276685.
- C. Lee Giles Steve Lawrence Kurt D. Bollacker. 1999. Autonomous
Citation Matching. International Conference on Autonomous Agents.
Proceedings of the third annual conference on Autonomous Agents,
Seattle, Washington. Pages: 392 – 393. DOI 10.1145/301136.301255
- Peter N. Yianilos. 1993. Data structures and algorithms for nearest
neighbor search in general metric spaces. Symposium on Discrete
Algorithms. Proceedings of the fourth annual ACM-SIAM Symposium on
Discrete algorithms, Austin, Texas. Pages: 311 – 321.
- Various papers at http://www.netrics.com/products/prod_papers.shtml
|
|
8
|
- Netrics elevator pitch:
- Netrics technology is a set of scalable linear-time algorithms that
model the human notion of similarity in order to match related
information. Netrics algorithms compute optimal weighted bipartite
matching of letters and polygraphs. This bipartite matching approach
captures a more flexible, more "human" notion of similarity
than that provided by traditional approaches to inexact matching, such
as string edit-distance, dictionary/speller correction, automaton-based
methods, fuzzy search and probabilistic algorithms.
|
|
9
|
- Demonstration sites:
- First Things [search: epistemolology]
- Prints doc com [search: barnspouse]
- The Swiss Colony [search: hollowene]
- Oscar winning actors database
|
|
10
|
- Netrics properties:
- Forgiving with respect to errors in dataset
- Forgiving with respect to errors in query
- Compares strings like humans do
- Response can be optimized for specific datasets: machine-learning
module
- Performance scales well with growing dataset
- RAM-based index
|
|
11
|
|
|
12
|
|
|
13
|
|
|
14
|
|
|
15
|
|
|
16
|
|
|
17
|
|
|
18
|
|
|
19
|
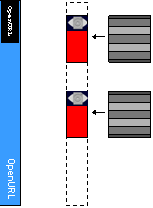
- Query:
- query key (citation or bib) sent
to broker: fielded search
- broker sends requests to all
appropriate processes
- thesaurus used for stitle
lookups
- broker collects/merges responses
- Response:
- list :
- key || likelihood that key is a hit || identifiers of records from
which key was extracted
- likelihood ~ Netrics match per
field & weight accorded per field
- client application decides on the cut-off point between hit and non-hit
|
|
20
|
|
|
21
|
- Optimize likelihood scores in function of the dataset
- Machine learning: create model that accords weights to fields of the key
- Librarians:
- Were presented with a total of 3,000 pairs of keys
- Had to decide whether or not both keys of a pair represented the same
work
- Result: clearer cut-off point between matches and non-matches
|
|
22
|
|
|
23
|
|
|
24
|
|
|
25
|
|
|
26
|
- Results look much better than those of batch de-duplication approach ~
Netrics matching + training by librarians
- Can ‘de-dup’ external data against local data
- No batch processing, but on-the-fly de-duplication
- Possibility to retrain the system to optimize responses without data
reprocessing: machine learning module
- Modularity of solution accommodates growth of dataset
- Netrics module can be used by multiple applications, not just one
- Positive collaboration with Netrics (machine learning, cache)
- Will be plugged into new search environment that is being created
- Will be applied to full-content collection
|
|
27
|
- LANL:
- Thorsten Schwander <schwander@lanl.gov>
- Herbert Van de Sompel <herbertv@lanl.gov>
- Netrics:
- Stefanos Damianakis <snd@netrics.com>
- Anthony Faulise <af@netrics.com>
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
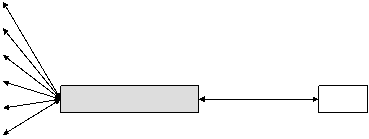{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}